DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
1. Scaling LLMs: The Computational Dilemma
The push to scale language models has yielded a remarkably consistent empirical observation: larger models, trained on more data, produce better performance across a wide range of tasks. This relationship, famously captured by scaling laws, sparked a race toward models with hundreds of billions or even trillions of parameters. However, one does not simply add parameters for free. In a dense Transformer, every parameter must be touched on every forward pass, so the computational cost per token grows in lockstep with the total parameter count. If we denote the number of layers by and the model dimension by , then both the parameter count and the approximate floating-point operations per token obey the same quadratic relationship:
The implication is brutal: pushing parameter count by an order of magnitude demands a corresponding tenfold increase in computation—and with it, tenfold increases in training time, energy, and monetary cost. The result is a computational dilemma where the very mechanism that promises better performance also erects an increasingly unscalable barrier.
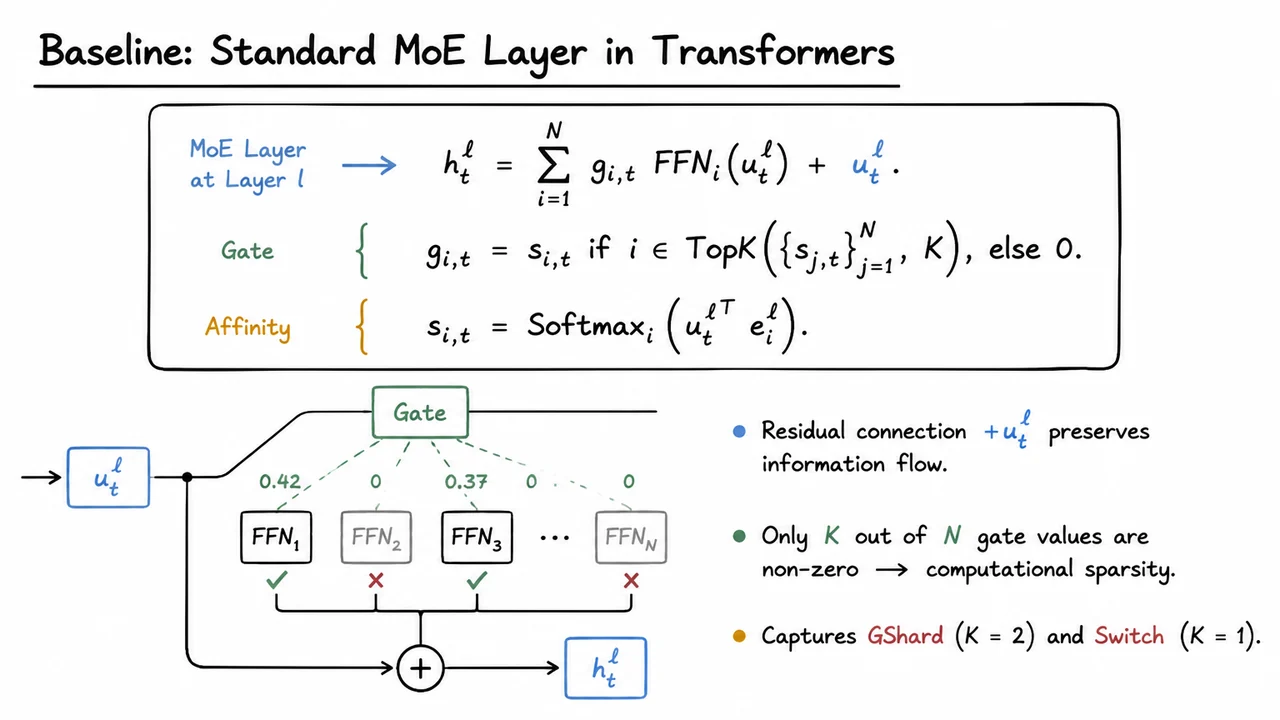
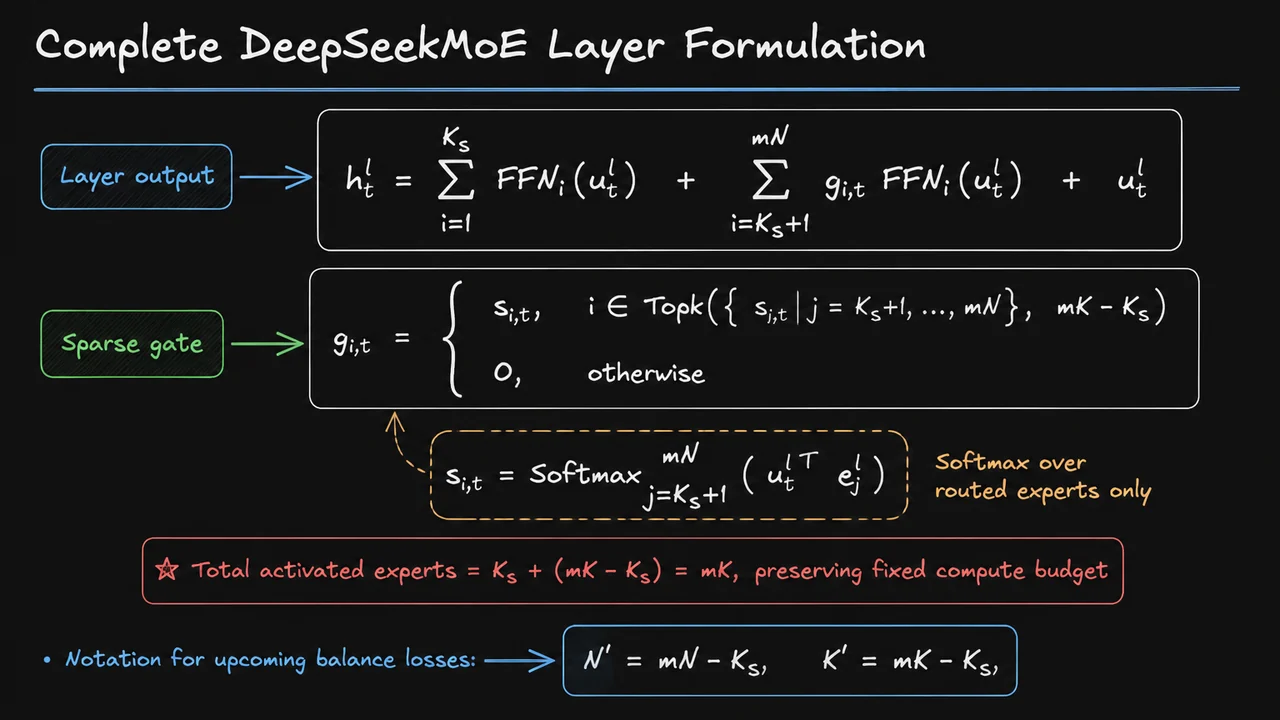
Mixture-of-Experts (MoE) architectures offer a conceptually elegant escape. Instead of activating every parameter for every input, an MoE layer replaces a single feed-forward block with a collection of expert sub-networks, each typically itself a feed-forward block of the same dimension . A learned router selects only a small subset of experts to process each token, where . The total parameter count of the model now scales with the number of experts:
whereas the per‑token compute scales only with the number of activated experts:
This decoupling is remarkable: we can inflate the model’s capacity by increasing while keeping the per‑example inference cost nearly constant. In principle, MoE turns the computational dilemma into a cheap parameter feast.
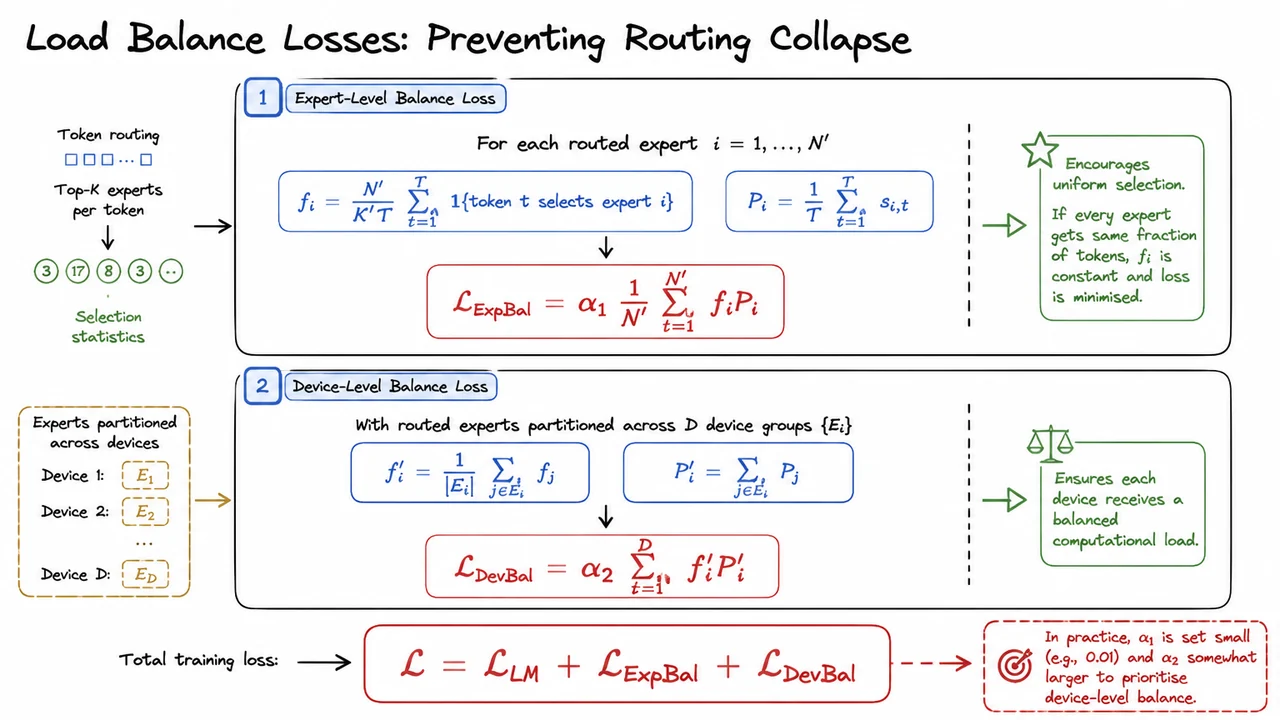
But reality introduces friction. Conventionally, MoE routing is implemented through a simple top‑ gating mechanism, as popularized by GShard’s top‑2 routing. Tokens are assigned to the experts whose learned gate scores are highest, typically with load‑balancing auxiliary losses to prevent the whole system from collapsing to a single all‑purpose expert. While this works better than a dense scratch at modest scales, it introduces two insidious problems that erode the very specialization MoE promises.
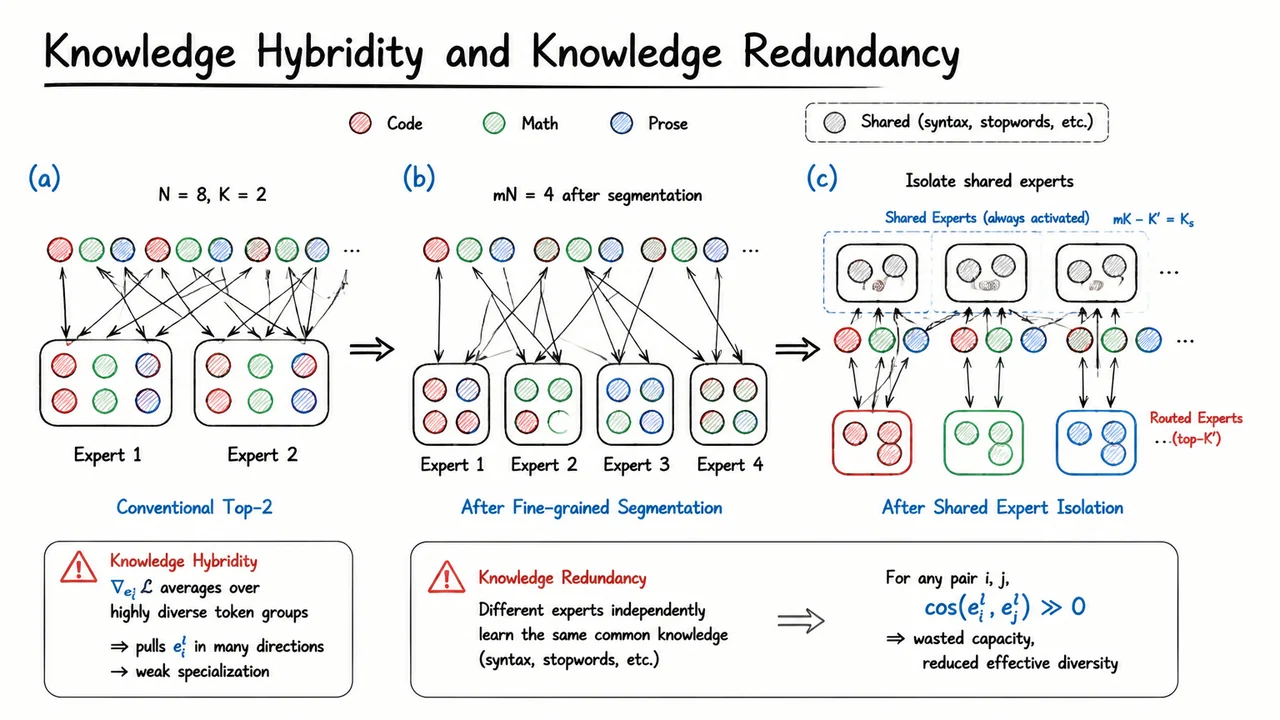
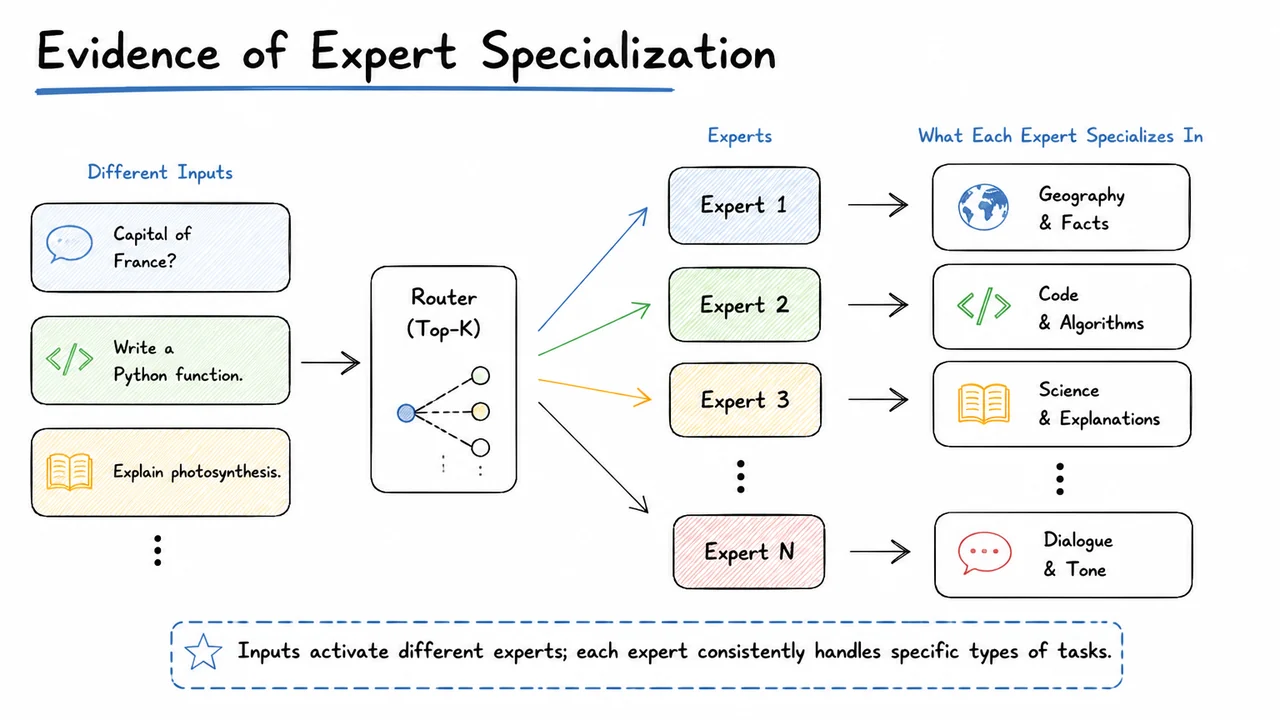
First, knowledge hybridity: tokens that are routed to the same expert often carry substantially different types of information. For example, an expert might receive tokens that require arithmetic reasoning, taxonomic facts, and literary style cues all at once. The expert is forced to encode a mélange of unrelated capabilities, preventing the clean, sharp expertise that would make each expert a true specialist. Instead of a collection of surgical instruments, we end up with a set of multi‑tools—functional, but rarely optimal for any one job.
Second, knowledge redundancy: different experts often learn to cover the same common knowledge base. Foundational syntactic patterns, frequent world knowledge, and generic language understanding end up duplicated across multiple experts. This duplication wastes precious parameters and, more subtly, confuses the router: if several experts all handle the same generic patterns equally well, the gating signal becomes less discriminative, and the system drifts back toward a dense‑like uniformity.
These two flaws together limit the effective capacity gains of conventional MoE. Instead of truly distinct specialists, we get a fuzzy, partially overlapping set of generalists, and the theoretical parameter‑to‑compute advantage is squandered on redundancy and under‑specialization. As model scale increases, these pathologies become even more pronounced because the sheer volume of tokens and the pressure to balance load push experts toward ever broader knowledge coverage.
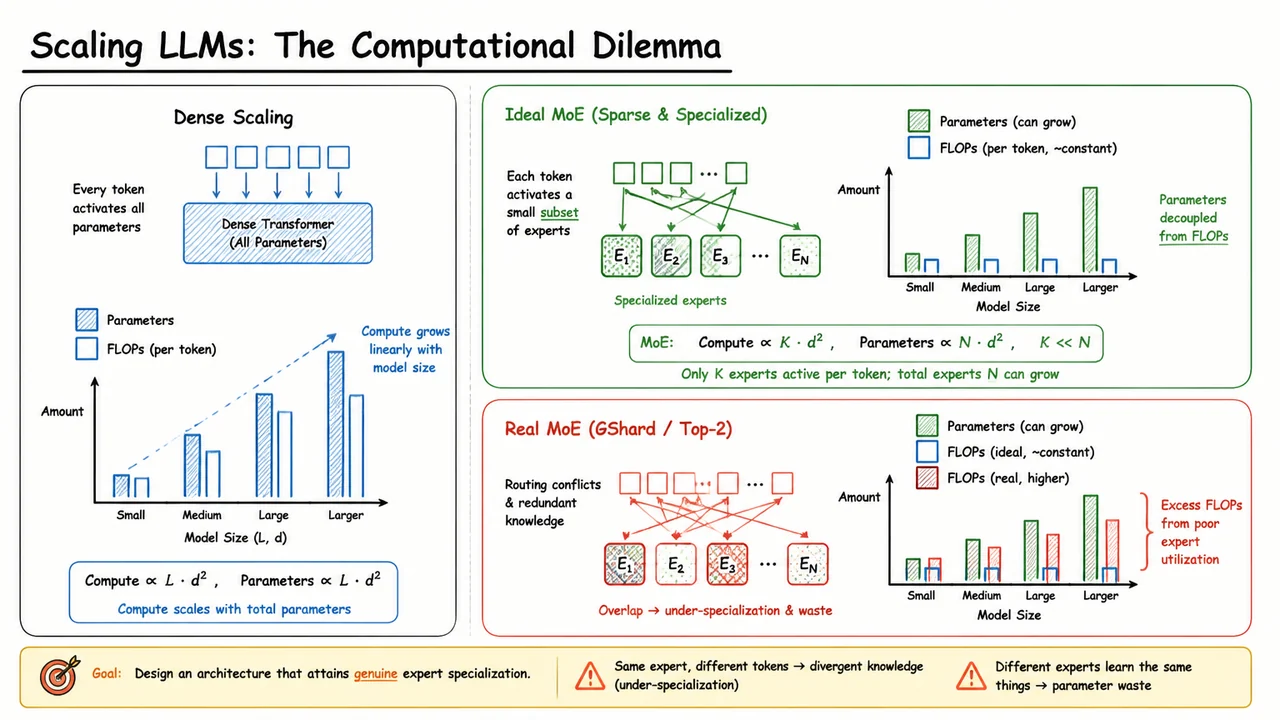
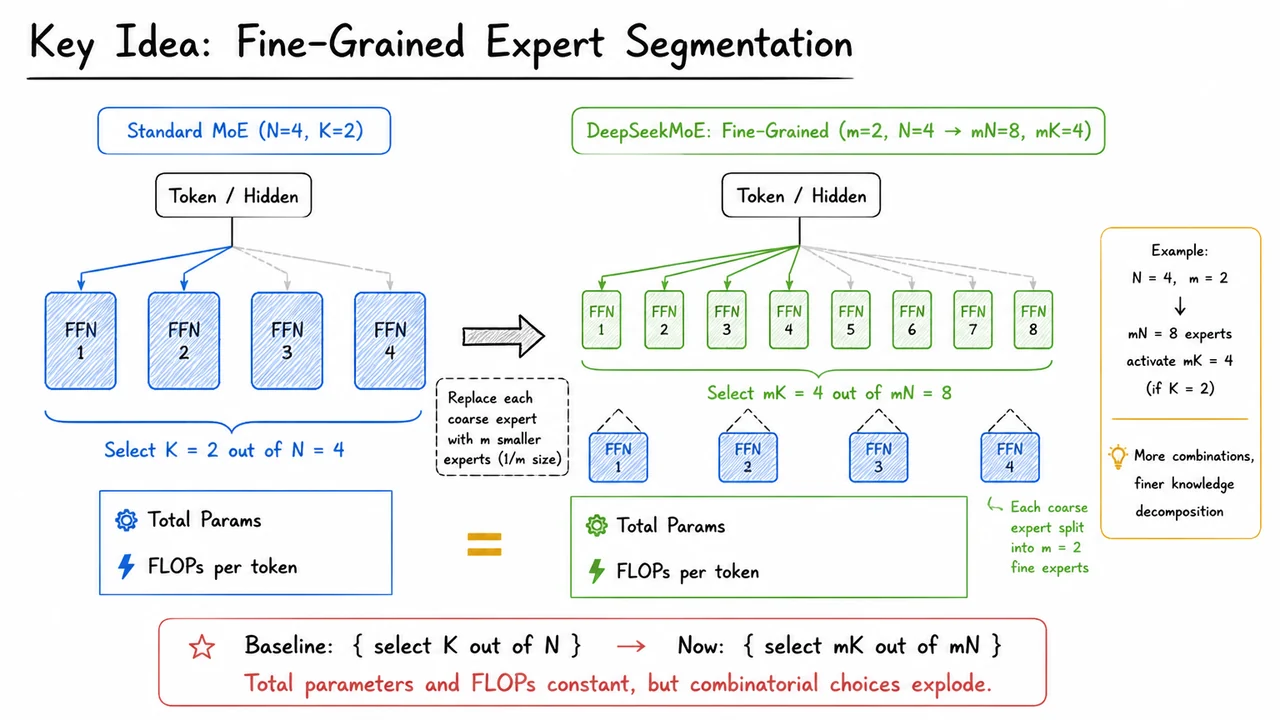
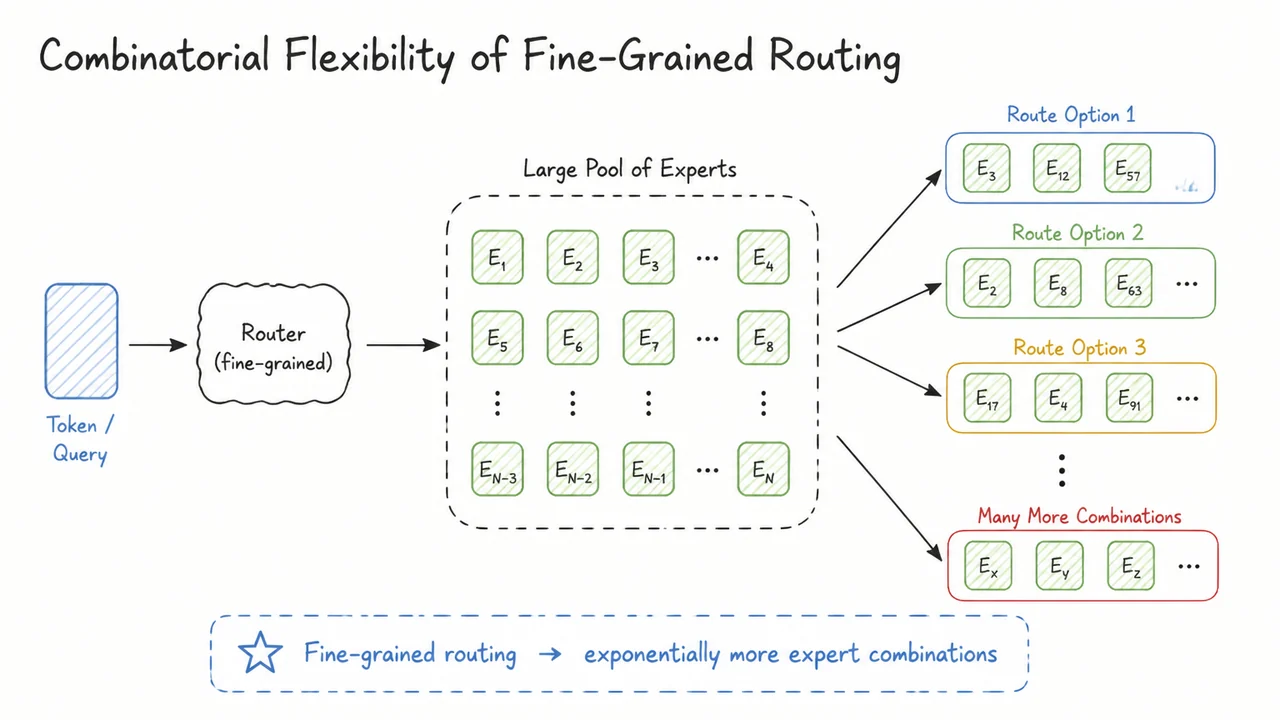
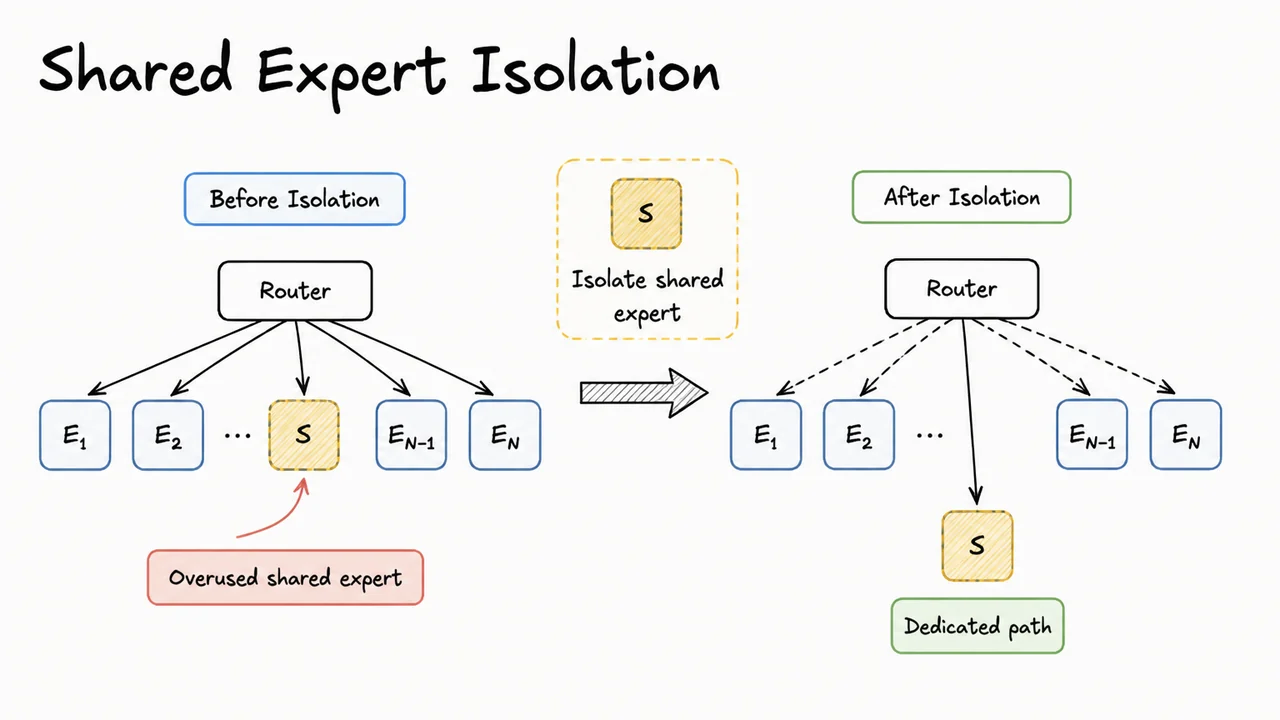
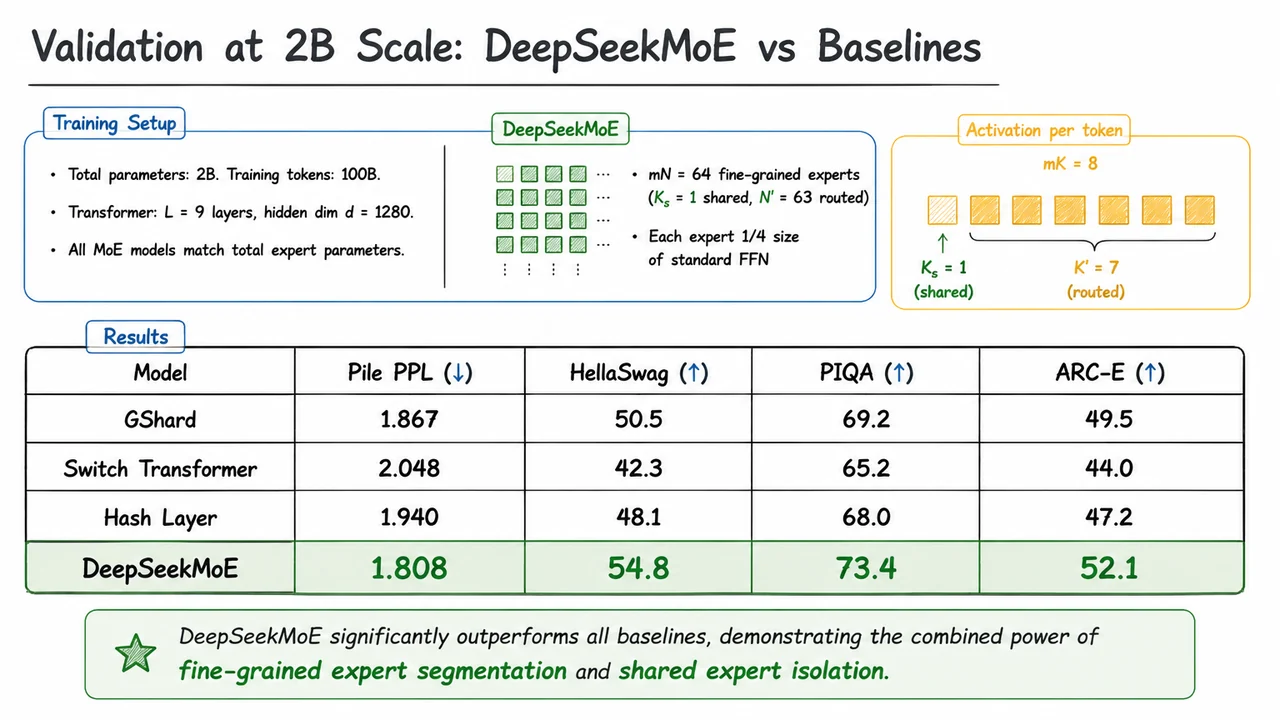
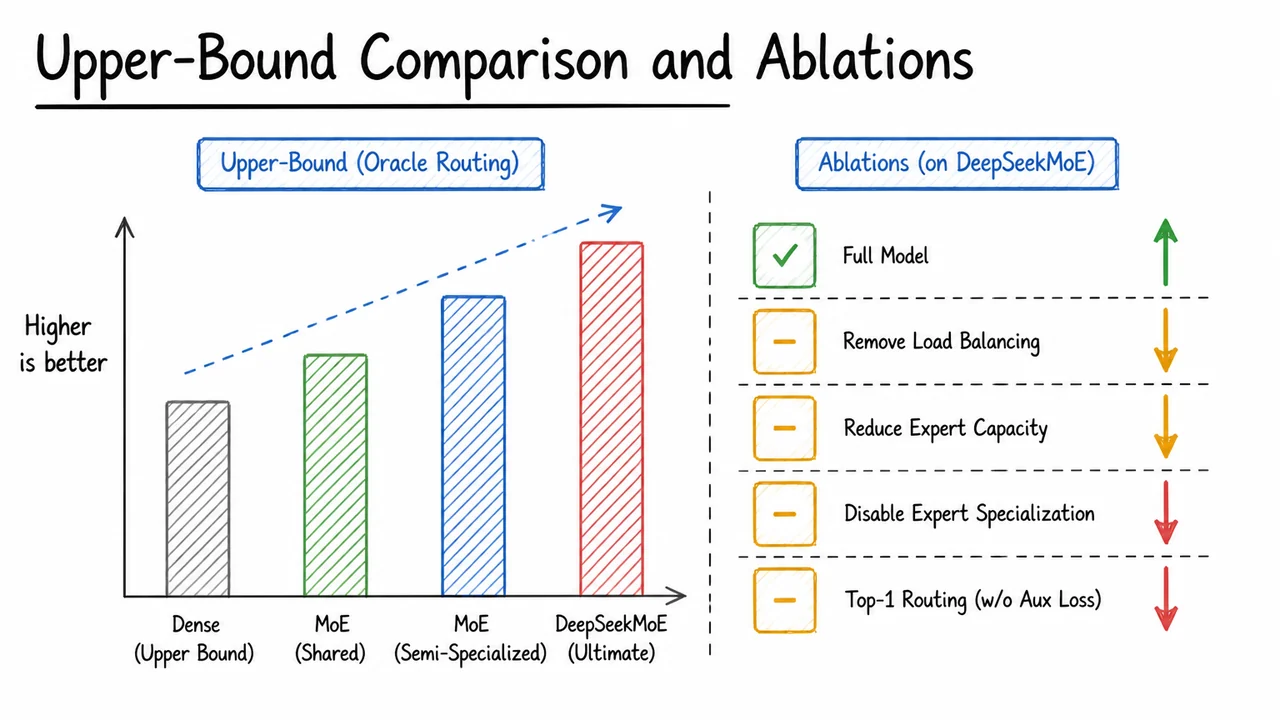
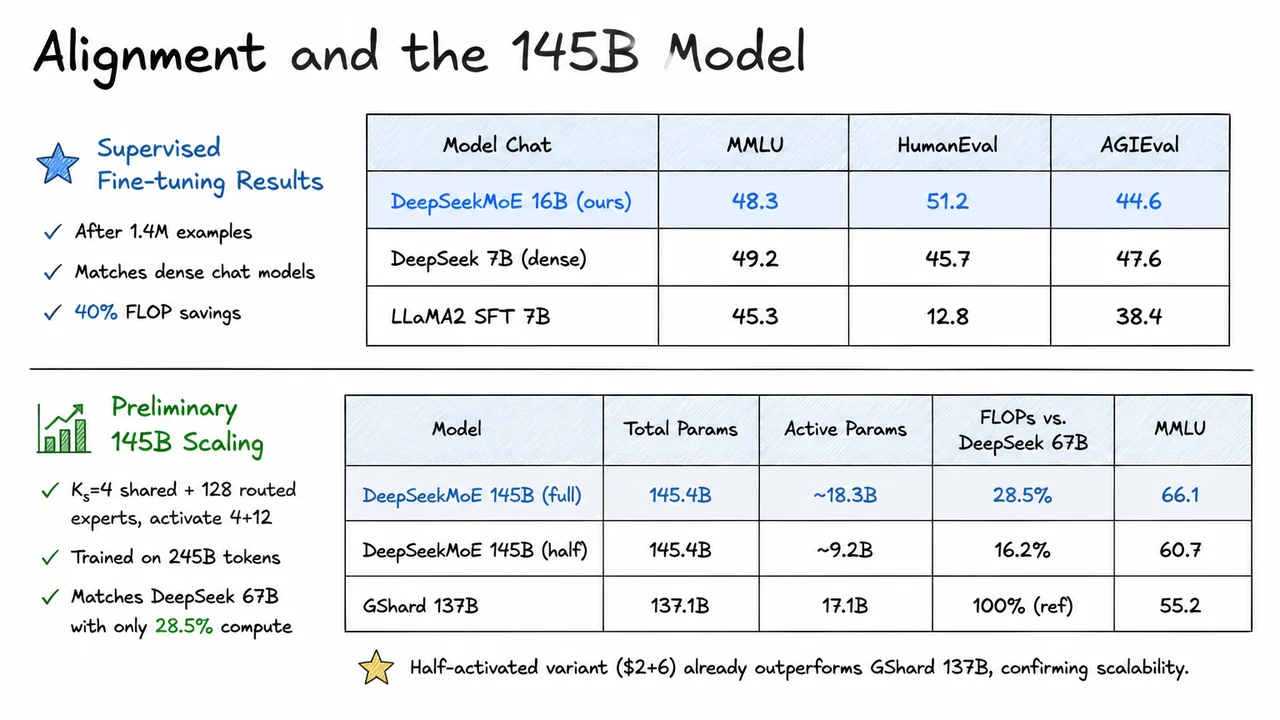
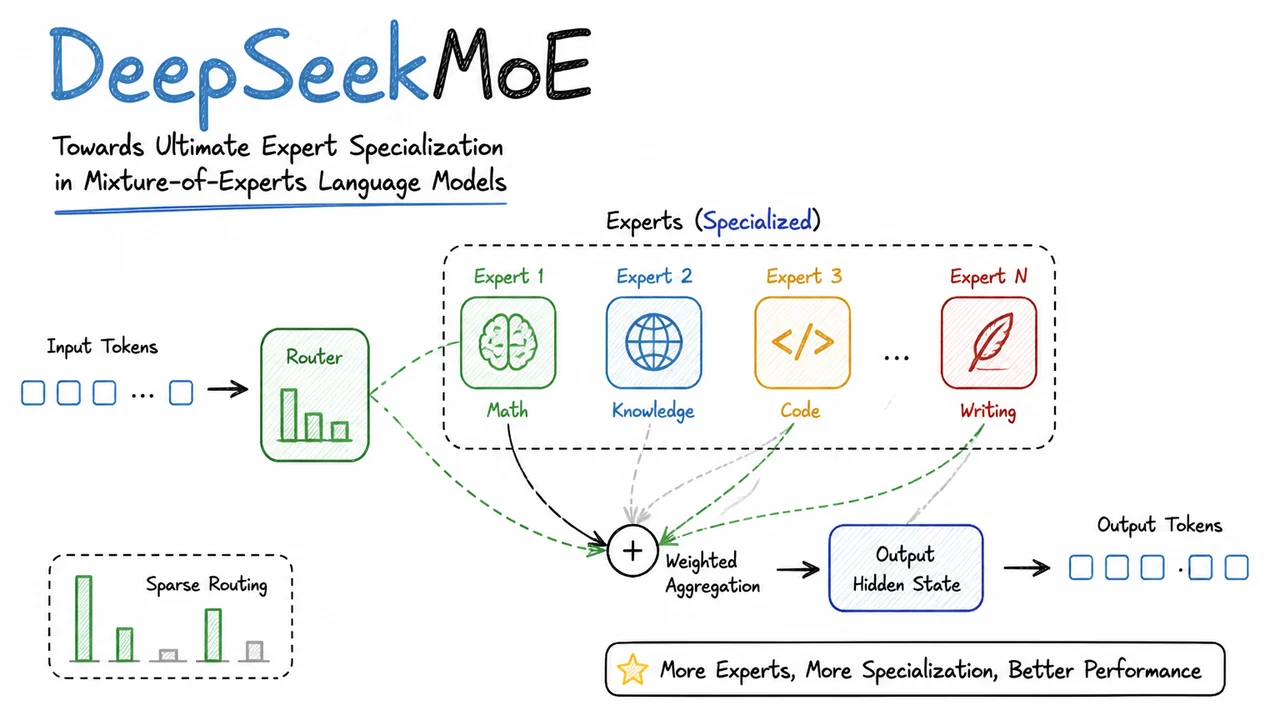
The core challenge, then, is not simply to sprinkle more experts into a Transformer, but to design an architecture that forces each expert to become a crisp, non‑redundant specialist—what DeepSeekMoE later terms ultimate expert specialization. The visual below encapsulates the arc of this problem. On the left, dense scaling is depicted as a linear growth of both parameters and compute, with the compute bar acting as a rigid ceiling on scale. On the right, an ideal MoE is shown: parameters can balloon while compute stays flat, and tokens are cleanly routed to distinct, color‑coded experts. The bottom‑right panel contrasts this ideal with real MoE routing: tokens scatter erratically, expert colors overlap, and the effective compute advantage shrinks, visualized as a red‑shaded efficiency gap. Together, these panels capture both the tantalizing promise of sparse models and the messy reality that DeepSeekMoE sets out to fix—not by discarding MoE, but by breaking experts into finer‑grained, forcibly specialized components and isolating shared knowledge into a dedicated set of common experts.