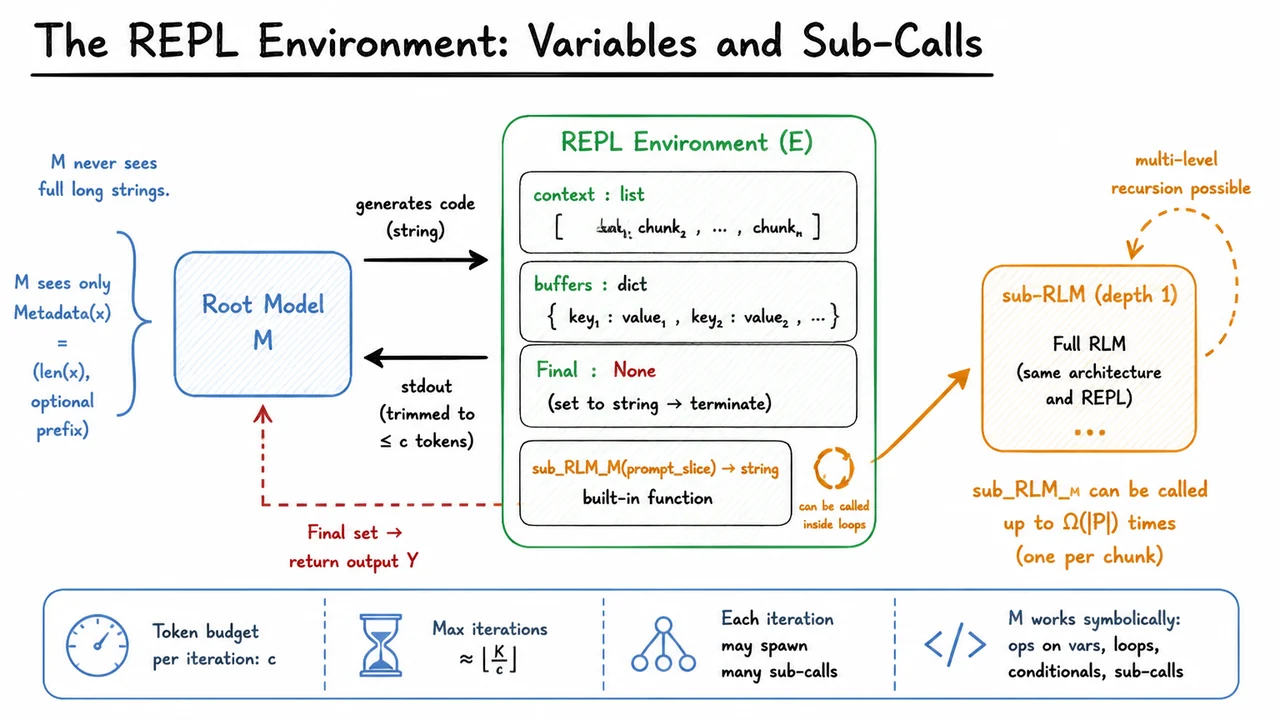
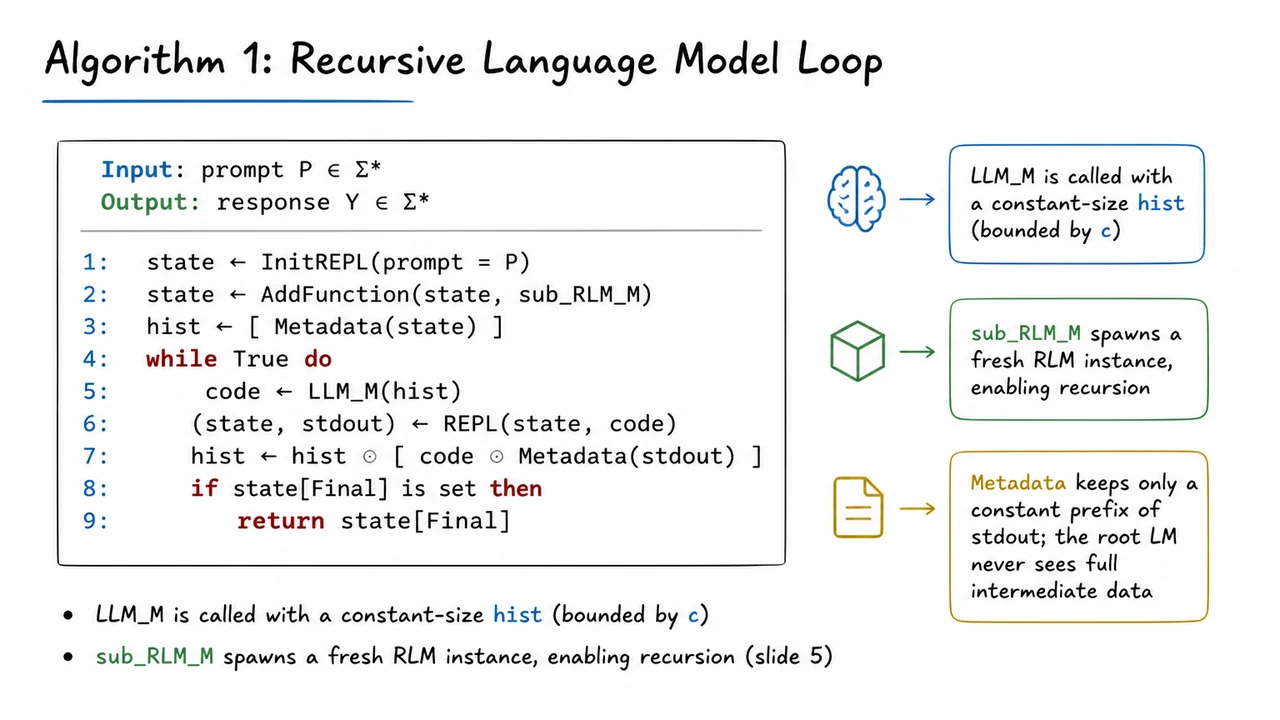
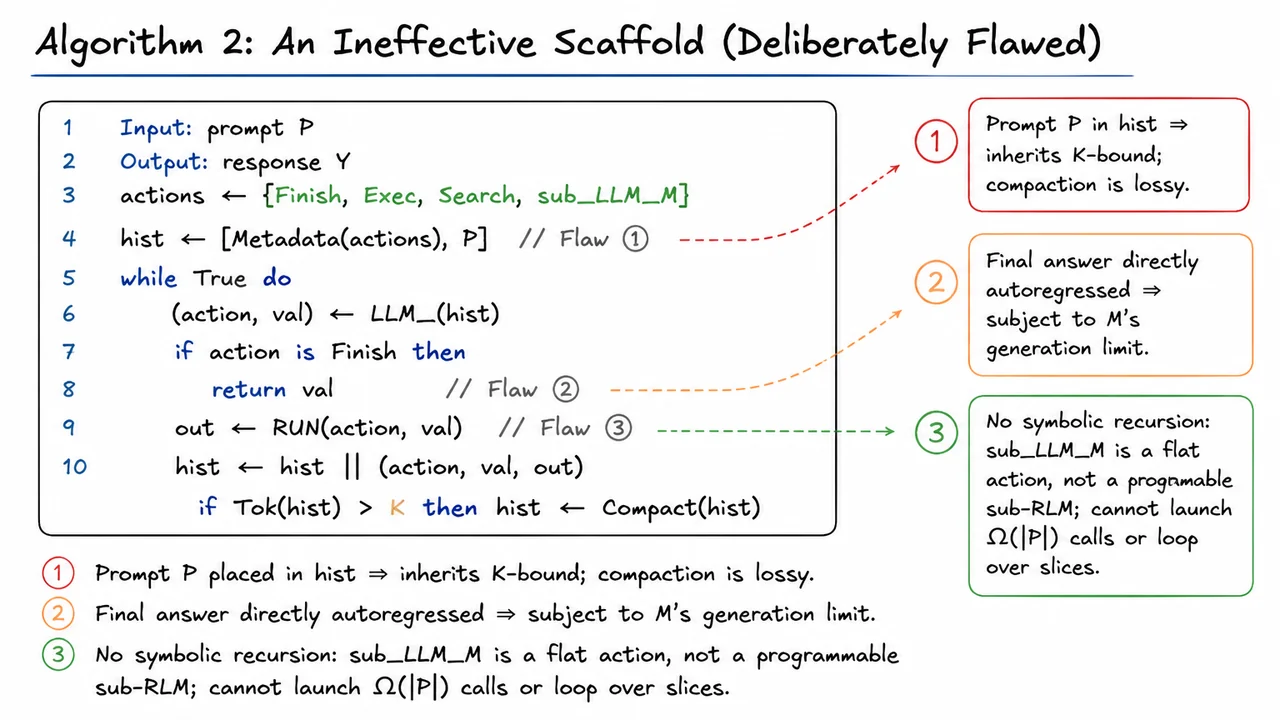
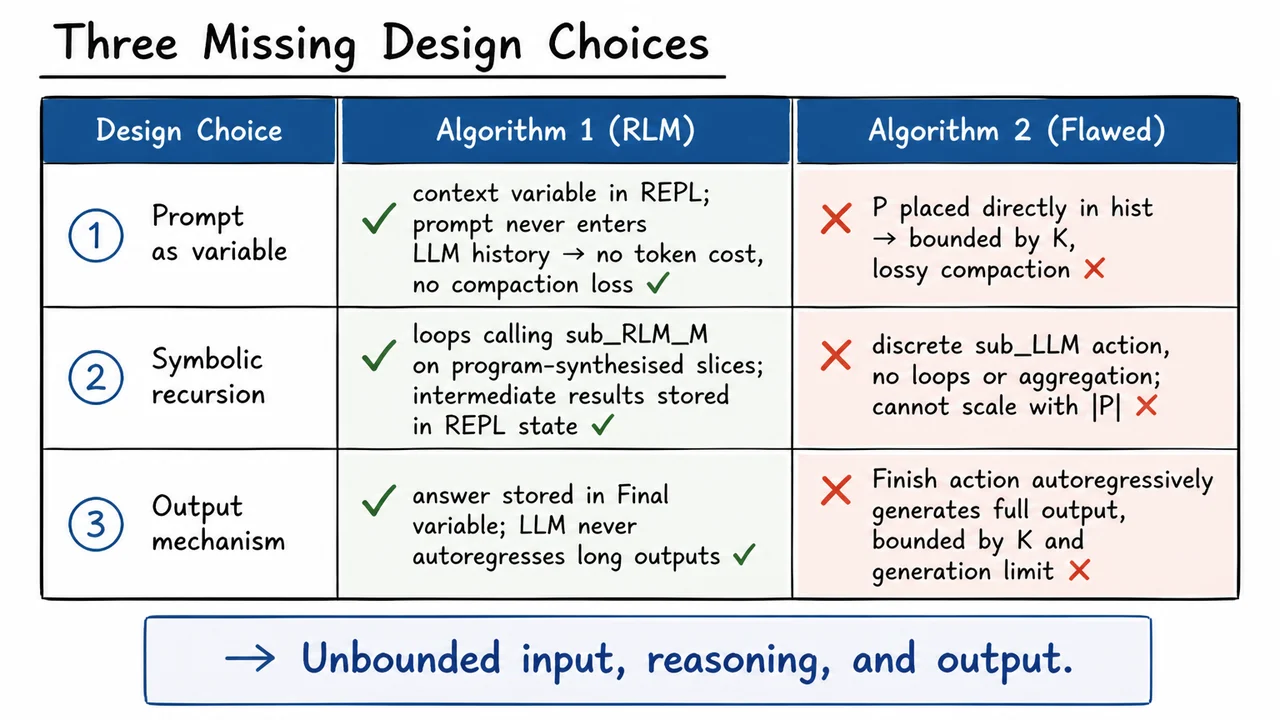
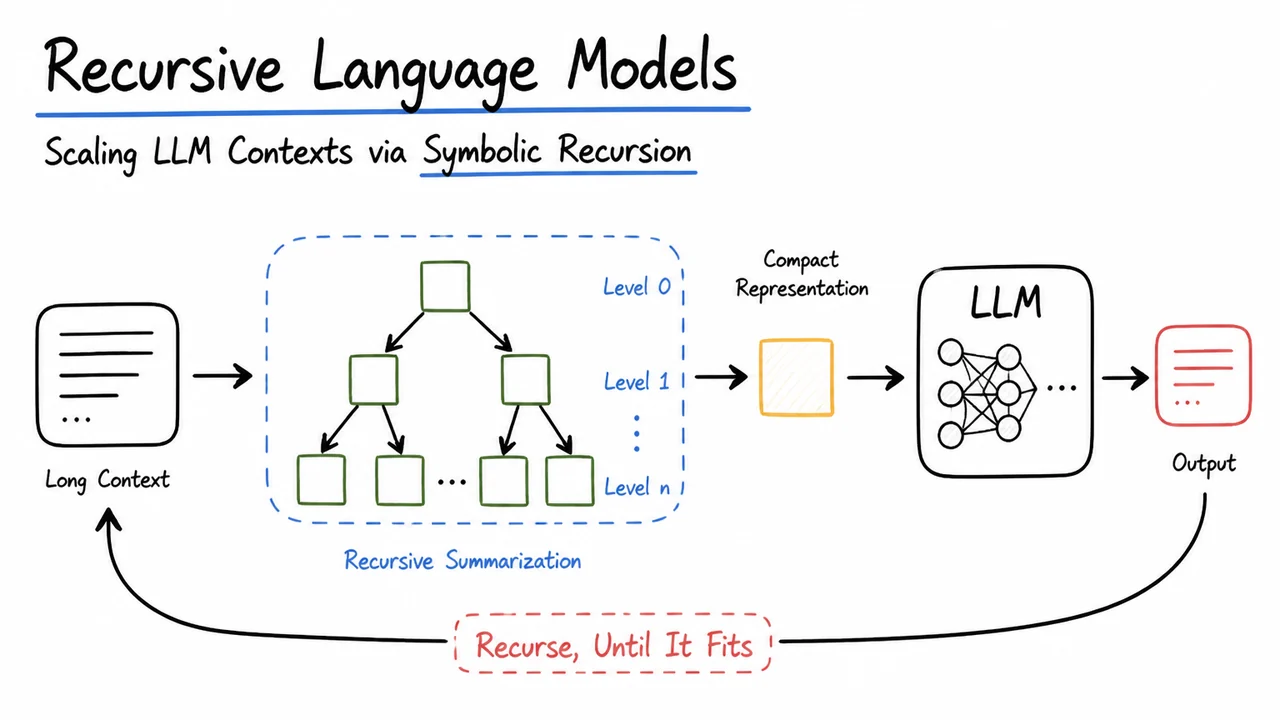
Recursive Language Models: Scaling LLM Contexts via Symbolic Recursion
1. The Long-Context Wall: Context Windows and Context Rot
The promise of large language models is, in large part, a promise about length. We dream of handing a model a full legal casebook, a complete software codebase, or the unedited transcript of a days-long meeting and having it reason across every detail without losing the thread. But step back from the demos that cherry‑pick short‑text tasks, and a stubborn reality emerges: today’s autoregressive transformers begin to break down exactly when contextual breadth matters most. This breakdown is not a single failure mode but two overlapping ones—a hard context wall and a soft context rot—that together define a practical ceiling for reliable long‑context reasoning.
First, consider the hard boundary. Every standard transformer‑based LLM is trained and deployed with a maximum sequence length—often 2k, 4k, 8k, or, in some recent scaling endeavors, 32k or 128k tokens. This number is dictated by the quadratic memory cost of self‑attention, by the positional encoding scheme, and by the inevitable cliffs in training where models simply never see longer spans. Tokens that fall outside this context window are discarded outright; the model has no vision of them, no matter how crucial they might be. In a generative setting, this means the prompt must be truncated—often arbitrarily—before inference even begins. The information beyond the cutoff is, quite literally, a void. This is the long‑context wall: a rigid, architectural ceiling that cannot be scaled away simply by adding more compute, because the hardware and algorithmic costs grow as with sequence length .
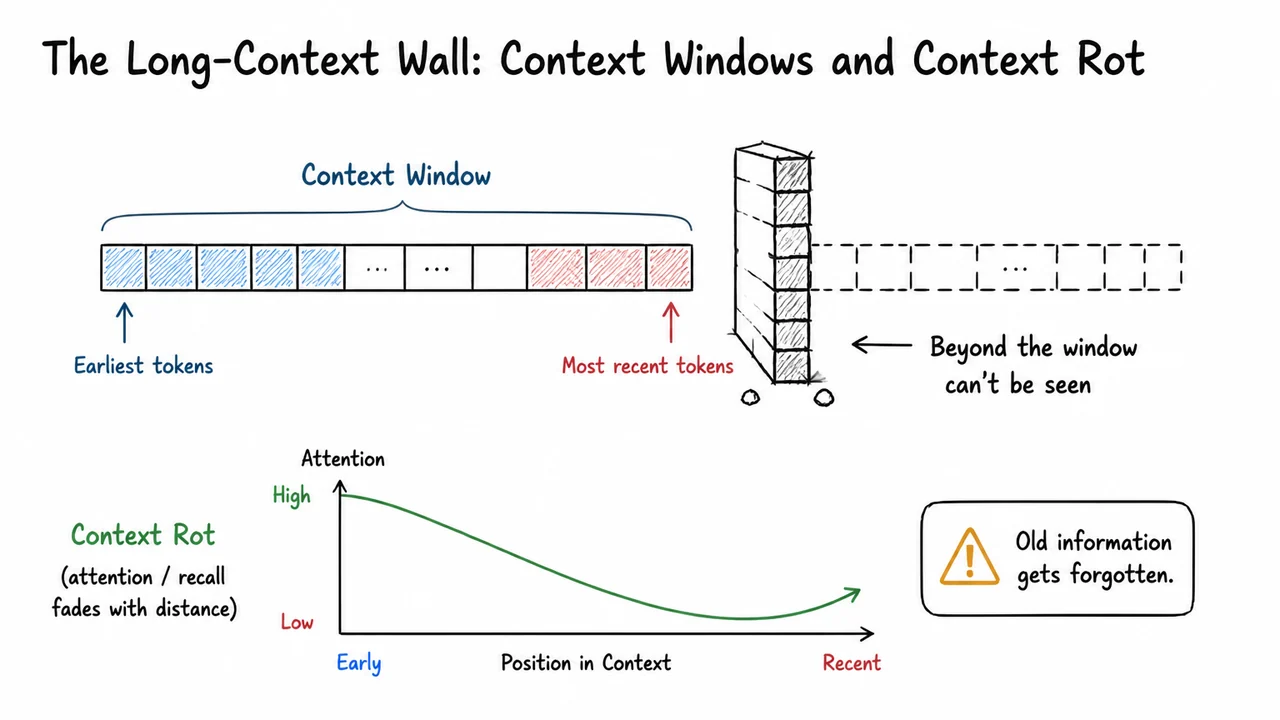
Yet even when a sequence fits comfortably inside the window, a quieter decay erodes the model’s effective grip on early information. This is context rot. Imagine feeding a model a 4k‑token historical narrative where a critical clue appears in the first paragraph. As the model generates the next 3,500 tokens, attention weights become diluted across thousands of intermediate positions; the softmax distribution over all keys forces every new query to spread its focus thinly. Early tokens, though technically still attended to, receive a vanishing fraction of the total attention mass. Empirically, this manifests as the “lost‑in‑the‑middle” phenomenon: given a list of facts, models recall the beginning and the end well, but the middle—and, more insidiously, the early facts in a long, later‑generated continuation—fades. The model might contradict itself, hallucinate replacements, or simply stop referencing the once‑salient detail. The semantic horizon—the longest distance over which a token can reliably influence a future prediction—is often far shorter than the nominal window size.
Why doesn’t the sheer capacity of attention heads prevent this? In principle, an attention head can assign high weight to a single early token even in a long sequence. In practice, however, the model has never trained on tasks that demand such sustained, pinpoint long‑range recall and simultaneously manage the dense, varied dependencies of natural language. The optimization landscape encourages efficient, local, slot‑based attention patterns; spikes to ancient tokens occur only when heavily reinforced, and they are fragile. Moreover, sine‑cosine or rotary position encodings tend to produce similarity scores that fade with relative distance, and even learned position embeddings often generalize poorly beyond the lengths seen at training time. The result is a gradual yet relentless erosion of signal integrity: a perfectly memorized detail becomes a dim, corrupted memory that downstream layers misinterpret.
This dual barrier—a hard wall that chops sequences and a soft rot that corrupts the early chunk—redefines what it means to understand a long document. When an LLM appears to track a plot across many pages, it is often relying on shallow, recency‑biased heuristics or on the statistical redundancy of the text, not on a faithful, end‑to‑end cognitive representation. Tasks that genuinely require integrating premises from the start and the end of a 10k‑token prompt—multi‑hop reasoning, long‑term planning, consistent character modeling—fall apart as the effective context length exceeds a few thousand tokens. The failures are not catastrophic in the sense of a hard error; they are insidious, producing plausible‑sounding nonsense that a careful reader would spot only by comparing the output to the original, now‑forgotten material.
The visual below, titled “The Long‑Context Wall: Context Windows and Context Rot”, consolidates this two‑part challenge in a single diagrammatic canvas. A long strip of tokens stretches from left to right; a translucent box marks the hard boundary of the context window, beyond which tokens become invisible. Inside the window, a gradient of color and fading arrows indicates how the effective relevance of early tokens decays even while they remain technically inside the visible region. The sketchy hand‑drawn aesthetic underscores that these are conceptual—and yet painfully empirical—limitations. The diagram makes tangible the intuition that scaling context is not just a matter of widening a rectangle: it demands a structural rethink that prevents the window from being both a cliff at the edge and a slope toward irrelevance on the inside.
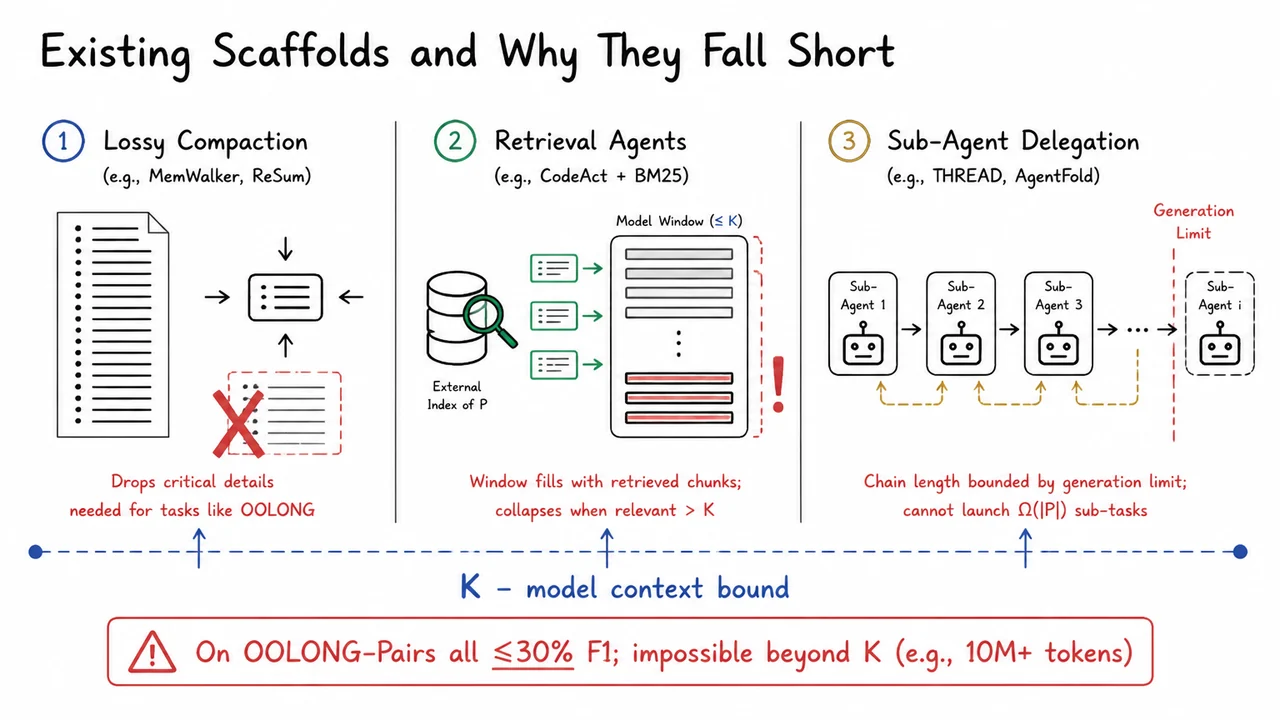
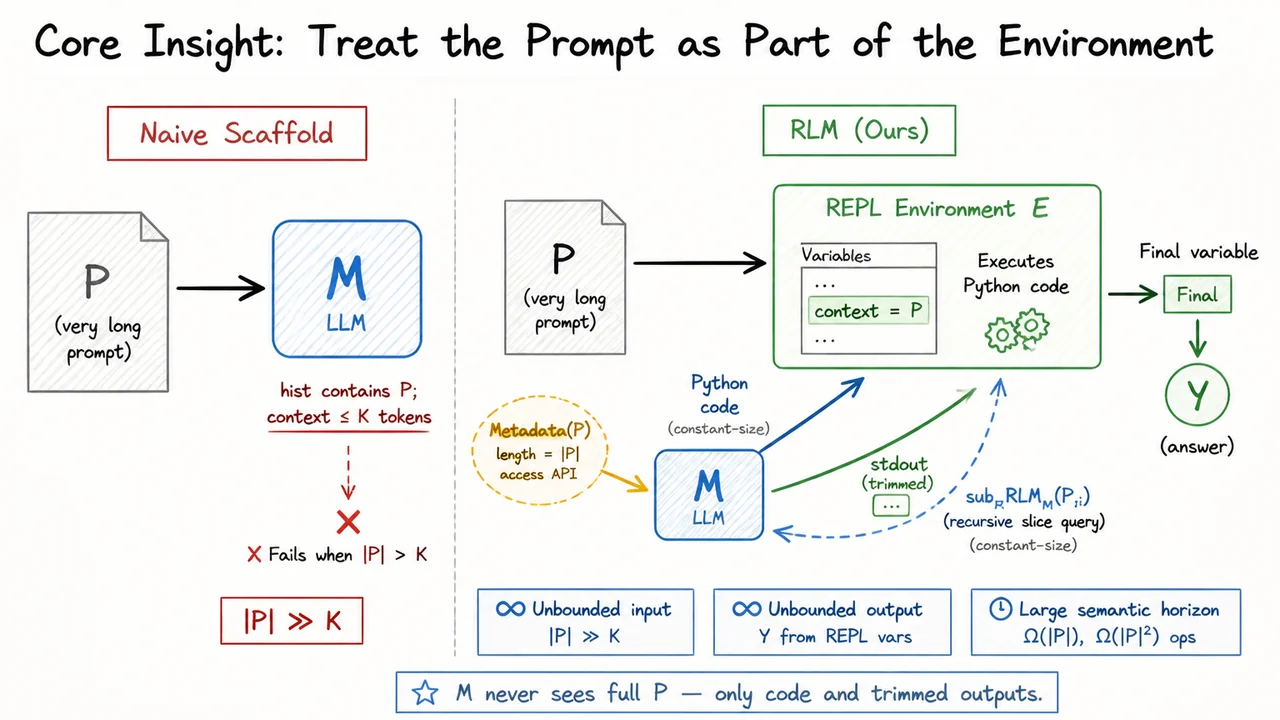
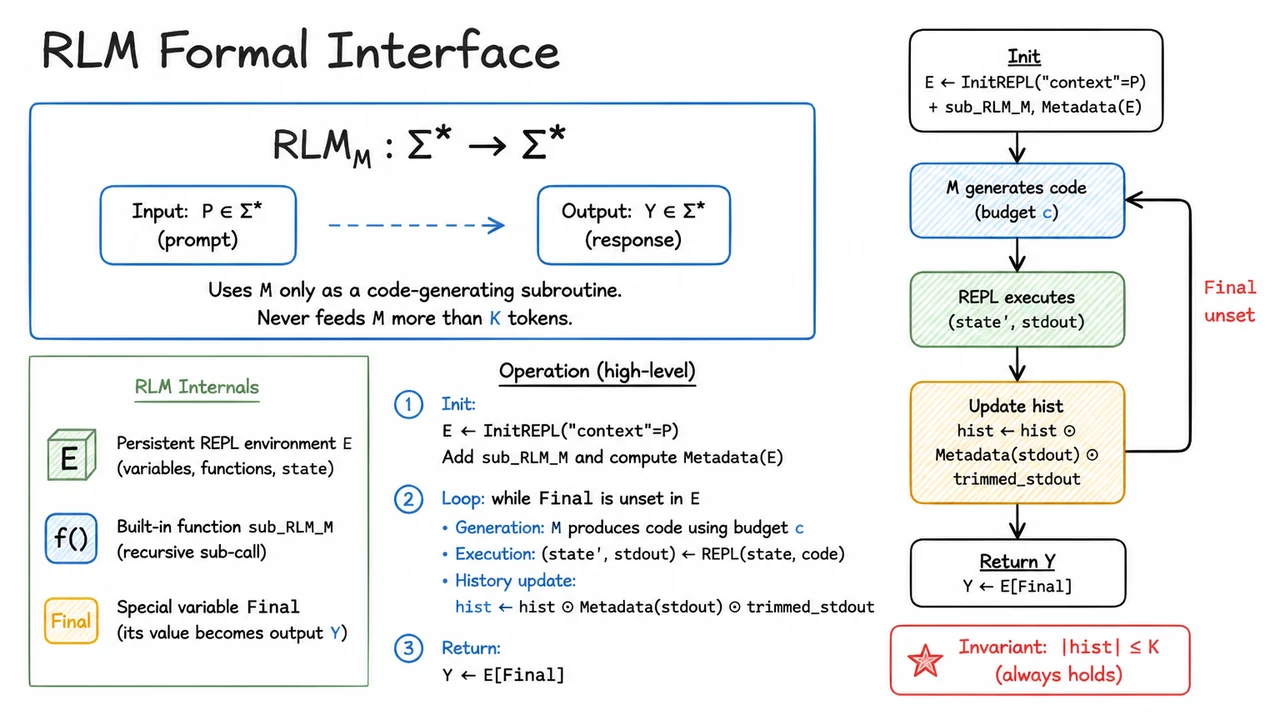
Understanding this wall is the necessary prelude to evaluating the common scaffolds—prompt chaining, retrieval‑augmented generation, and memory buffers—that attempt to patch over it. Those approaches, as we will see next, address the hard cutoff but leave the deeper problem of context rot largely untouched. And that insight is what motivates the search for a genuinely recursive language model, one that does not just remember longer, but remembers strongly across arbitrarily far separations.