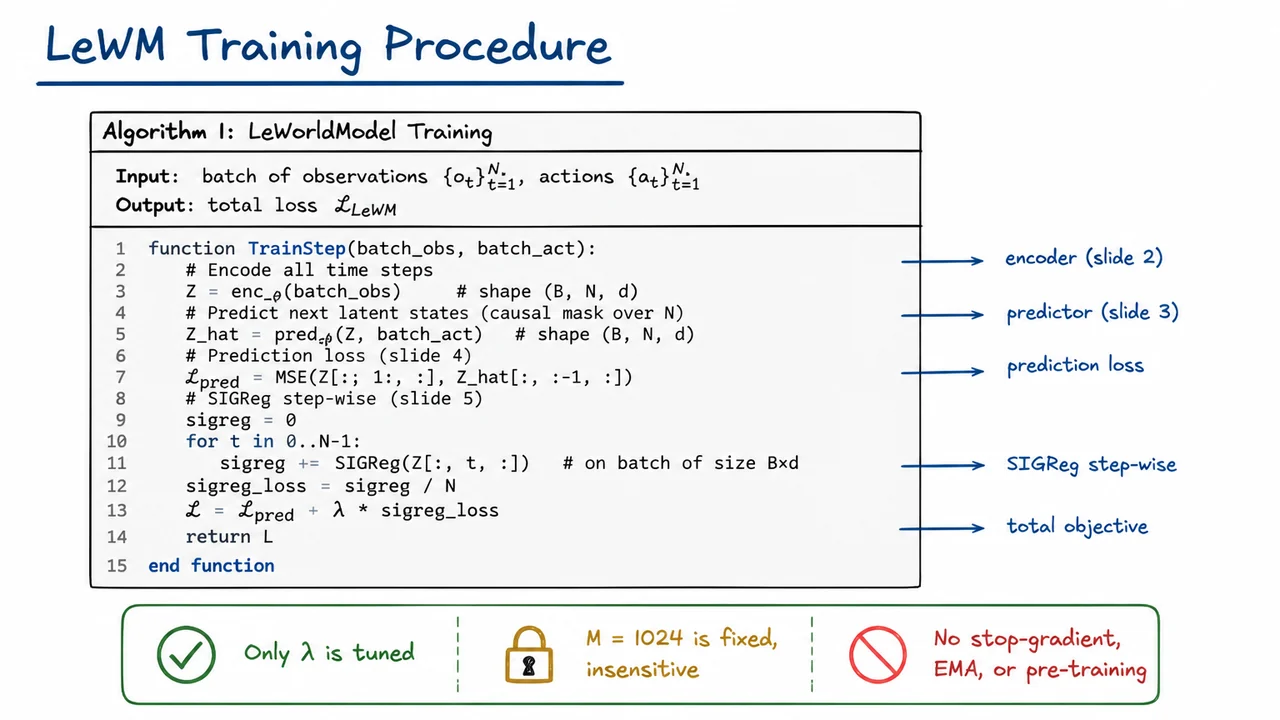
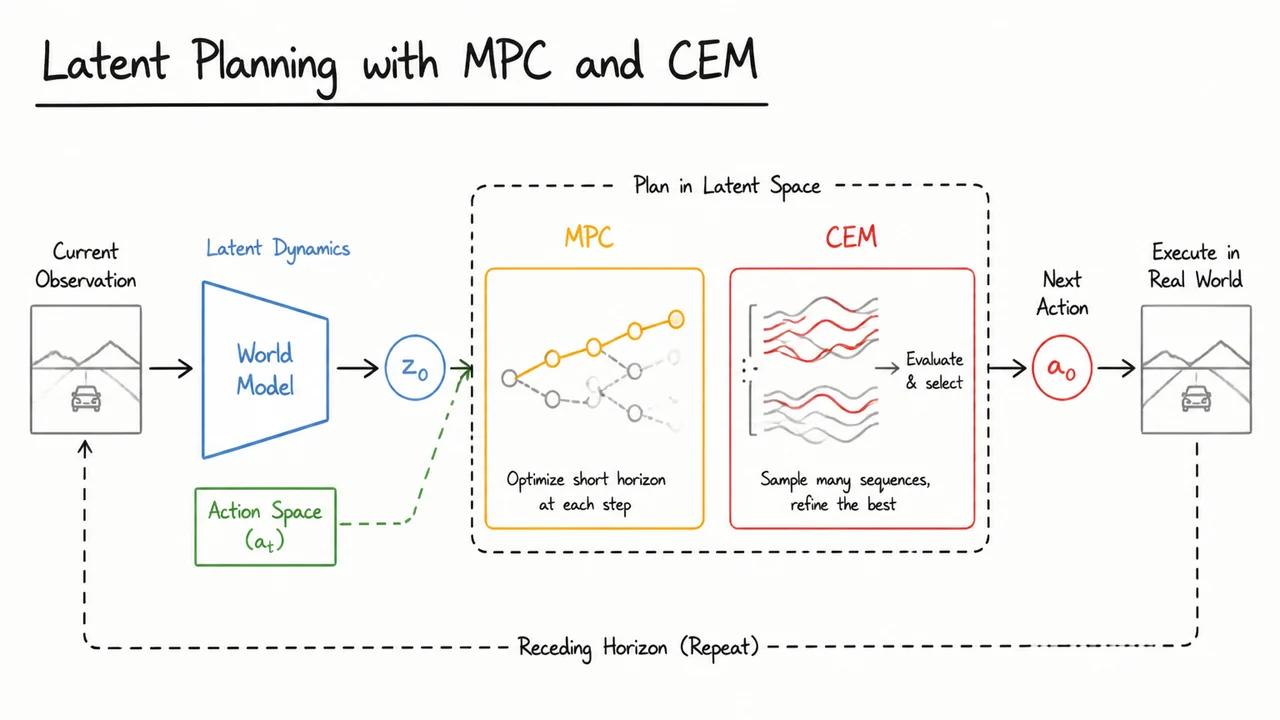
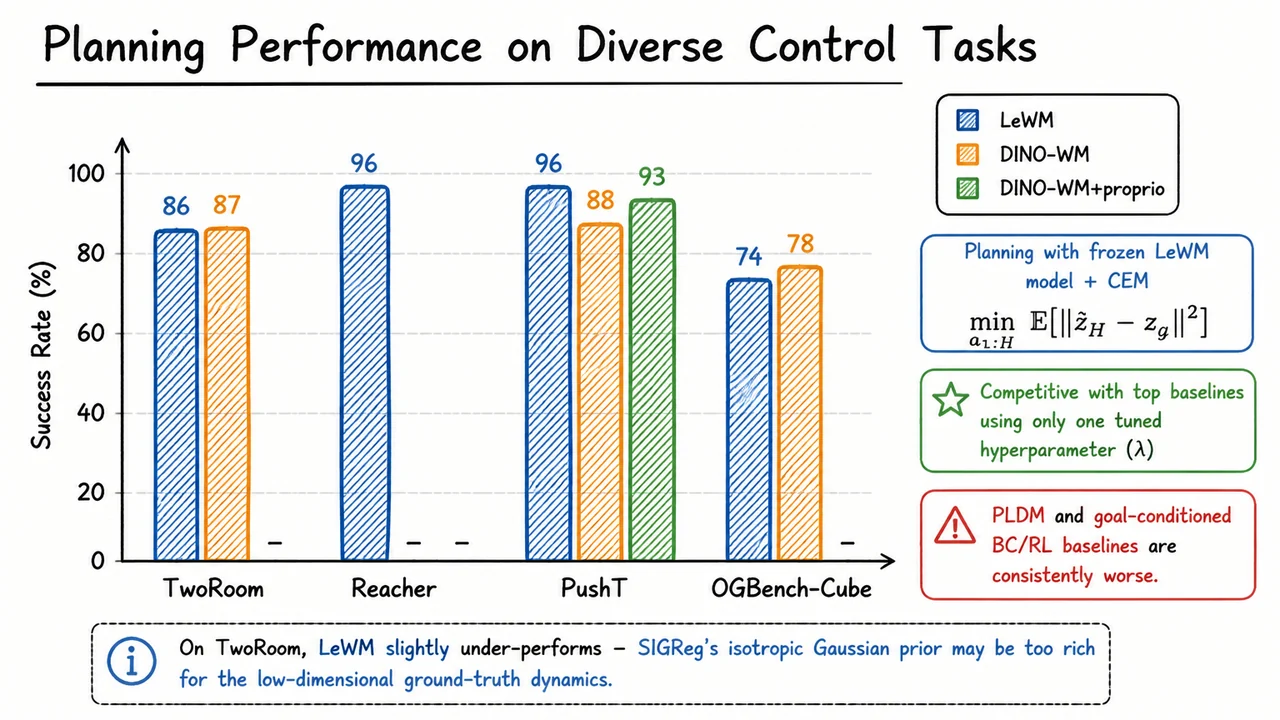
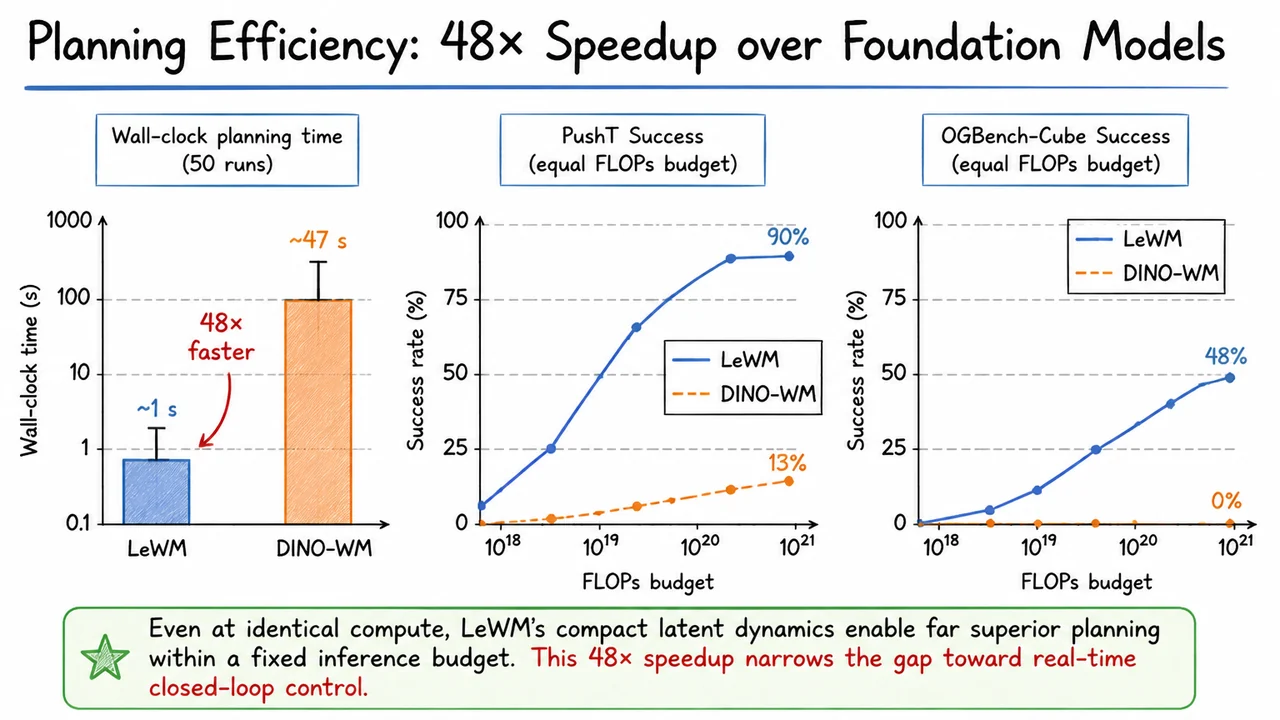
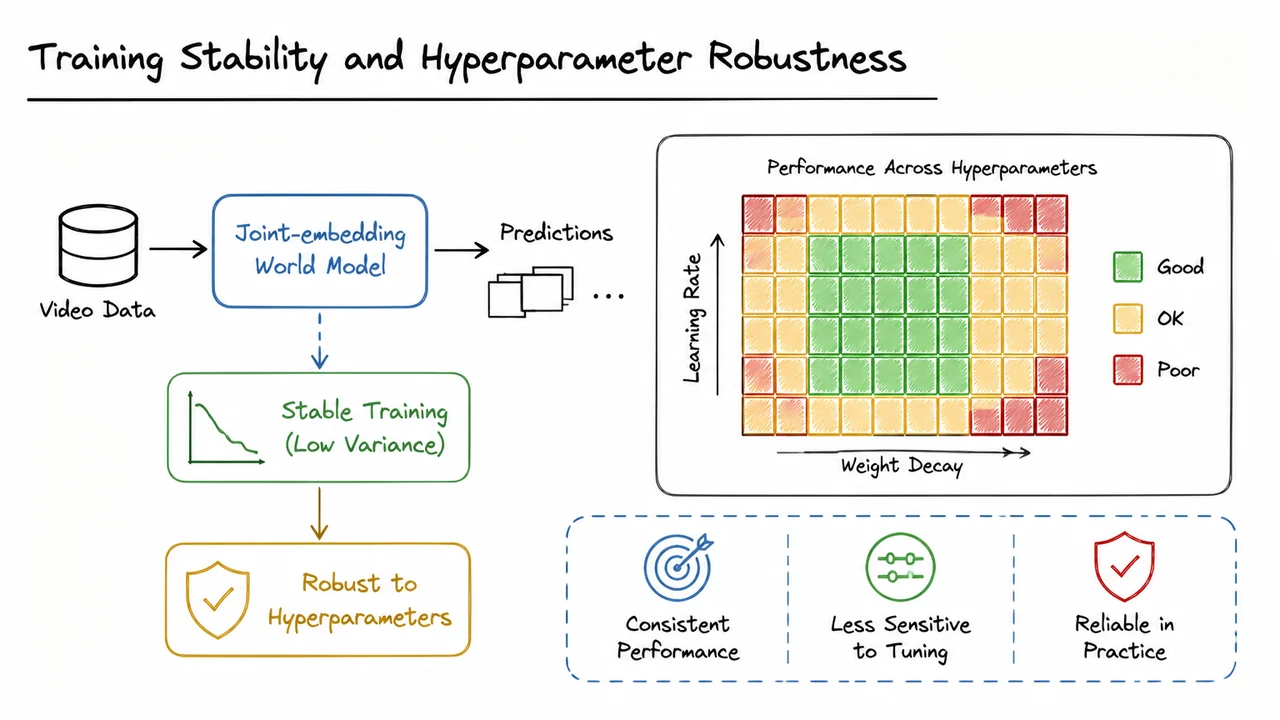
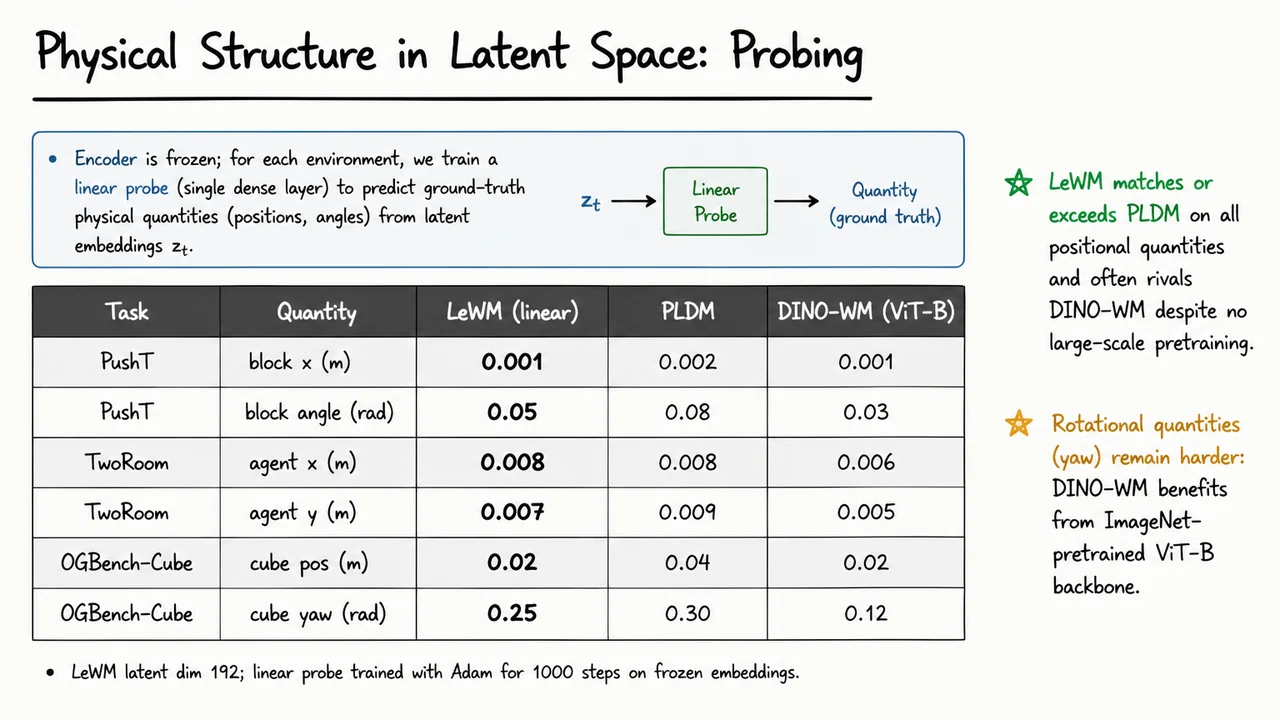
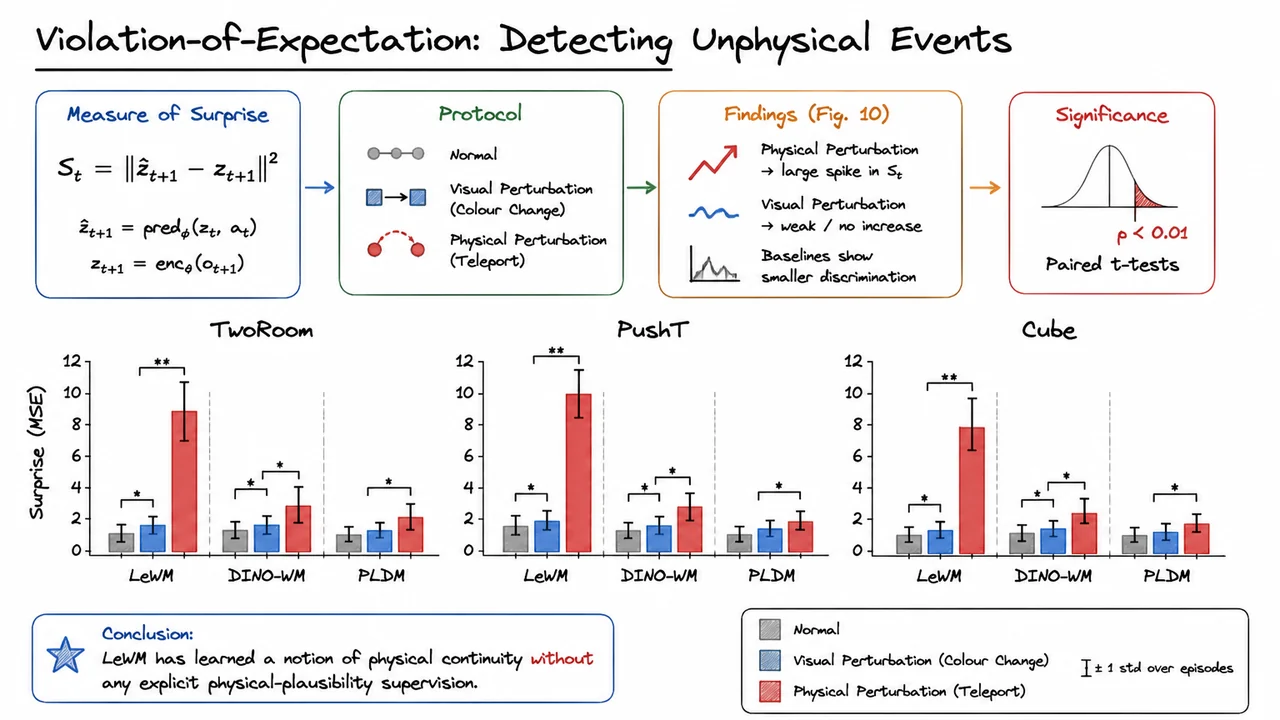
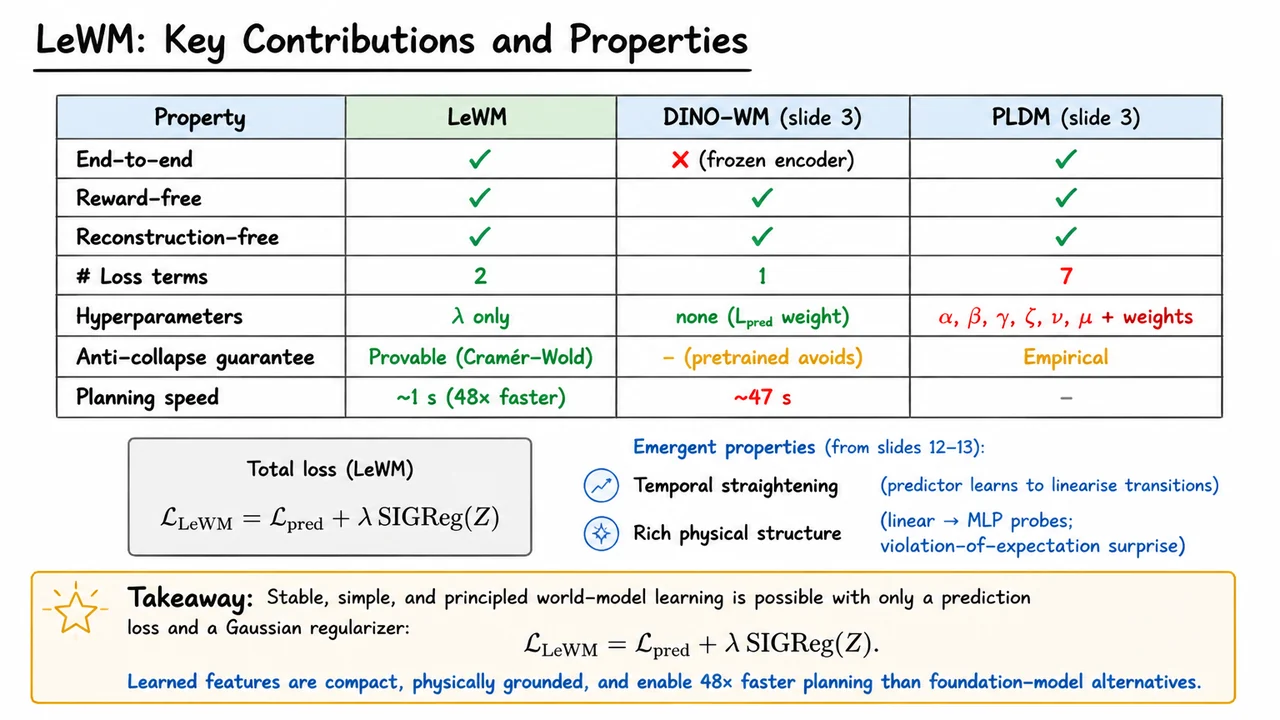
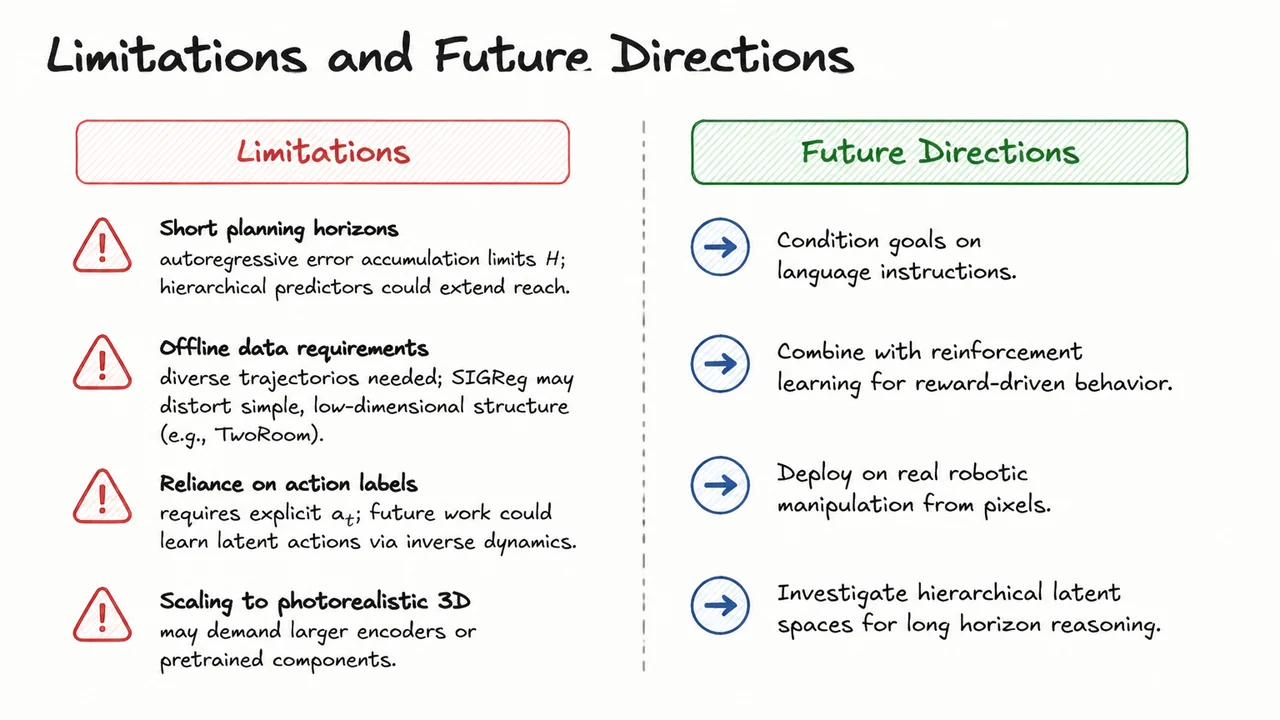
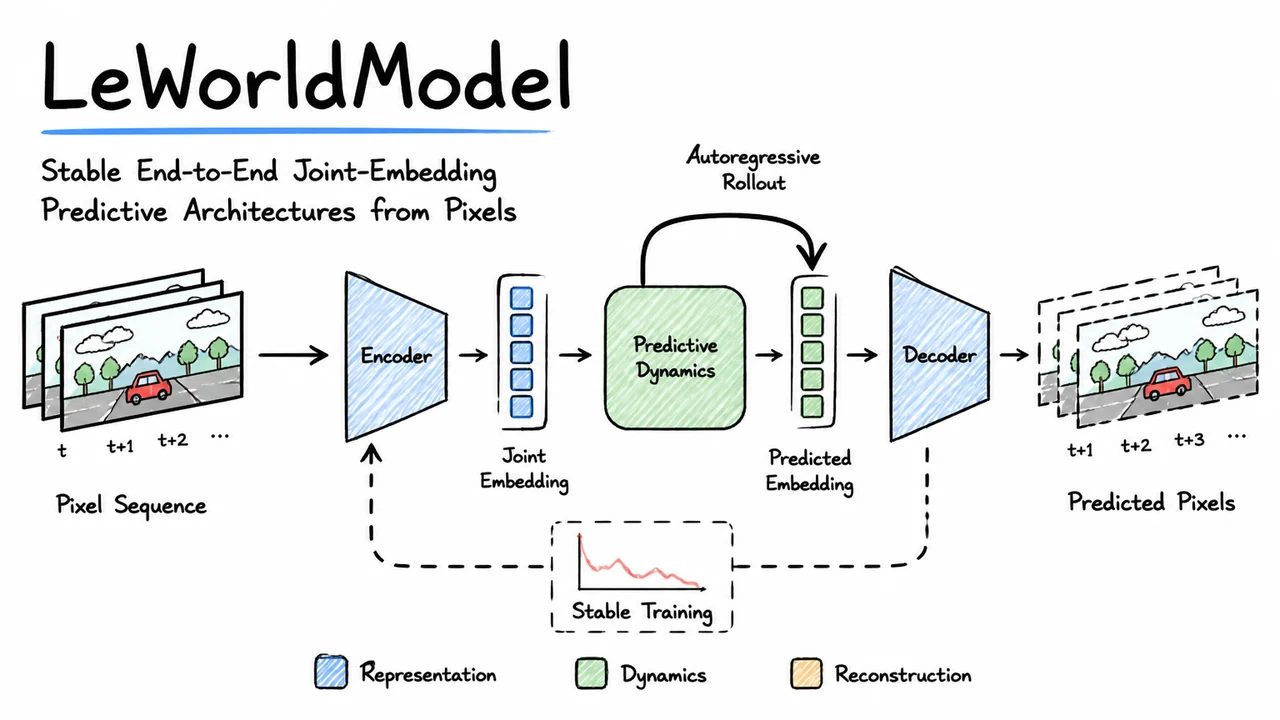
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architectures from Pixels
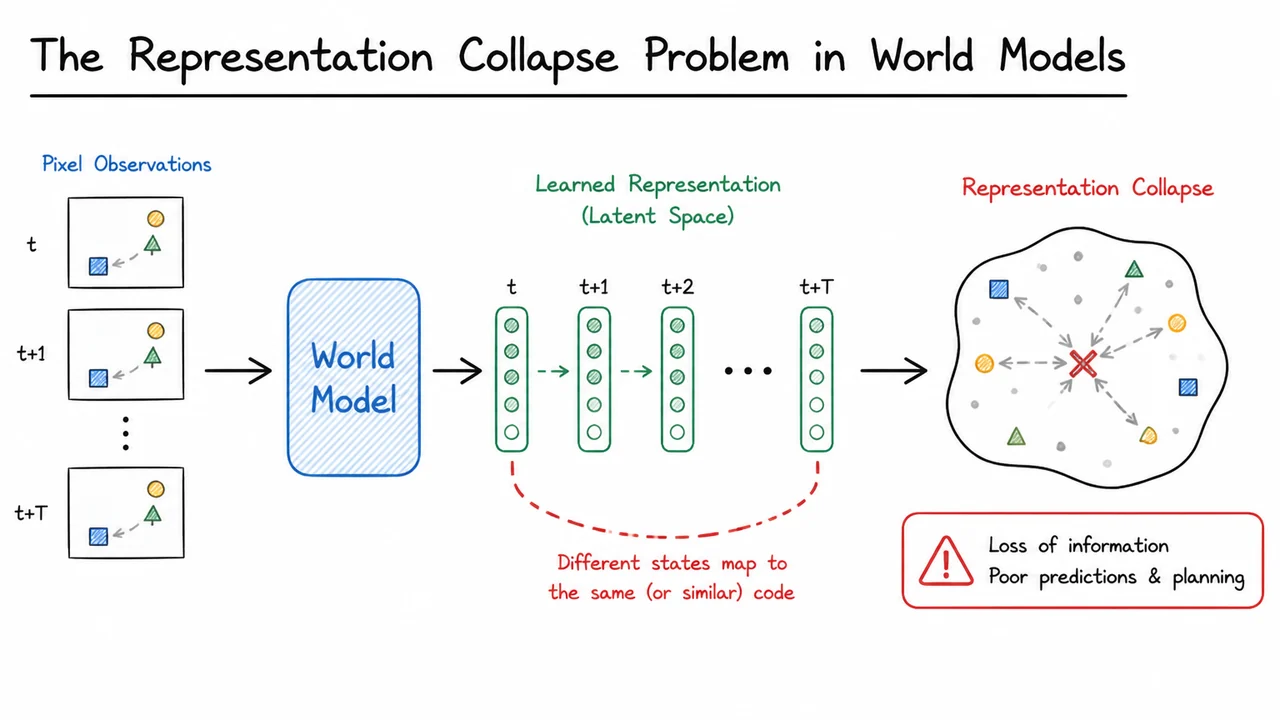
1. The Representation Collapse Problem in World Models
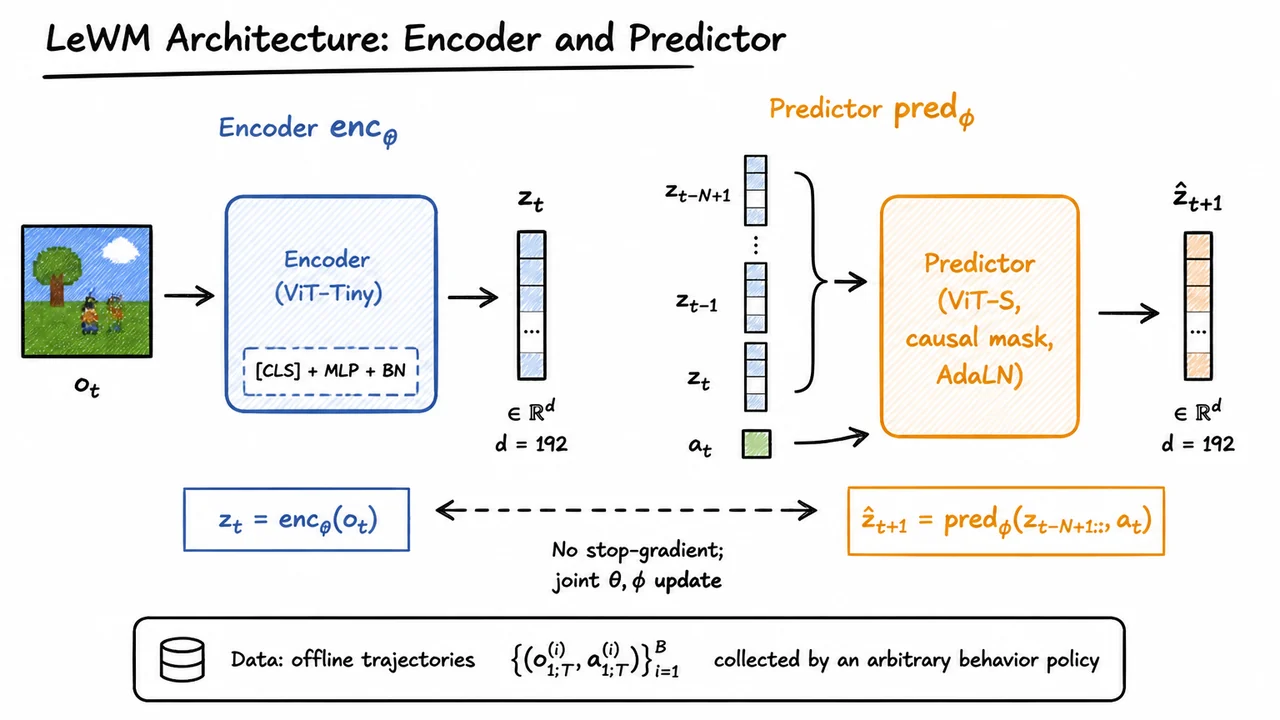
A world model learns to predict future observations from past actions and sensory signals—in effect, an internal simulator that captures the causal structure of an environment. When built directly from high-dimensional pixels, such models can serve as the backbone for planning, sample-efficient reinforcement learning, and open-ended exploration. The allure is clear: rather than hand-crafting state abstractions, we learn a latent representation from raw images that distills the dynamics of the world into a compact code, then predict the next code using a predictor. This family of architectures, known as Joint-Embedding Predictive Architectures (JEPAs), avoids the need for a costly decoder back to pixel space by simply comparing against the encoding of the true next frame.
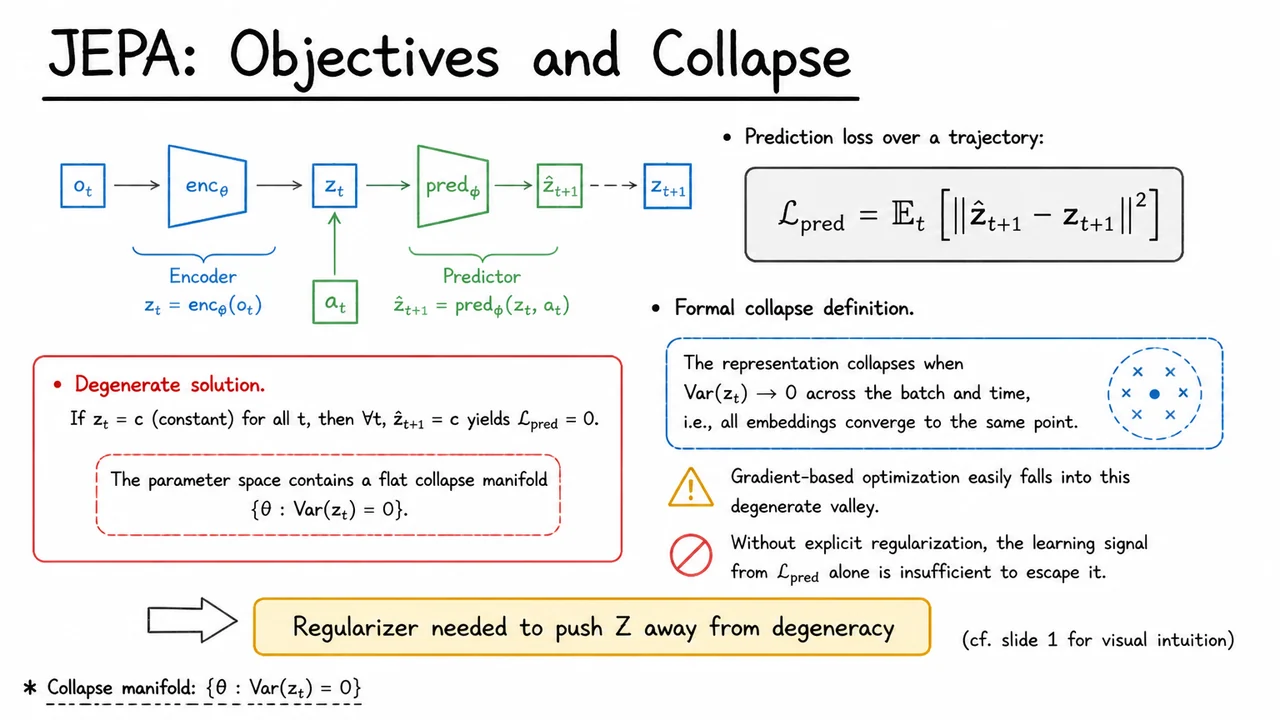
The elegance of JEPAs hides a potentially fatal flaw: representation collapse. Suppose we train the encoder and the predictor jointly with a mean-squared error loss . A trivial solution emerges—the encoder can map all images to the same constant vector, say . Then the predictor will learn to output regardless of the input , and the prediction loss drops to zero. The network has perfectly satisfied the objective, yet it has learned nothing about the environment’s dynamics; the latent representation is uninformative, and any downstream planning or probing task fails. This is the representation collapse problem, and it is not an edge case but rather the natural equilibrium of the naive objective, because the encoder and predictor can “collude” to ignore meaningful variations in the data.
Mathematically, if we denote the encoder output as a distribution over latent codes (or a deterministic point), the model can minimize the variance of under different inputs while also rendering the predictor’s output equally invariant. Even without resorting to constants, partial collapse where all lie on a low-dimensional manifold far simpler than the true state space is common: the encoder may merely preserve the easiest invariances (like brightness or average color) and discard fine-grained motion cues, again leading to trivial future prediction. Collapse is a fundamental identifiability failure: from the perspective of the prediction loss, many degenerate representations are equally optimal, and gradient-based optimization without explicit regularization will happily find one.
Intuition from classical self-supervised learning helps. In Siamese networks, collapse is prevented by comparing representations across different augmentations and employing a asymmetry (e.g., a stop-gradient with a momentum encoder) or by forcing the batch statistics to have high variance (e.g., VICReg). In BYOL, the target encoder’s exponential moving average coupled with a predictor network empirically avoids collapse without negative examples, yet the mechanism is subtle and can still drift toward low-diversity solutions if learning rates or EMA decay are poorly tuned. Contrastive methods (SimCLR, MoCo) avoid collapse by explicitly pushing apart representations of distinct inputs, but they require large batches of negative pairs and can be sensitive to the choice of similarity metric and temperature.
In the context of world models operating on sequential pixel data, these remedies face additional challenges. The temporal dimension introduces strong correlations—consecutive frames are nearly identical, making it harder to rely solely on batch-wise repulsion, because positives and negatives are not decorrelated as nicely as in static-image SSL. Adding a KL divergence to a prior, as in variational autoencoders, keeps the encoder from concentrating to a point, but can still permit collapse onto a small subset of the latent space if the prior is too permissive or the decoder is absent (as in JEPAs). Moreover, stop-gradient techniques decouple the encoder update from the predictor by using a slowly evolving target, but they introduce an architectural asymmetry that can slow down learning or cause the target to eventually catch up and collapse if hyperparameters are not carefully swept.
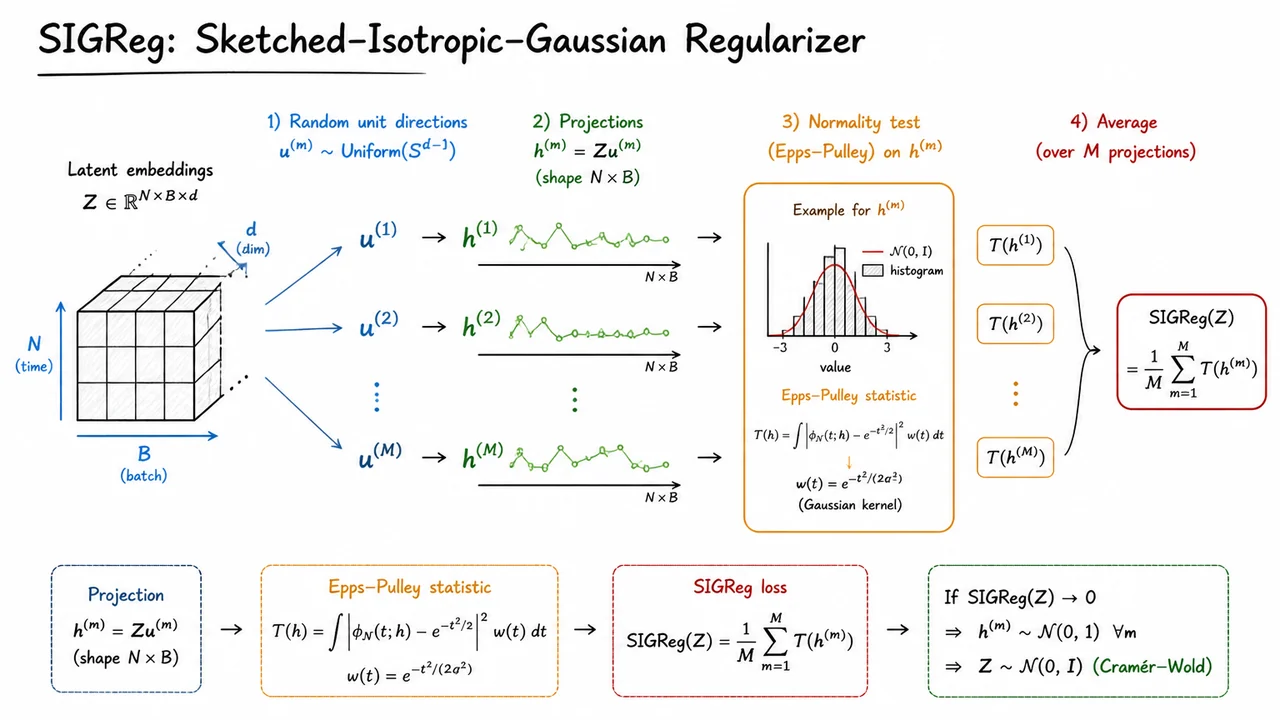
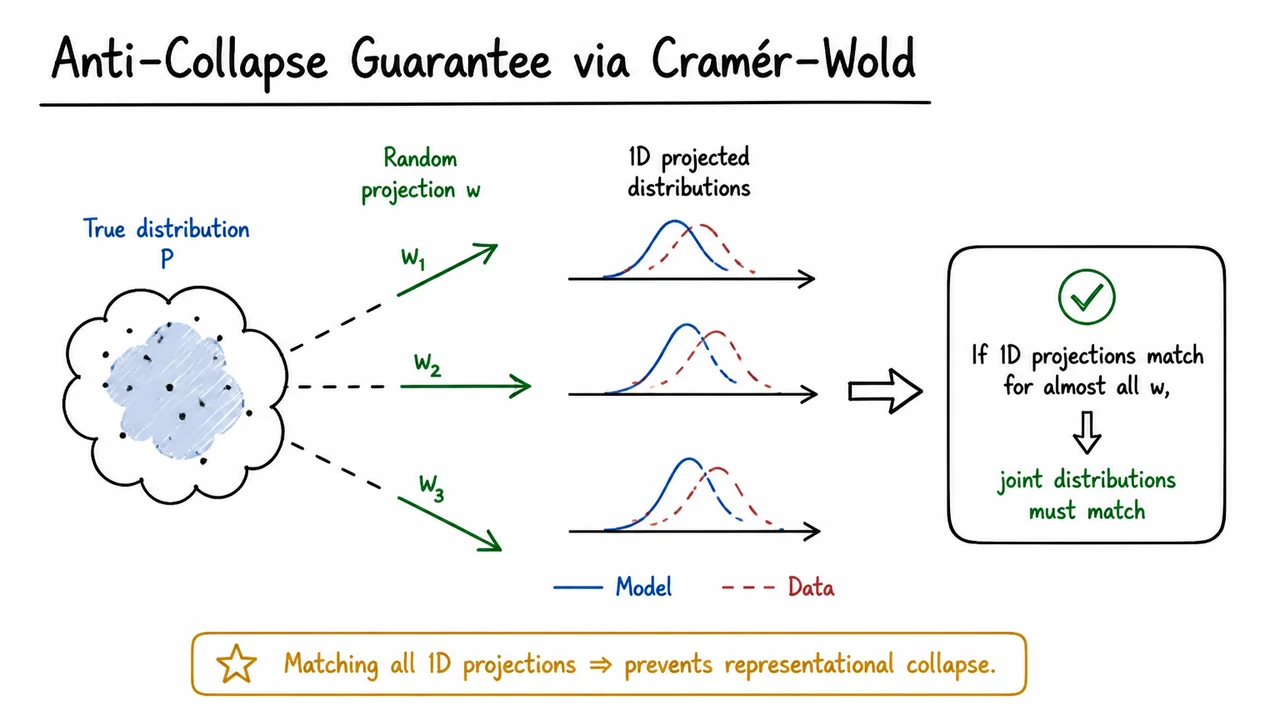
These observations underscore the need for a principled, provably anti-collapse regularizer that can be plugged into a fully end-to-end JEPA training loop without stop-gradients, without negative pairs, and without decoders. The upcoming sections will introduce Sketched-Isotropic-Gaussian Regularizer (SIGReg), which leverages the Cramér–Wold theorem to guarantee that the latent representations remain non-degenerate. But before we get there, it is essential to grasp just how insidious and catastrophic the collapse regime is. To that end, consider the visual below.
A schematic 2-D latent space illustrates the problem: several trajectories of true states—each corresponding to a distinct physical configuration—are drawn as colored sequences of connected points. On the left, before collapse, the encoder spreads these trajectories apart, preserving the topology of the dynamics. On the right, after collapse, all trajectories shrink into a dense ball and the predictor simply outputs the centroid of that ball for every action; the prediction error is zero, but the planner sees no meaningful distinction between a coffee cup tipping over and a robotic arm reaching for it. The collapse is complete, irreversible, and catastrophic for any world model that aims to support downstream reasoning. The regularizer we will derive directly penalizes such concentration, ensuring that the implicit geometry of the latent space remains rich enough to capture the environment’s causal structure.