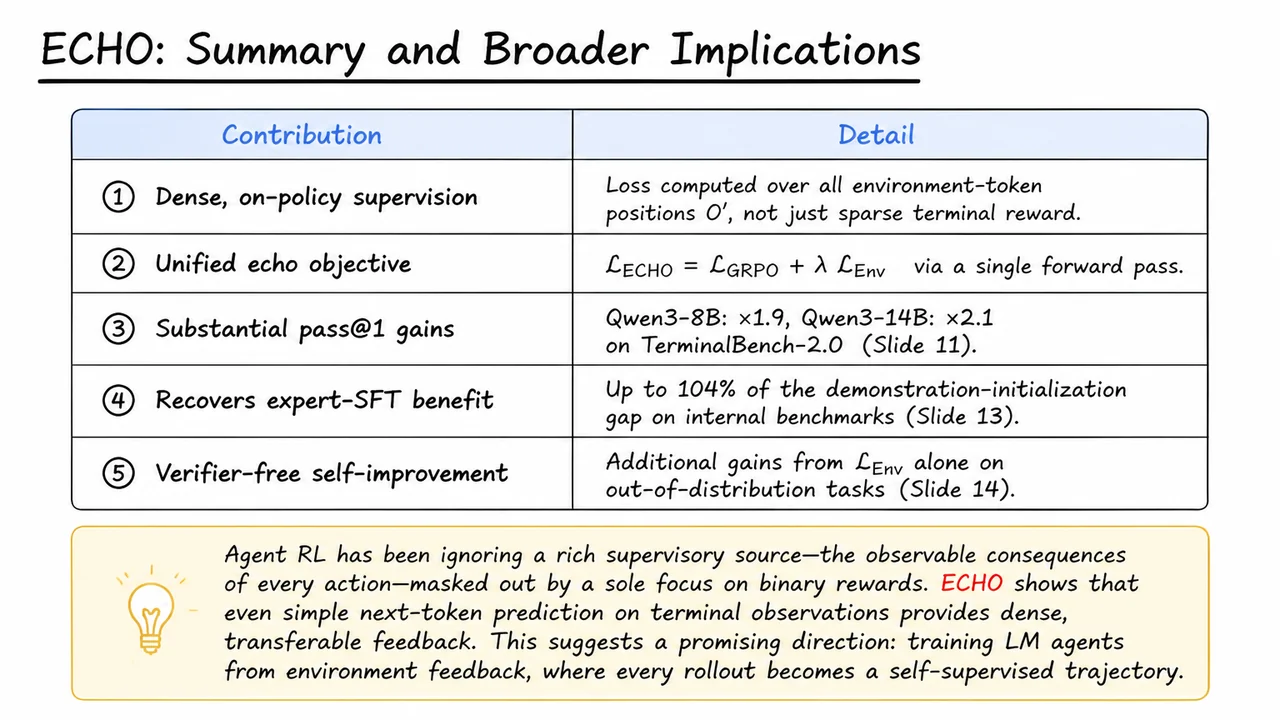
ECHO: Turning Terminal Feedback into Dense Supervision for Agent RL
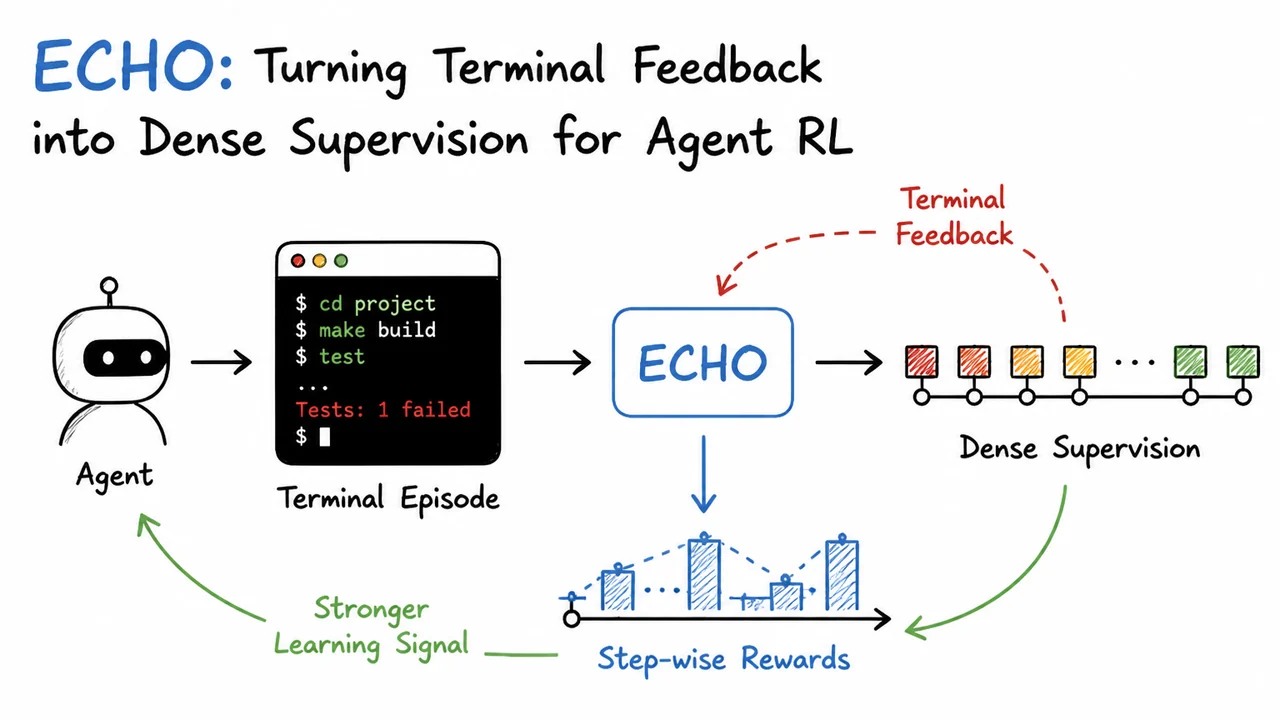
1. The Wasted Supervision in Terminal Agents
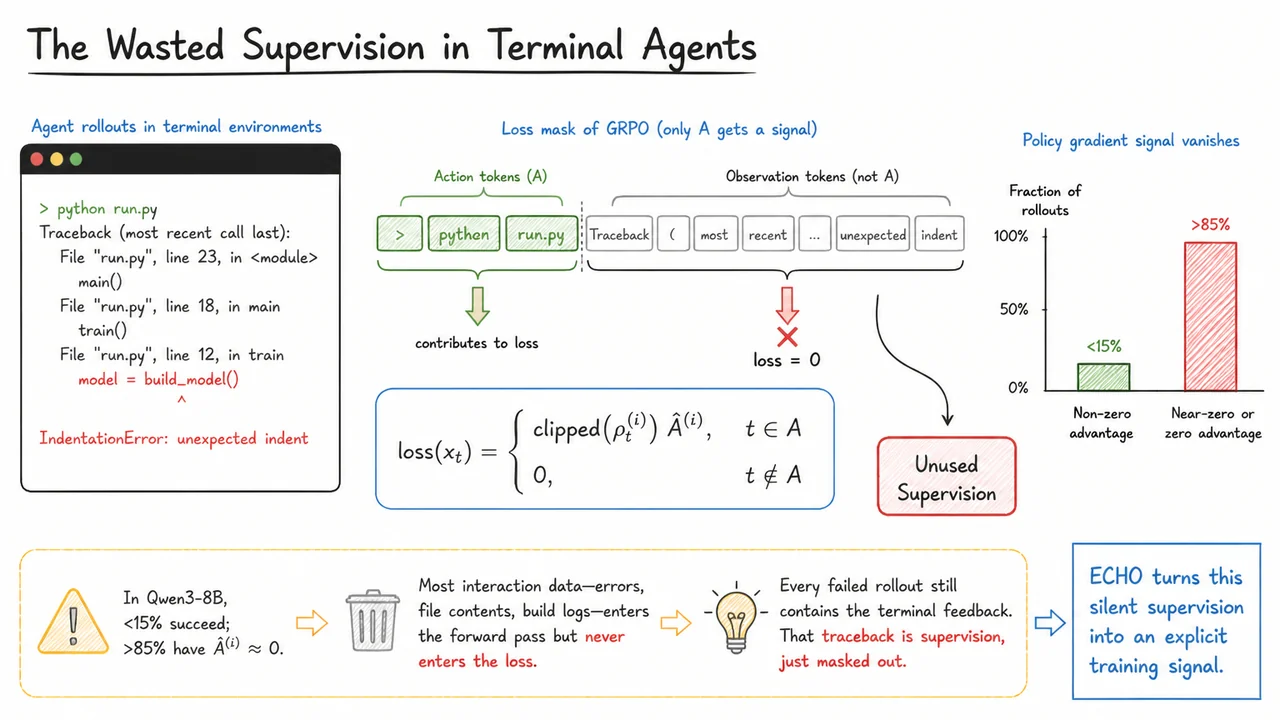
When we train an autonomous agent to interact with a terminal—editing code, running test suites, invoking the compiler—every rollout generates a long sequence of interleaved agent actions and environment observations. A typical trace might begin with a system prompt, continue with the assistant’s command python run.py, and then receive a burst of diagnostic output: a stack trace, an error type, and a line number pointing to the offending indentation. This raw interaction is rich with information about what went wrong, yet in the dominant paradigm of reinforcement learning with Group Relative Policy Optimization (GRPO), almost all of it is deliberately discarded before the optimizer ever sees it. Understanding why and what we lose is the first step toward the ECHO method.
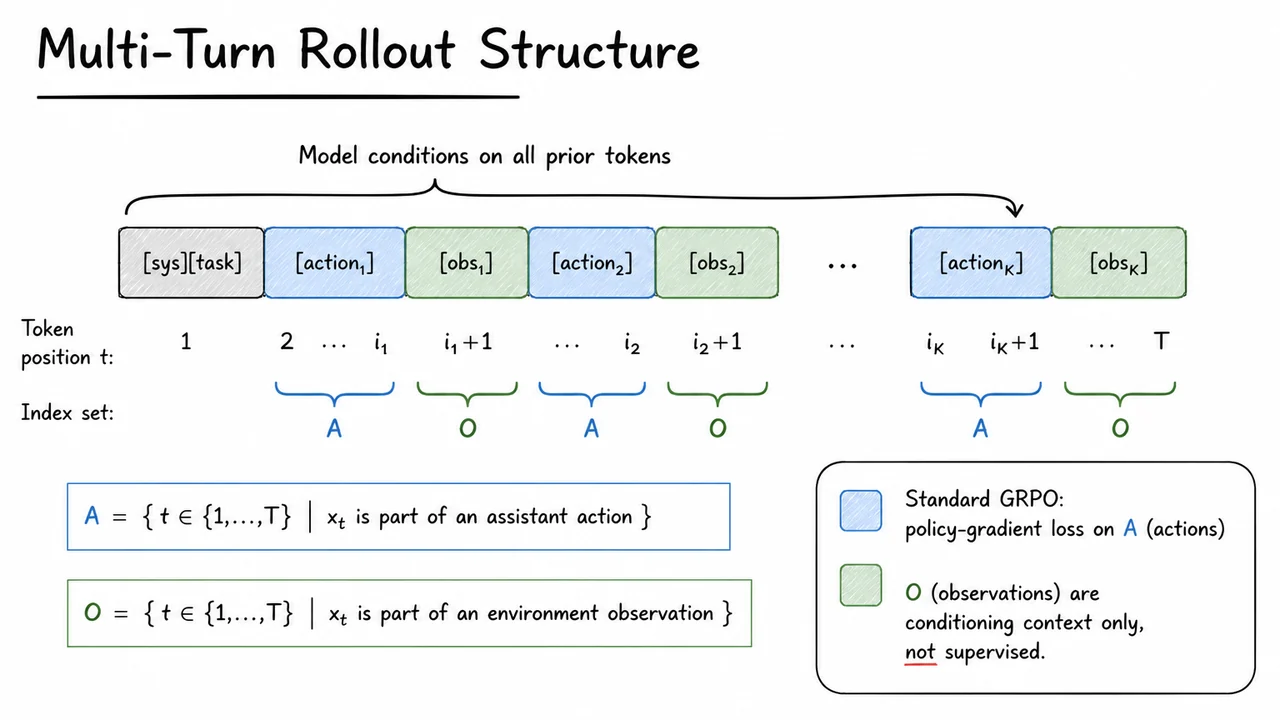
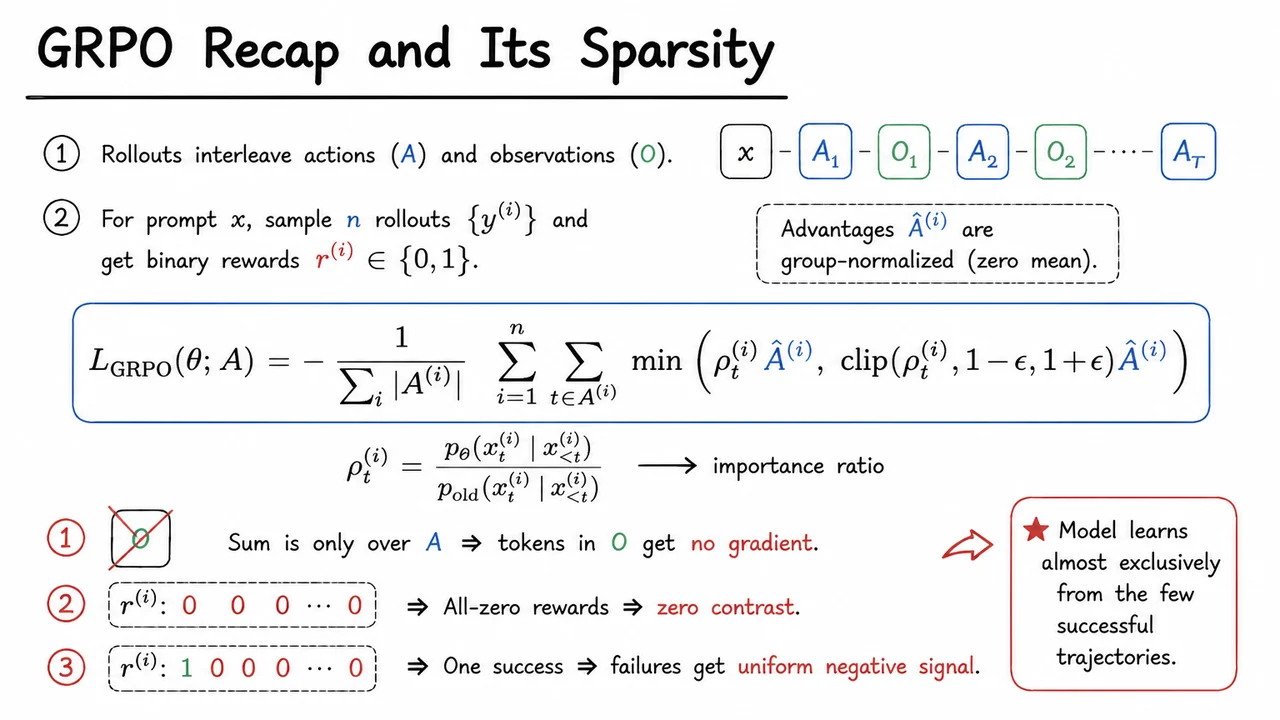
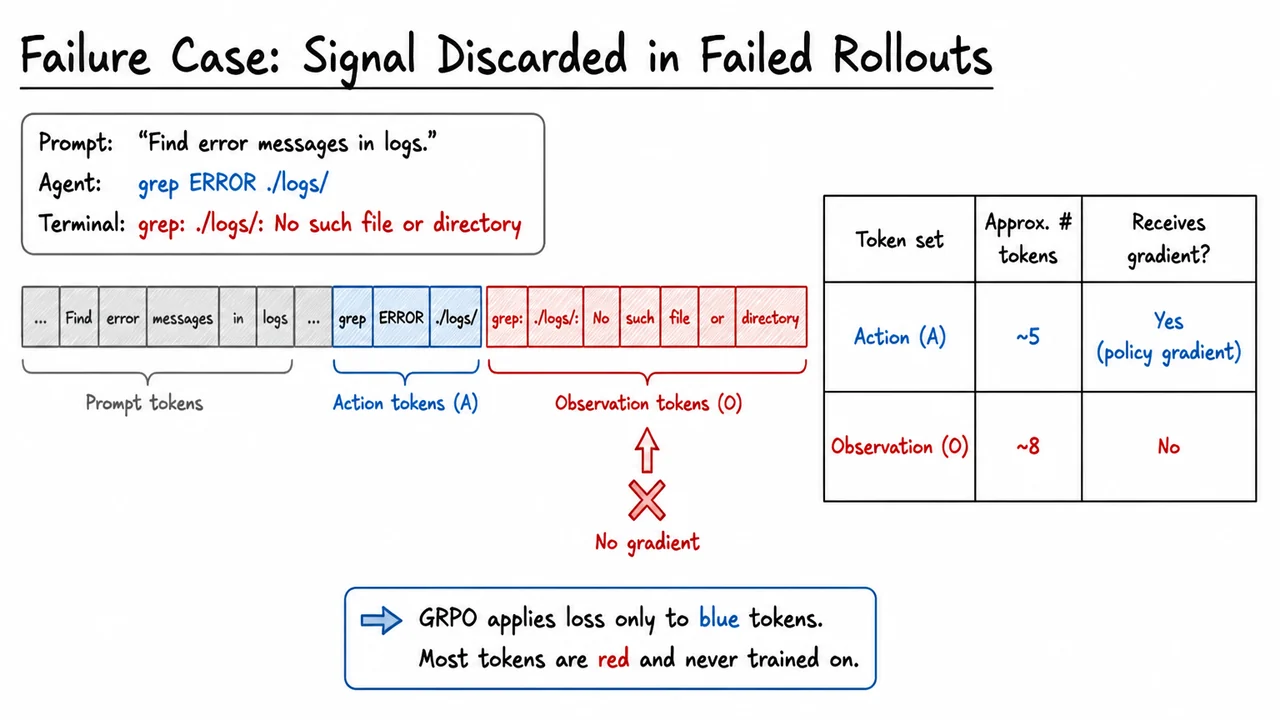
The GRPO loss is computed token by token over the sequence, but a crucial loss mask restricts gradient flow to a specific subset. Let the rollout be . The model assigns a probability ratio at each token relative to the reference policy, and the advantage is computed from the final reward of the full rollout (or group-normalised reward). The per-token loss is where is the set of action tokens generated by the assistant. Everything else—system messages, environment outputs, error reports, file contents, and build logs—carries a loss of zero. This masking scheme is a natural extension of the language model fine-tuning paradigm that treats only the model’s own text as trainable, but in agentic trajectories it creates a severe credit assignment bottleneck.
The problem emerges from the interaction between masking and the advantage signal. In terminal-based tasks, success is often binary and sparse: the agent either completes the objective (a passing test, a correct edit) or it does not. In practice, when fine-tuning a model like Qwen3-8B on a realistic coding benchmark, fewer than 15% of rollouts succeed. For the remaining >85%, the final reward—and therefore the advantage —is either zero or lies in a tightly grouped cluster where the group-normalized advantage becomes vanishingly small. The masked loss renders most interaction data invisible to the parameter update. The forward pass still processes the observation tokens (they consume compute and shape the internal states for subsequent actions), but the backward pass ignores them entirely. Learning is starved: thousands of failed explorations carry zero effective gradient for the portions of the sequence that describe why the failure occurred.
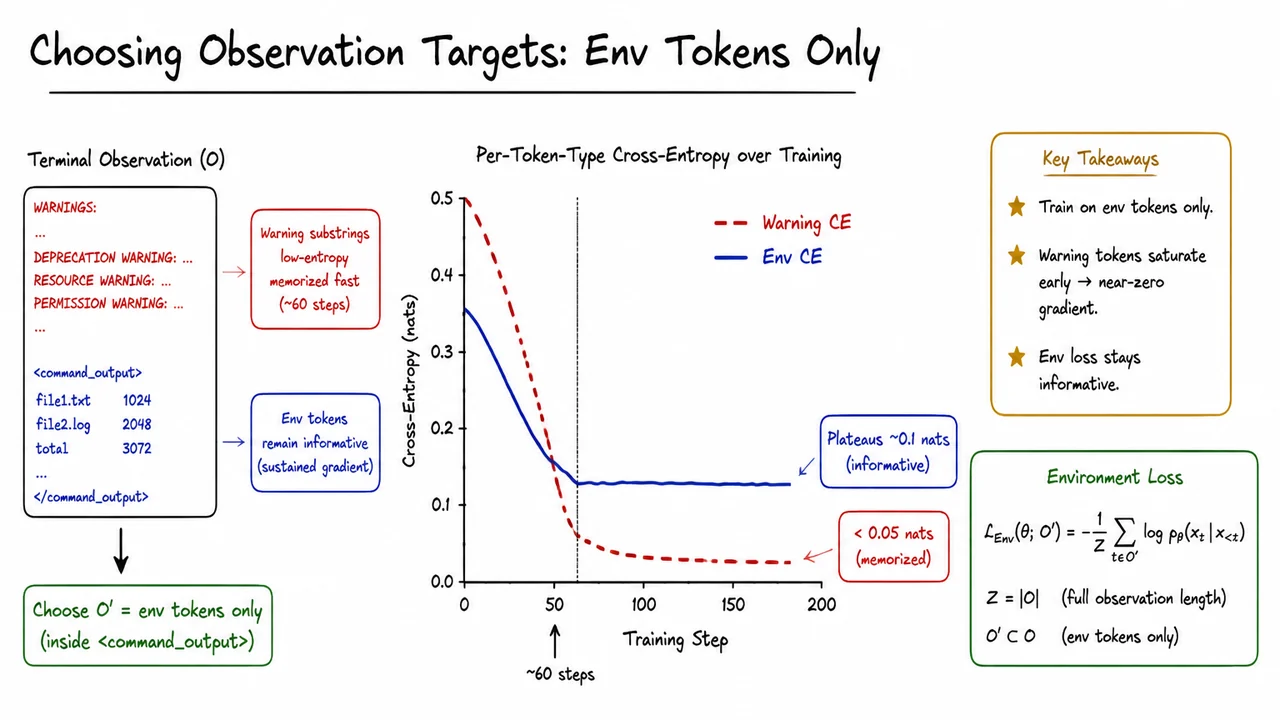
This would be merely inefficient if the discarded tokens were pure noise, but they are not. Every failed rollout still contains terminal feedback that explains the failure. A Python traceback tells the model which line caused an IndentationError and the exact context around it. A build log might reveal a missing header file. A test run output shows which assertion failed and by how much. These signals are supervision—just not in the form of a scalar reward, and just not placed on the action tokens themselves. Under standard GRPO masking, the traceback is a silent passenger: it enters the transformer stack, influences the hidden representations, but the loss function never explicitly rewards the model for generating actions that would have fixed the error. The supervision is, in effect, wasted.
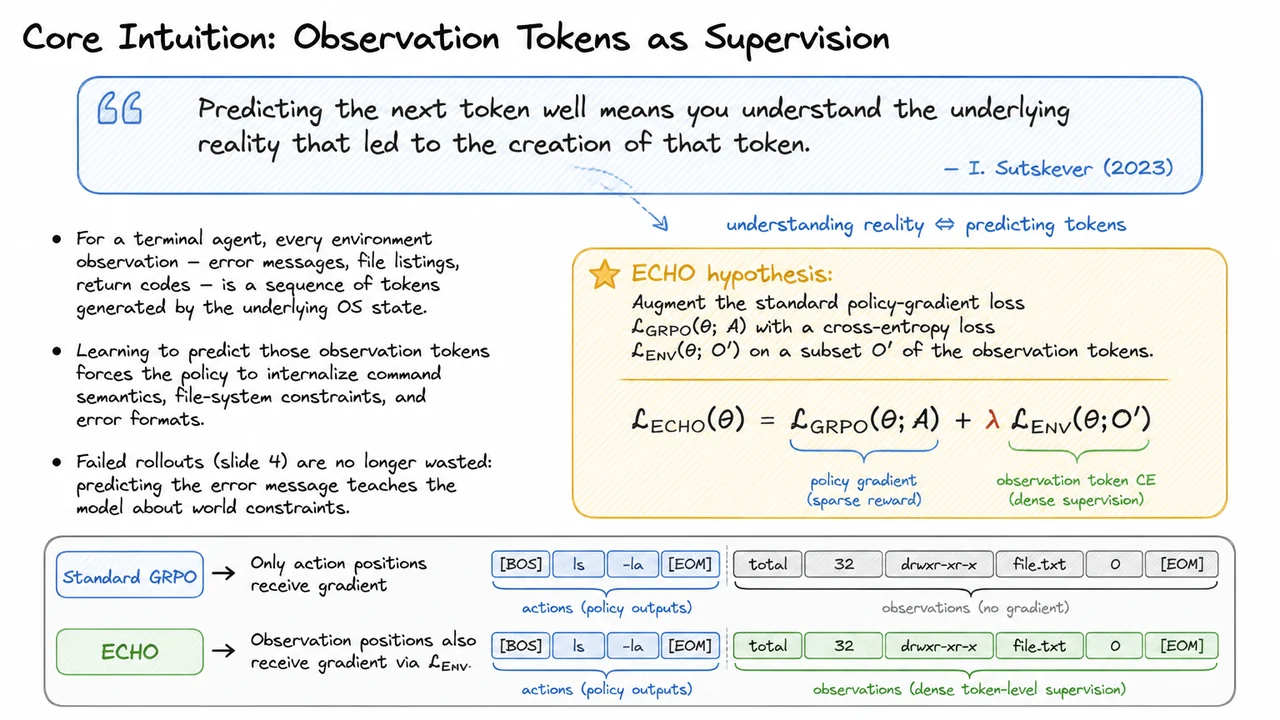
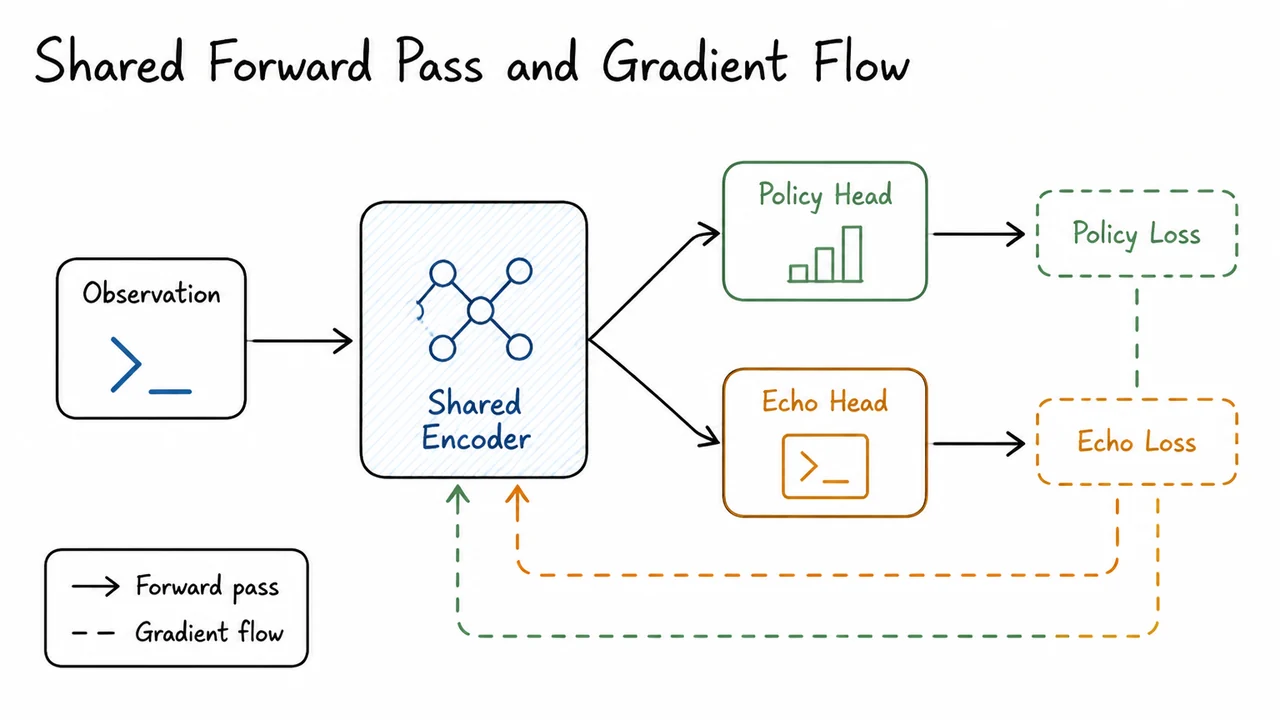
The core insight of ECHO is that this wasted supervision can be reclaimed as a dense auxiliary training signal. By adding an extra objective—a cross-entropy loss that predicts the observation tokens themselves, conditioned on the preceding context—the model is forced to actively model the terminal feedback that follows its actions. If the assistant predicts that running a block of code will produce a certain error, it is effectively learning a world model of the terminal environment, and this predictive competence directly improves its ability to generate corrective actions. The mask that once silenced the environment becomes a teacher.
The accompanying diagram distills this imbalance. On the left, a terminal window shows the agent’s action python run.py and the resulting multi-line traceback ending in IndentationError: unexpected indent. In the center, the loss mask is rendered as a sequence of colored blocks: the action tokens are highlighted (say, in green) with an arrow pointing to the loss gradient, while the observation tokens—the entire error message—are grayed out and marked with a red “X” and the label loss = 0. From those grayed blocks, a branching arrow leads to a separate box labeled “Unused Supervision,” making the waste explicit. To the right, a small bar chart compares the tiny fraction of rollouts that receive a non-zero advantage (~15%) against the vast majority that contribute near-zero advantage (~85%), annotated “Policy gradient signal vanishes.” The visual layout forces the reader to confront the reality that nearly all diagnostic content is systematically excluded from training, and it frames ECHO’s ambition to turn that silent resource into a learning signal. In the next section, we will dissect the multi-turn rollout structure that makes this auxiliary supervision both feasible and effective.