Reinforcement Learning for Large Language Models: Group Relative Policy Optimization (GRPO)
1. Lecture Outline & Why RL for LLMs?
Large language models are astonishingly good at producing plausible text, yet the metric they were trained to optimize—next-token likelihood—is not the same as being helpful, honest, or safe. A pre‑trained model has absorbed statistical patterns from web‑scale data, including biases, toxicity, and factual errors. The central challenge of alignment is to steer these models so that their outputs reflect nuanced human values without sacrificing the fluency and generality we paid so much to acquire.
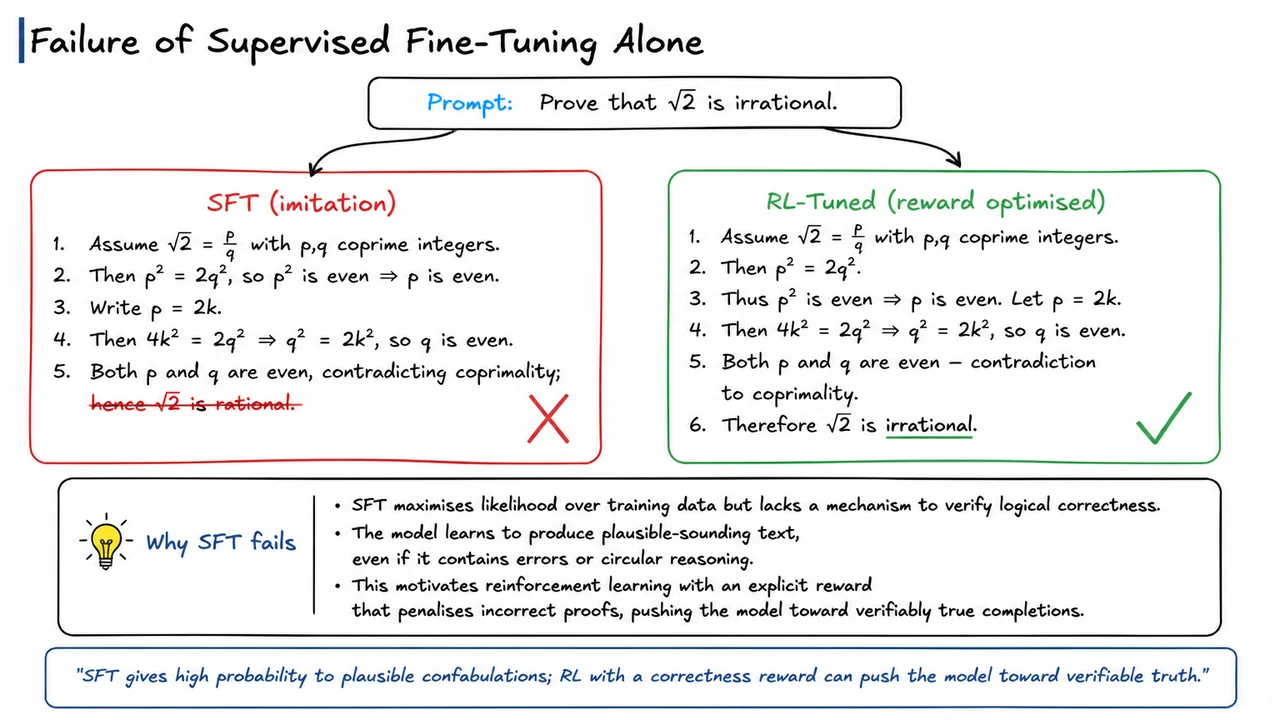
Supervised fine‑tuning (SFT) is a natural first step: we collect high‑quality demonstrations of desired behavior and train the model to imitate them. SFT teaches the model the stylistic conventions of a helpful assistant, but it cannot directly optimize for qualitative objectives that are inherently comparative or context‑dependent. A response that is truthful yet unhelpful, or safe but evasive, is hard to penalize with a fixed dataset of positive examples. SFT essentially copies the distribution of the demonstrations—it minimizes the forward KL divergence to the data. The model learns to reproduce the style of the examples, not to pursue abstract objectives like “be honest whenever possible” or “avoid harmful advice even when the prompt is ambiguous.” This gap between imitation and optimization is the reason reinforcement learning enters the picture.
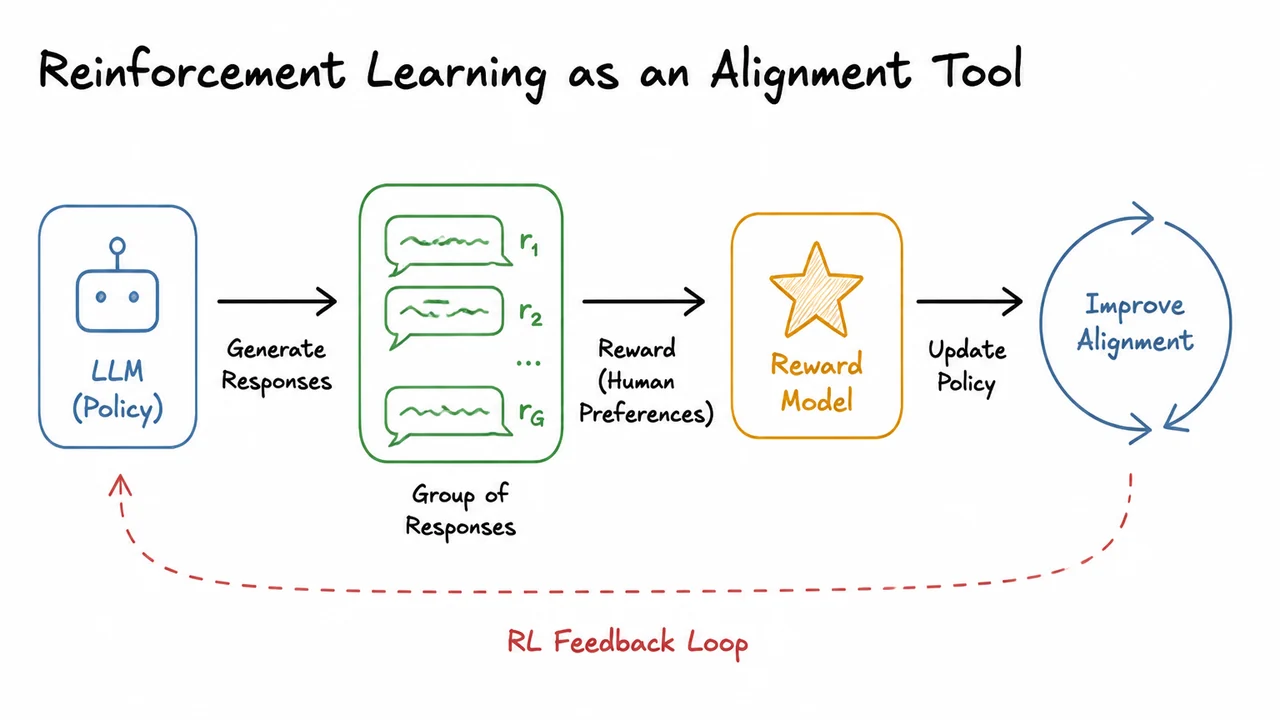
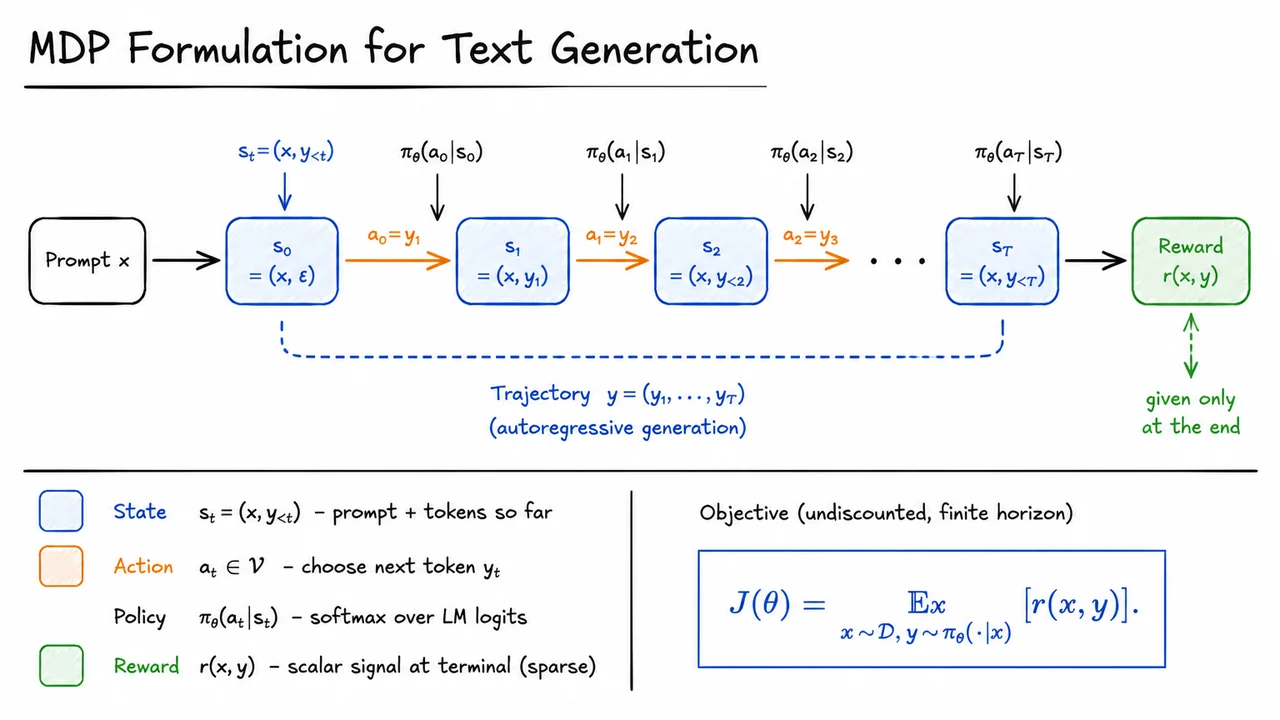
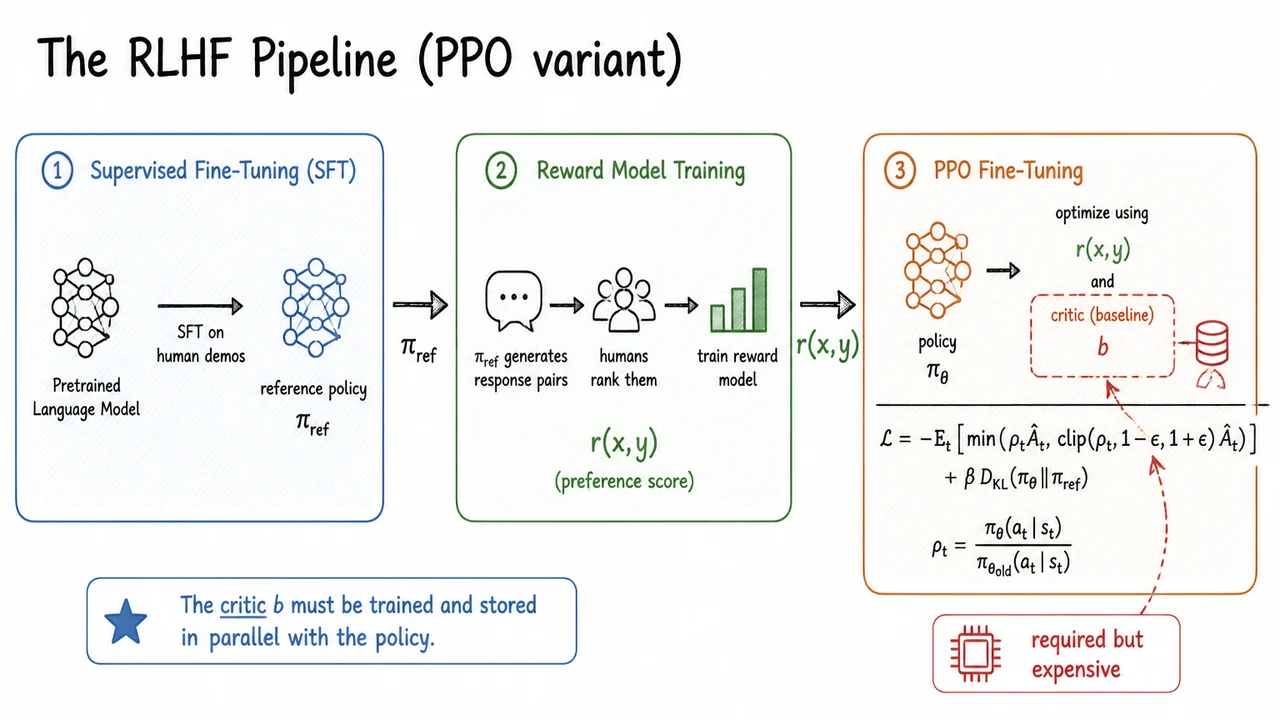
Reinforcement learning from human feedback (RLHF) recasts alignment as a reward‑maximization problem. Instead of hand‑writing a reward function, we enlist human annotators to compare pairs of model outputs and express preferences. A separate reward model is trained to predict those human judgments, acting as a proxy for the true, hard‑to‑specify objective. Then we treat the language model as a policy that generates a response given a prompt , and we use RL to update to maximize the expected reward. Crucially, the update also includes a penalty that keeps the policy close to a frozen reference model (usually the SFT model), preventing the policy from drifting into nonsensical but spuriously high‑reward regions. The objective becomes something like:
where controls the strength of the KL regularizer. This framework can optimize for complex, human‑defined criteria that are not captured in any static dataset, and it enables the model to explore a range of responses while learning which ones are preferred.
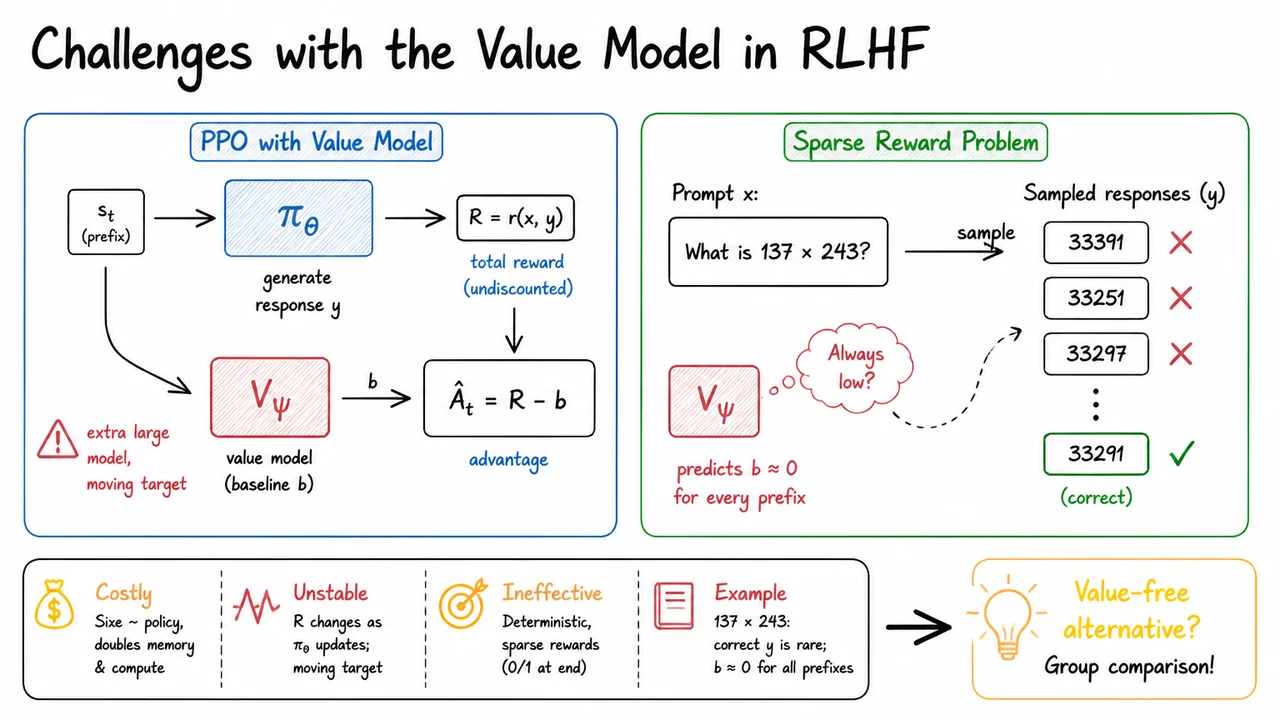
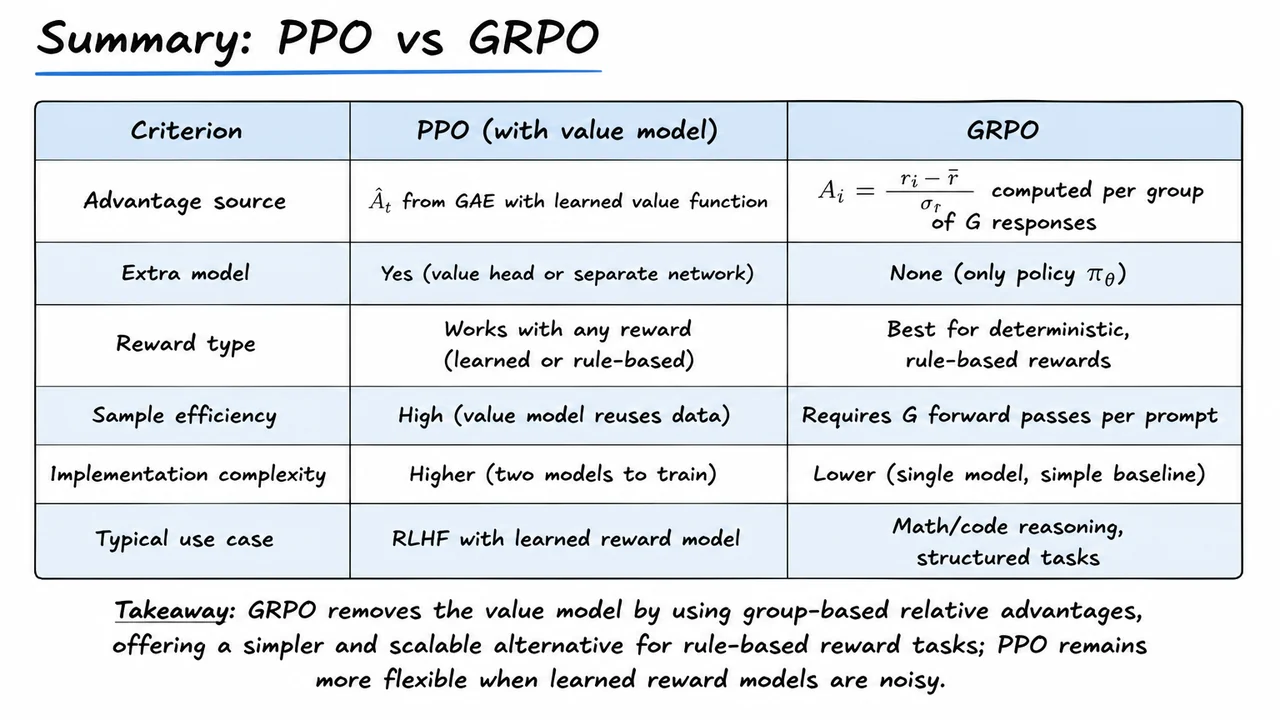
The most widely used algorithm for RLHF is Proximal Policy Optimization (PPO). PPO alternates between sampling batches of responses, evaluating them with the reward model, and performing several gradient updates on the policy while clipping the update size for stability. A critical component is the value function, a learned critic that estimates the expected future reward from a given state (partial sequence). The value function is used to compute advantages, which reduce the variance of policy gradient estimates. However, maintaining a separate value model at the scale of modern LLMs introduces significant engineering and sample‑efficiency burdens: the value network must be roughly as large as the policy to be accurate, it needs its own training loop, and it can introduce estimation errors that destabilize training.
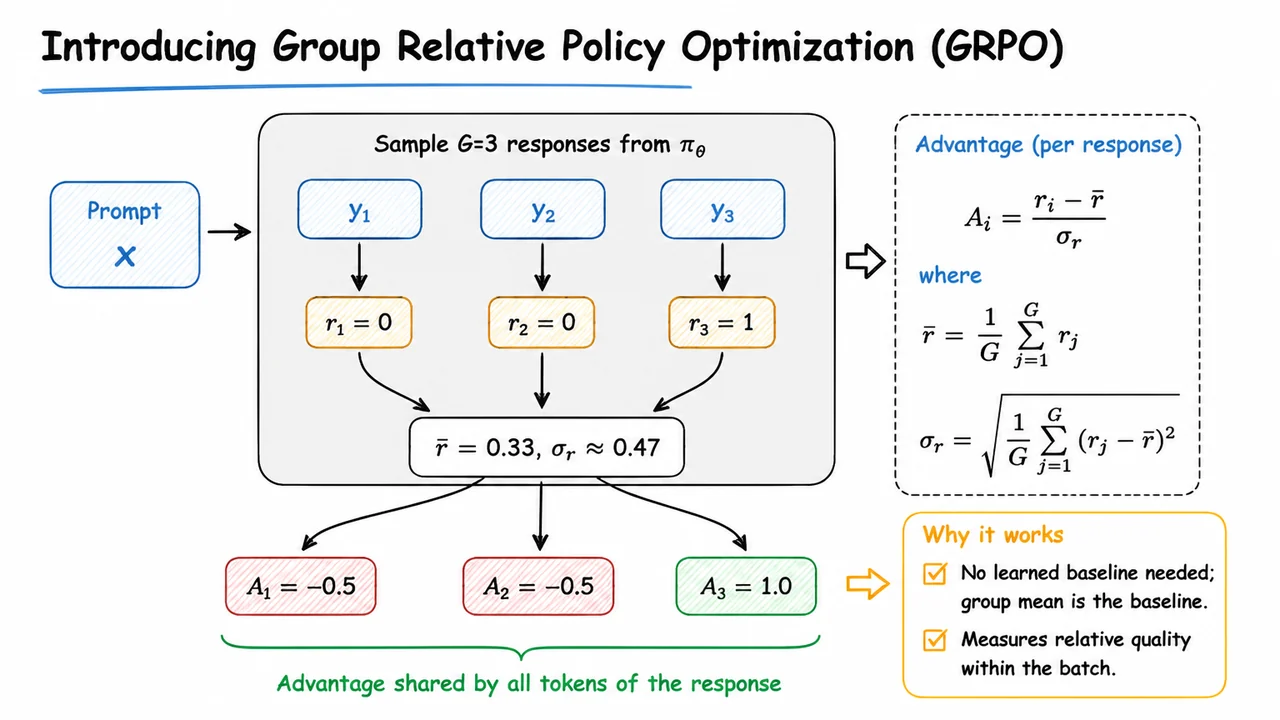
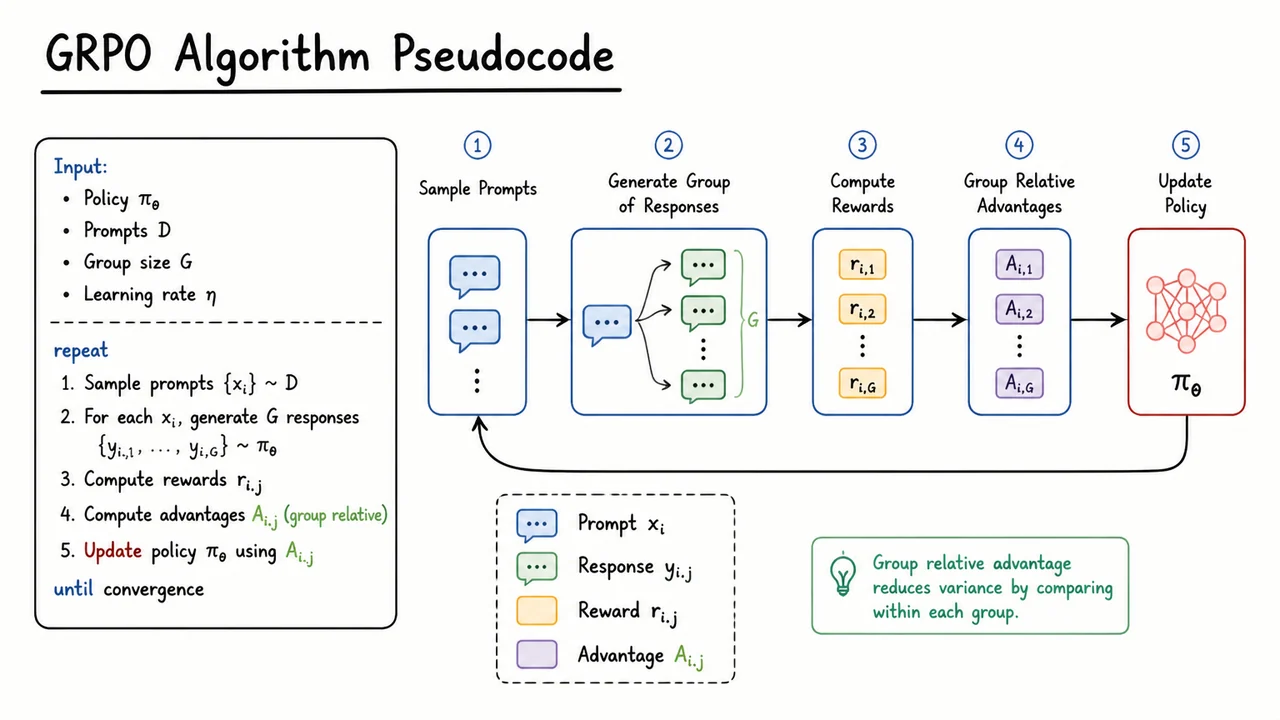
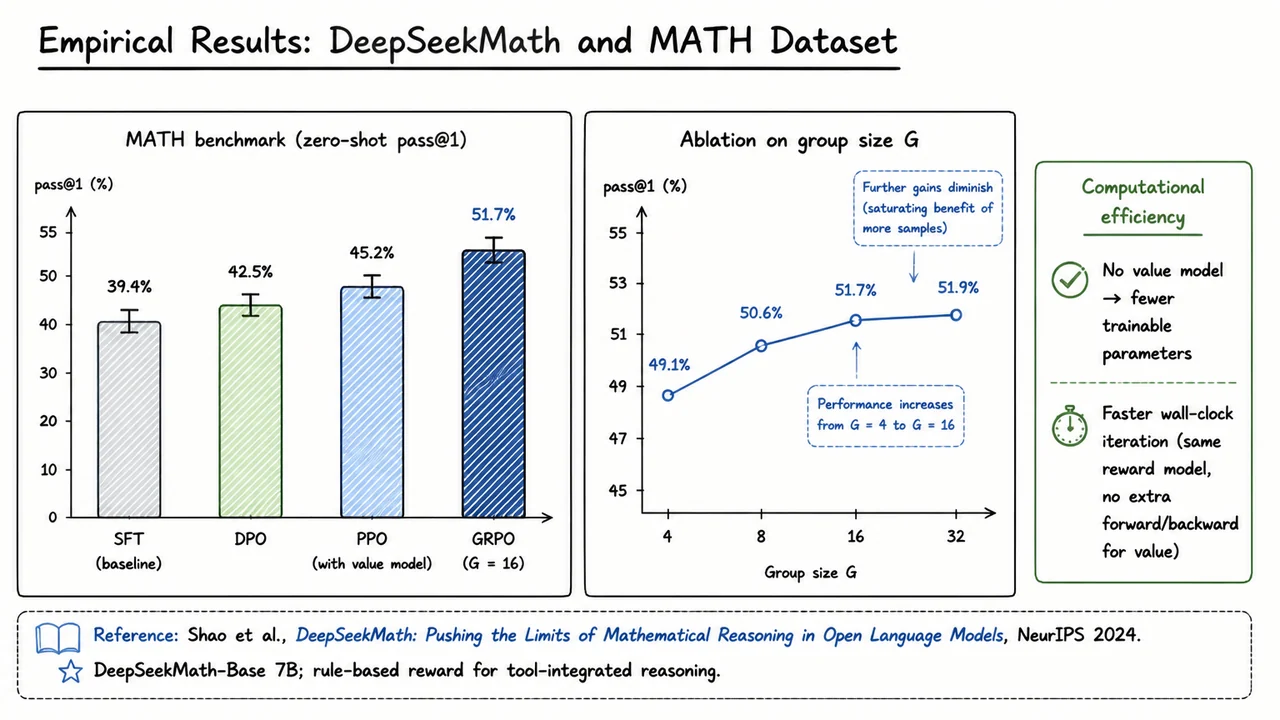
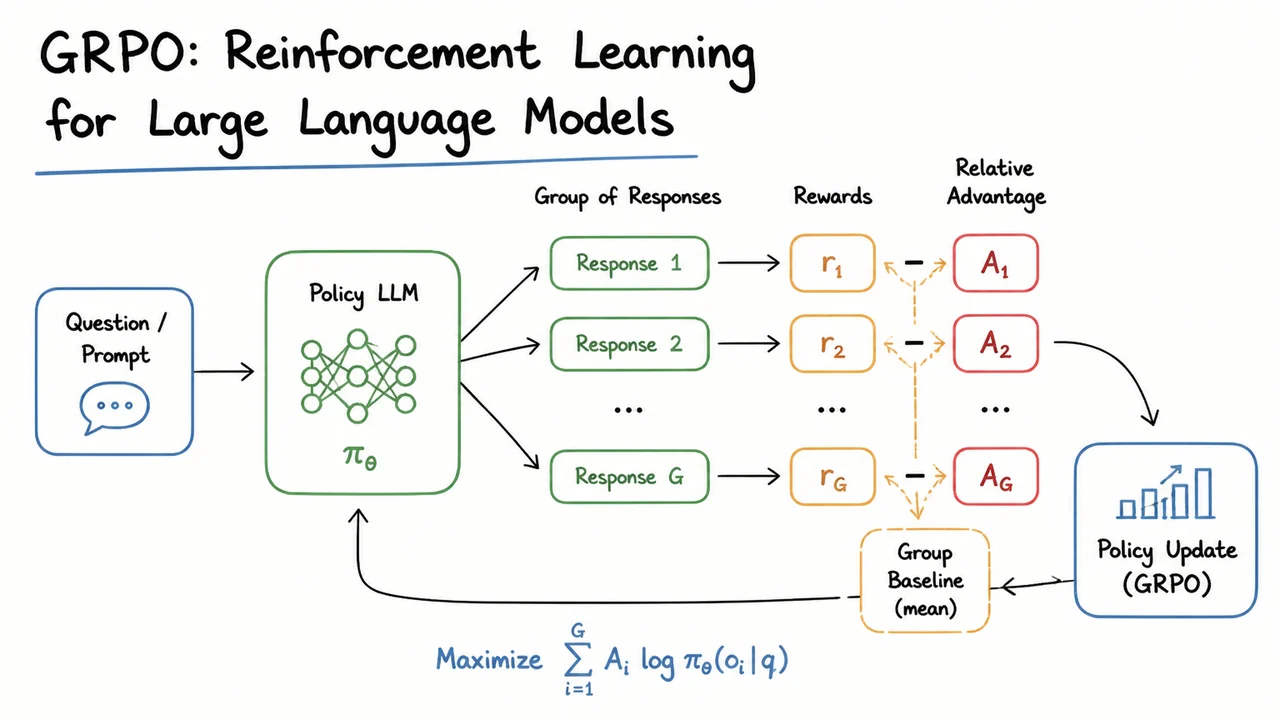
This bottleneck motivates a search for value‑free alternatives. Group Relative Policy Optimisation (GRPO) is a recent method that dispenses with the learned value function entirely. It works by sampling a group of responses for each prompt, scoring them all with the reward model, and then computing a relative advantage for each response by comparing its reward to the group mean and standard deviation. The policy is updated to favor responses that are better than average within their local group, while still constrained by a KL penalty relative to the reference policy. This replaces the global value‑baseline of PPO with a local, prompt‑specific baseline computed from the batch itself, dramatically simplifying the training pipeline and reducing the memory and compute footprint.
The lecture unfolds along a clear arc. We begin by revisiting the essentials of RL for text generation—policy gradient, PPO, and the role of the value function. Then we examine the standard PPO–RLHF pipeline in detail, highlighting its reliance on a separately trained value model. From there we diagnose the bottlenecks that appear when scaling value‑based methods to large models, which sets the stage for GRPO as a value‑free alternative. Finally, we compare the empirical performance of GRPO against PPO on mathematical reasoning benchmarks and discuss open questions around stability and reward hacking.
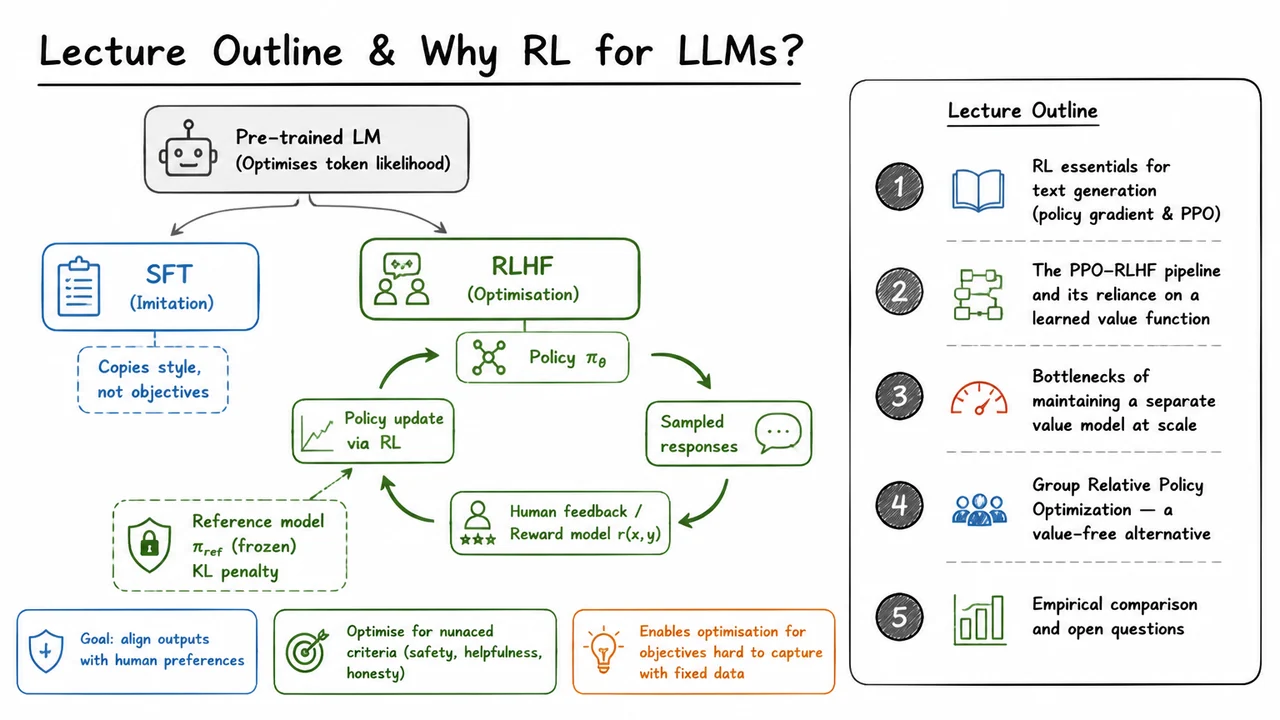
The visual below consolidates these ideas. On the left, two parallel pathways branch out from the pre‑trained language model: one labeled SFT (copy style, not objectives) and another labeled RLHF, which expands into a closed loop—policy sampling, reward evaluation, and an update that balances the reward signal against a KL penalty from the frozen reference model. On the right, a vertical outline charts the lecture’s progression from RL fundamentals through the value‑function bottleneck to the value‑free GRPO alternative, mirroring the conceptual journey we have just traced. This diagram gives you a mental map of where we are headed, and each component will be unpacked in depth as we move through the sections.