Machine-Checkable Termination Guarantees for Bayesian Trust in Multi-Agent Systems
1. Production Agents Act Before Humans Can Inspect
A useful place to begin is with a shift in timing. Many safety discussions implicitly assume that an AI system produces something, a human or another process inspects it, and only then does the world change. That assumption is increasingly false for production agents. Modern agents do not merely draft recommendations; they may initiate payments, modify cloud infrastructure, invoke privileged tools, open tickets, merge code, rotate credentials, schedule jobs, or delegate subtasks to other agents.
The important point is not that every one of these actions is catastrophic. Most are routine. The problem is that they are external effects: once executed, they may create obligations, spend money, mutate state, leak information, trigger downstream workflows, or grant access. In a production setting, the question is no longer only “Did the model say something unsafe?” but “Did an automated transition occur that changed the operational state of the system?”
This changes the governance problem from a slow, retrospective one into a machine-speed control problem. If an agent can call a payment API, terminate a server, or delegate authority in milliseconds, then a human review process that runs minutes later is not a guardrail in the relevant sense. It may be useful for auditing, diagnosis, or remediation, but it is not preventing the transition. By the time the operator notices the anomaly, the action may already have completed, propagated, or become difficult to reverse.
So the governance question shifts:
- Post-hoc monitoring: “Did we notice the failure?”
- Pre-execution control: “Was this action allowed before it ran?”
Both matter, but they are not interchangeable. Post-hoc monitoring can tell us what happened and support recovery. Pre-execution control decides whether a proposed action is permitted to cross a boundary in the first place. For production agents, that boundary is often the only moment where a system can still cheaply prevent harm.
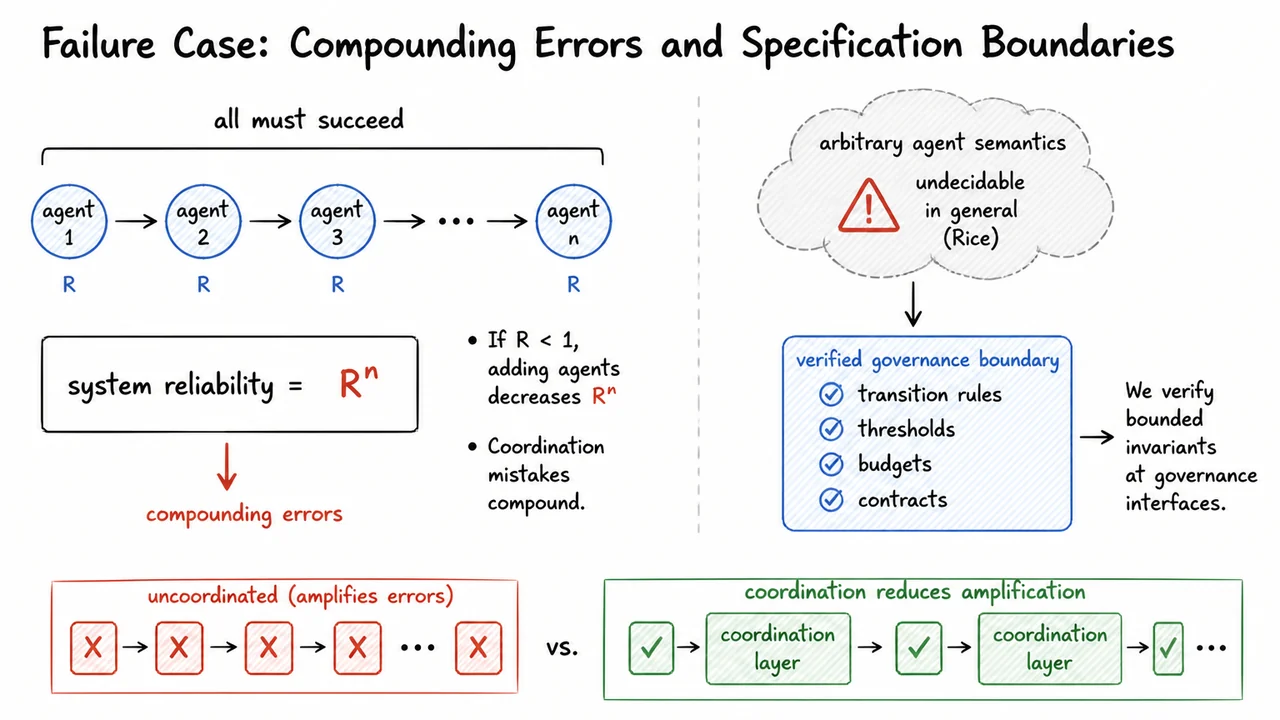
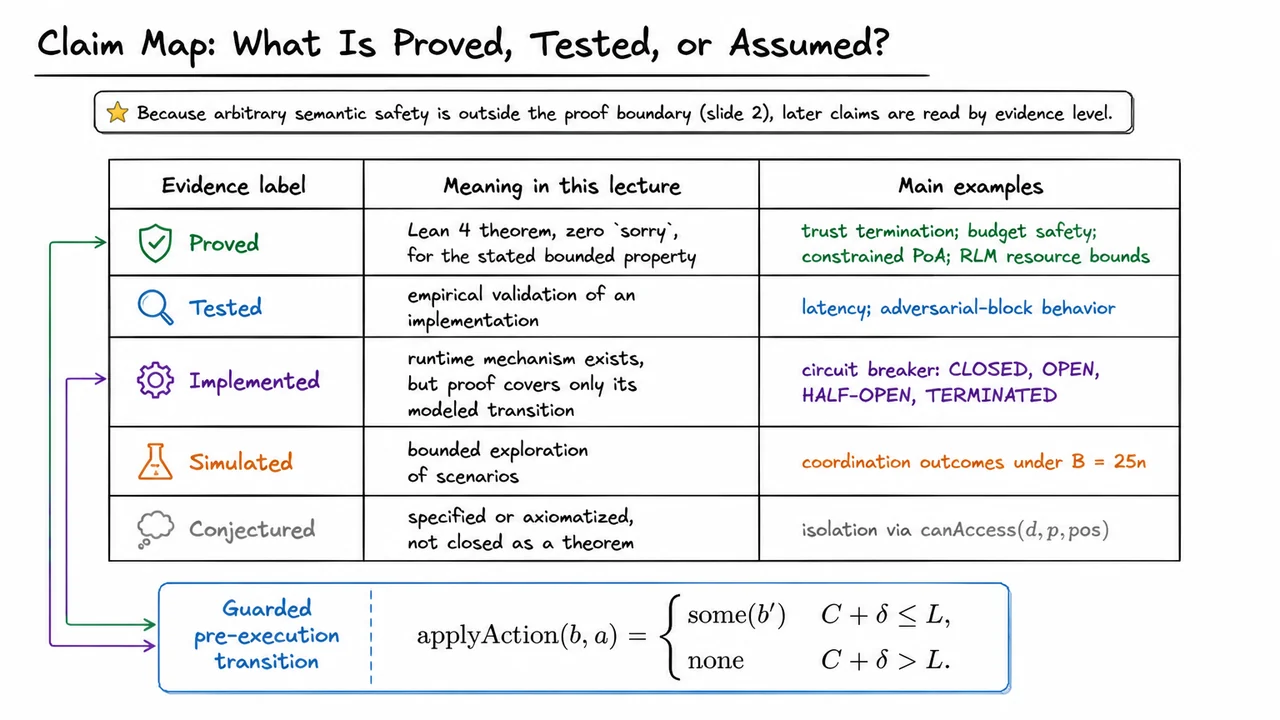
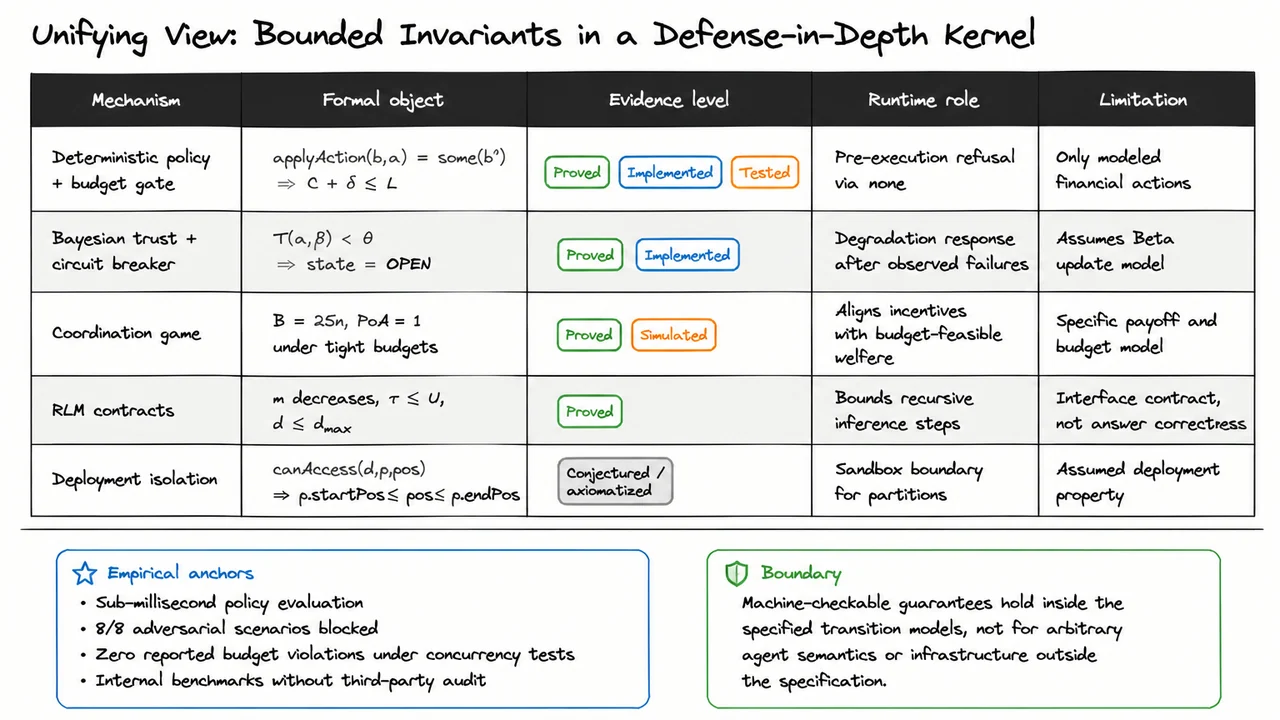
This lecture is therefore not about proving arbitrary “agent safety” in the broadest behavioral sense. That goal is too large, too underspecified, and usually not machine-checkable. Agents operate in open environments, with incomplete specifications, uncertain observations, and changing tool semantics. A claim such as “the agent will behave safely” is not a bounded technical invariant; it is a broad deployment hope unless it is reduced to precise transition properties.
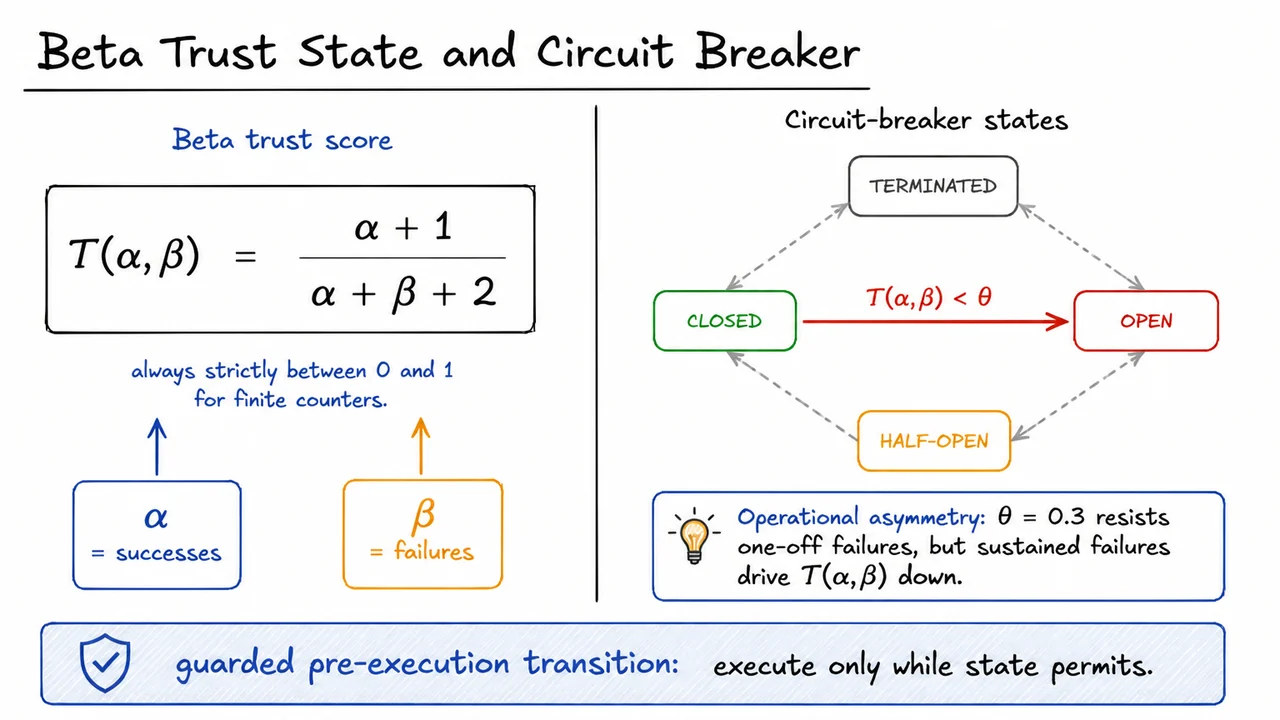
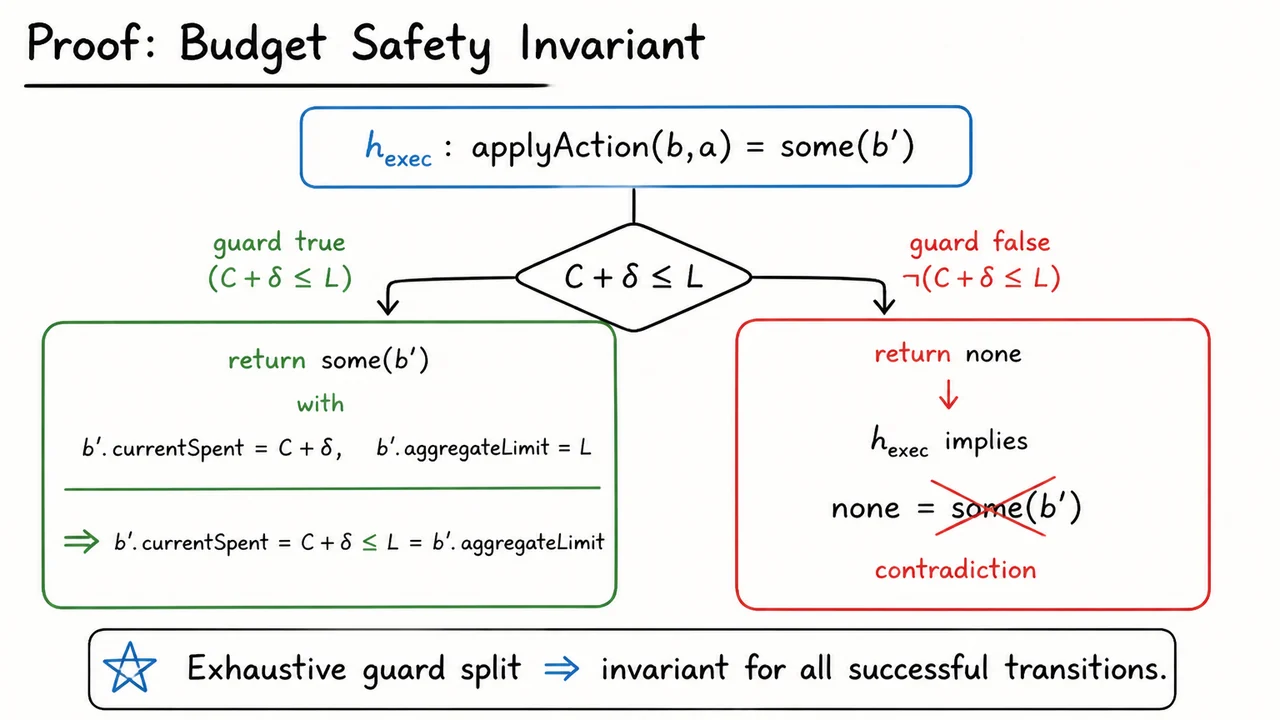
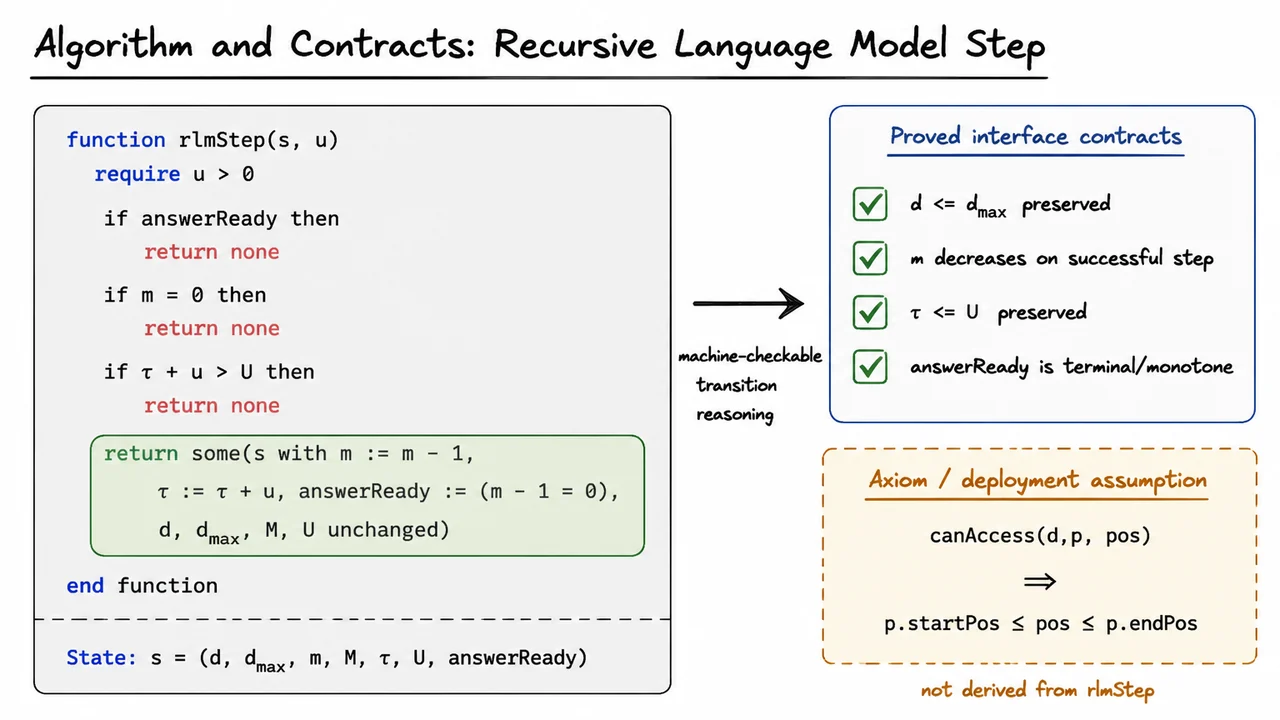
Instead, the focus is on bounded invariants at governance transition points. A transition point is a place where an agent attempts to move from internal computation to an externally meaningful action: spending budget, calling a tool, assigning trust, escalating privileges, delegating work, or mutating infrastructure. At these points, we can sometimes write down exact conditions that must hold before execution. Those conditions can be checked automatically, and in some cases proved correct in a theorem prover.
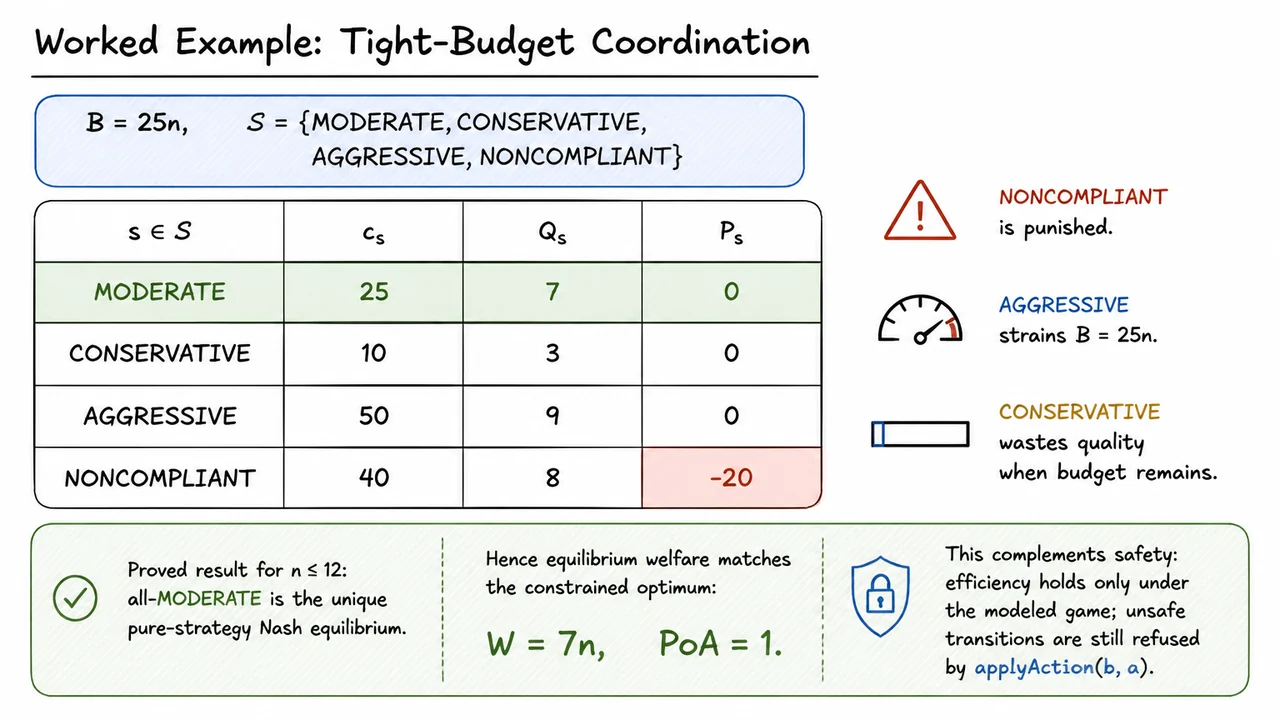
This narrower framing is what makes machine-checkable governance possible. We are not asking the system to prove that an agent is wise, honest, aligned, or globally harmless. We are asking whether a particular transition satisfies a formally stated guard. For example: does this financial action preserve a budget invariant? Does this trust-update process terminate once a threshold is inevitably crossed? Does this coordination rule prevent a forbidden transition under the assumptions stated?
That distinction matters because production deployments are outpacing the controls around them. It is easy to add tool access and agent-to-agent delegation faster than we add formal guardrails. But each new capability increases the number of transitions where a model-generated decision can become an operational fact. The governance layer must therefore operate at the same speed as the agent: before the effect, not merely after the log entry.
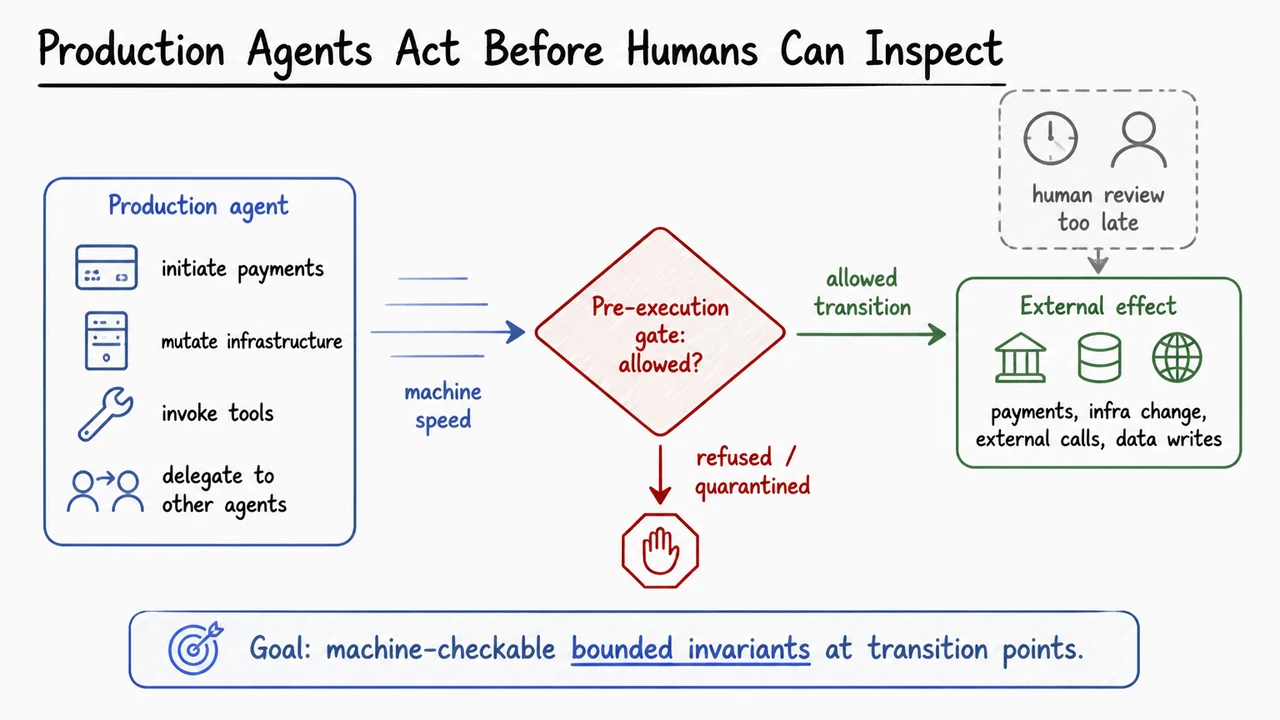
The visual below compresses this motivation into a single pipeline: a production agent proposes an action, the system reaches a pre-execution gate, and only then does the action either proceed to an external effect or get refused and quarantined. The faded human-review element is deliberately placed after the effect because that is the timing problem: human inspection remains valuable, but it is often too late to serve as the primary safety mechanism.
The central lesson is the banner at the bottom: the goal is machine-checkable bounded invariants at transition points. Everything that follows in the lecture should be read through that lens. We will distinguish proved claims from tested or conjectured ones, and we will prefer precise transition guarantees over sweeping behavioral assurances.