Harness Engineering: Building Reliable Evaluation and Data Pipelines for ML Systems
1. What Problem Does a Harness Solve?
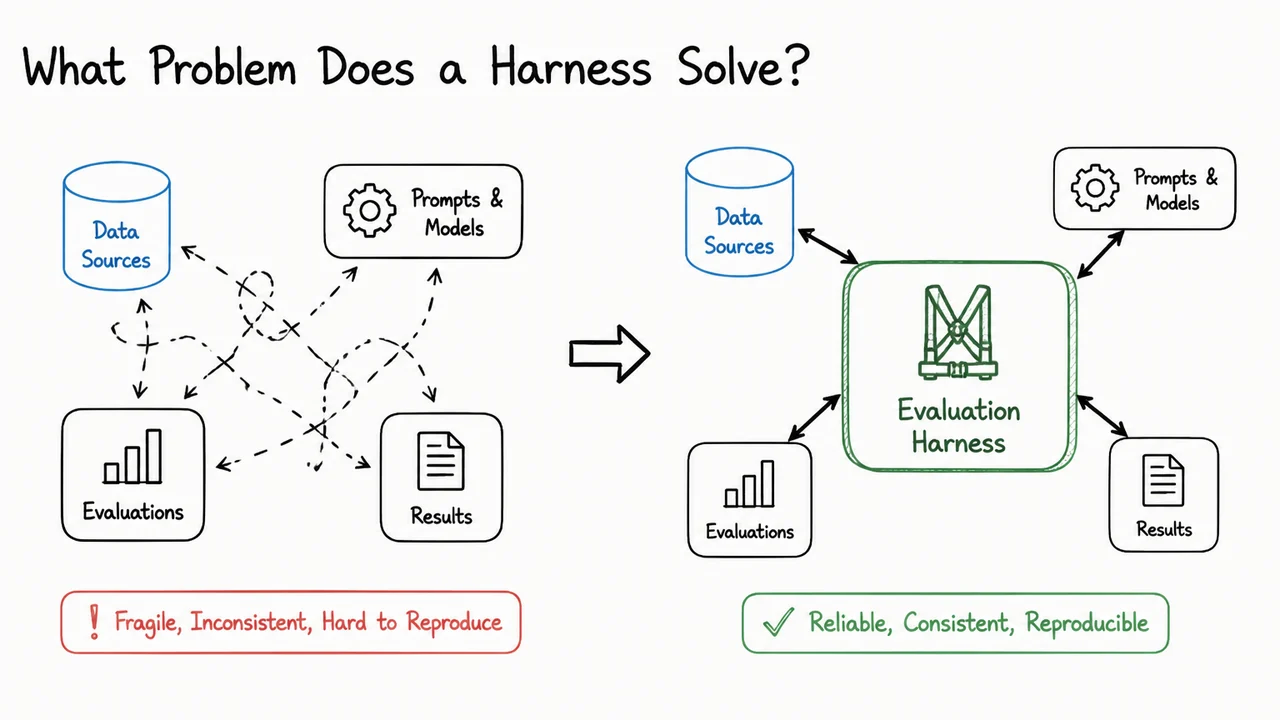
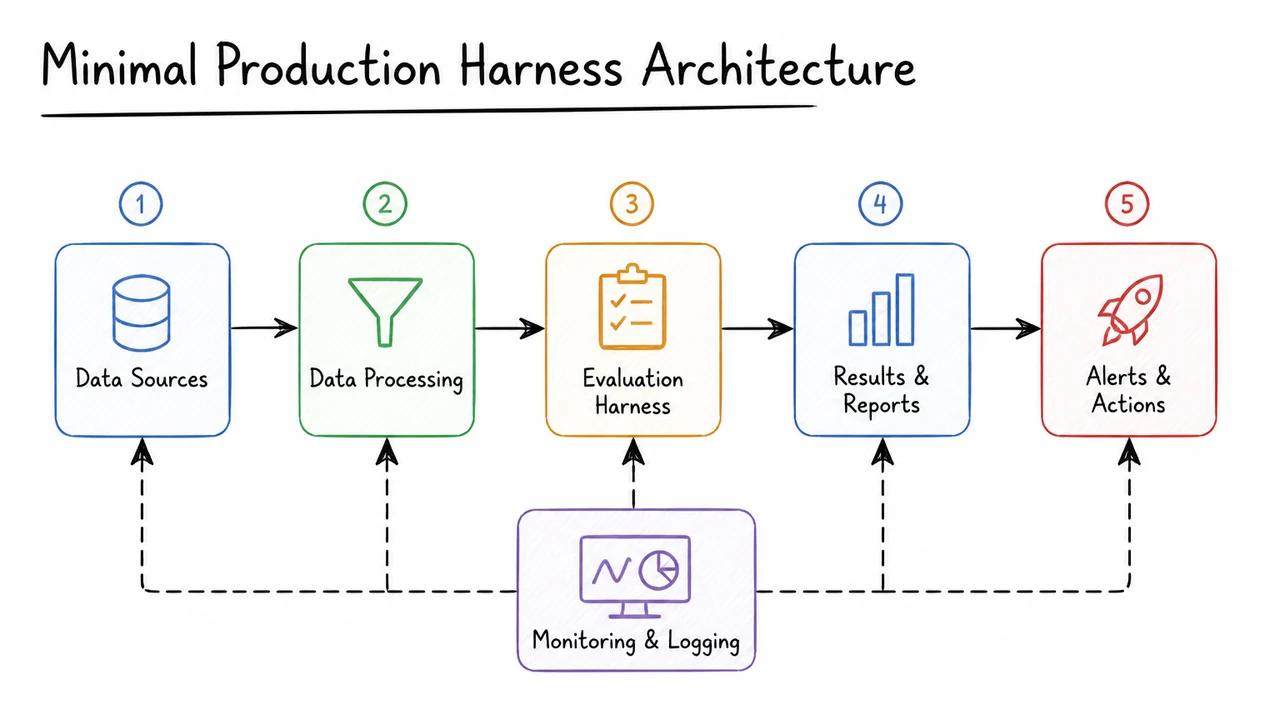
When an ML system starts producing numbers that people trust, the question is no longer just “does the model work?” It becomes “can we reliably tell when it works, why it works, and whether a change improved it or merely changed the measurement process?” That is the problem a harness solves. A harness is the controlled scaffold around the model: it fixes the inputs, the environment, the random seeds, the data splits, the metric computation, and the logging path so that evaluation becomes a system property rather than an accident of whatever script happened to run that day.
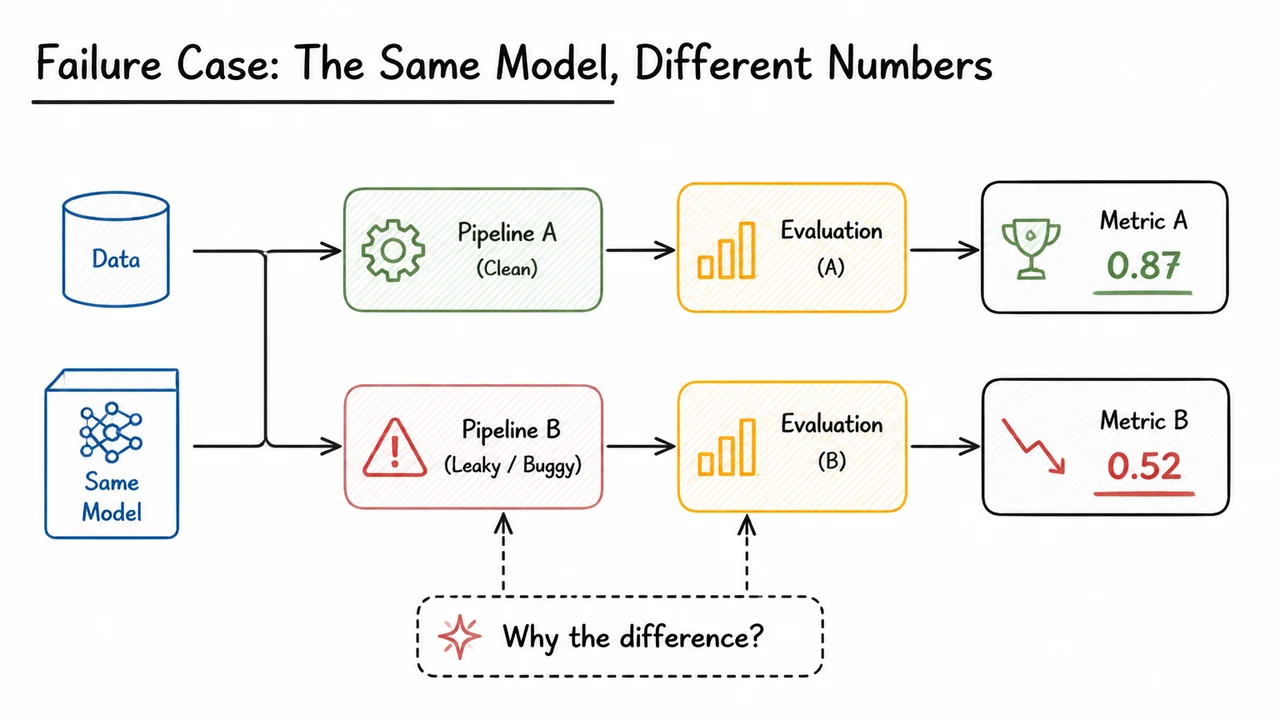
This matters because most apparent model progress is fragile. If a result depends on an unstated preprocessing step, a silently changed dataset version, a different CUDA kernel, or even a different order of examples, then the metric is not measuring only the model. It is measuring the entire execution context. In that sense, a harness is the boundary between model behavior and measurement noise. Without that boundary, training and evaluation can drift together, and a “better” score may simply mean the pipeline changed in a favorable way.
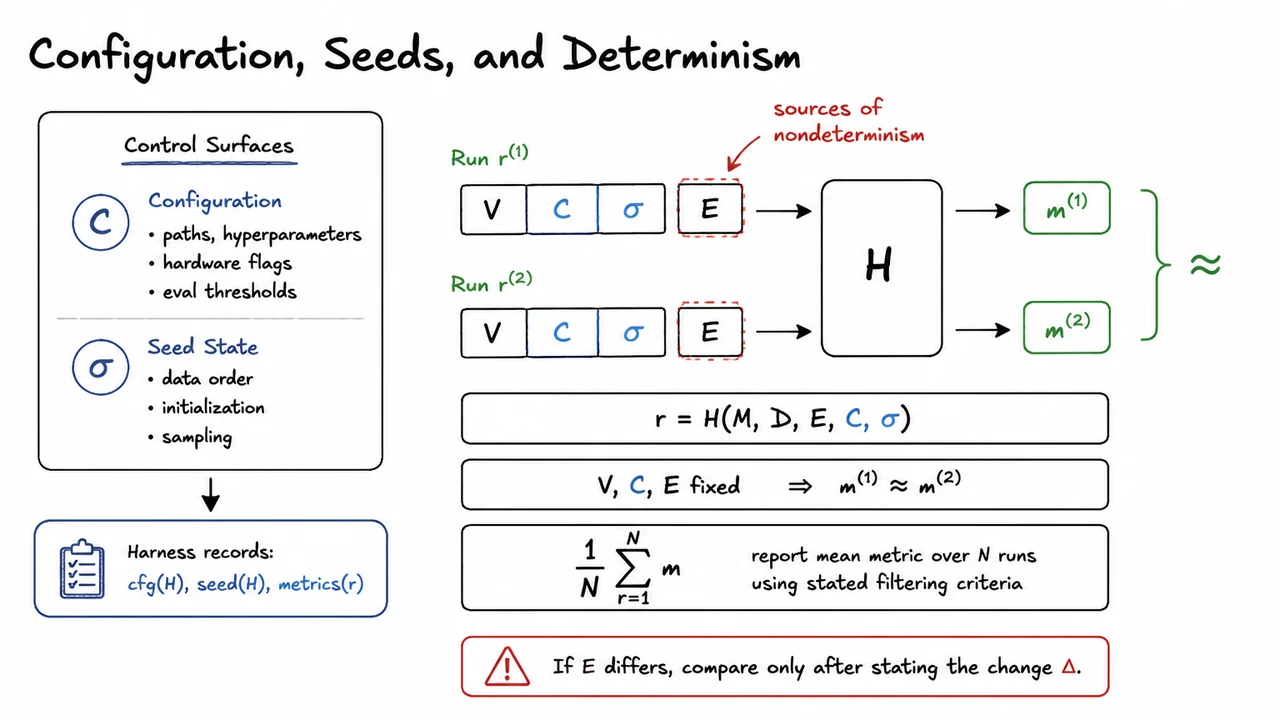
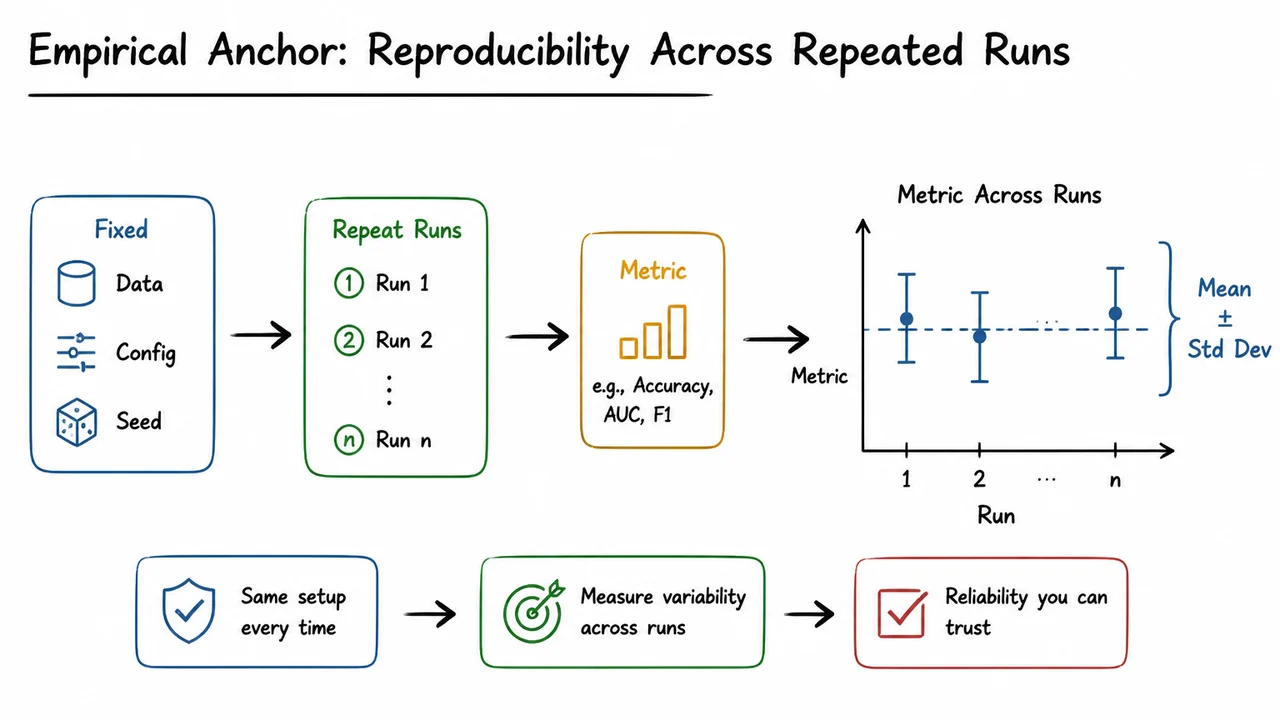
The core idea is simple: a harness makes the evaluation problem closed. Given the same model artifact and the same dataset artifact, the harness should produce the same outputs, the same metrics, and the same logs. Formally, if we write the model as and the evaluation pipeline as , then we want to be stable under repeated runs, where is the data artifact and captures configuration and environment. The practical version of this requirement is reproducibility: if the run cannot be replayed, the metric cannot be trusted as evidence of improvement.
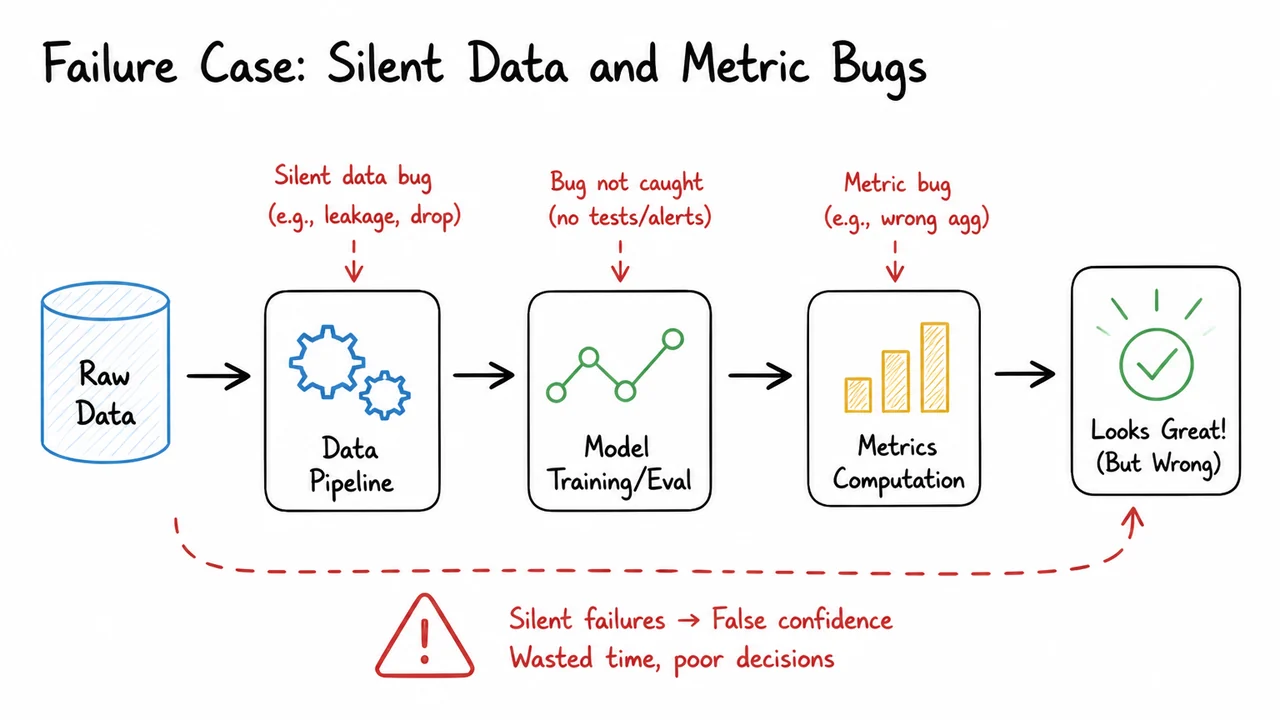
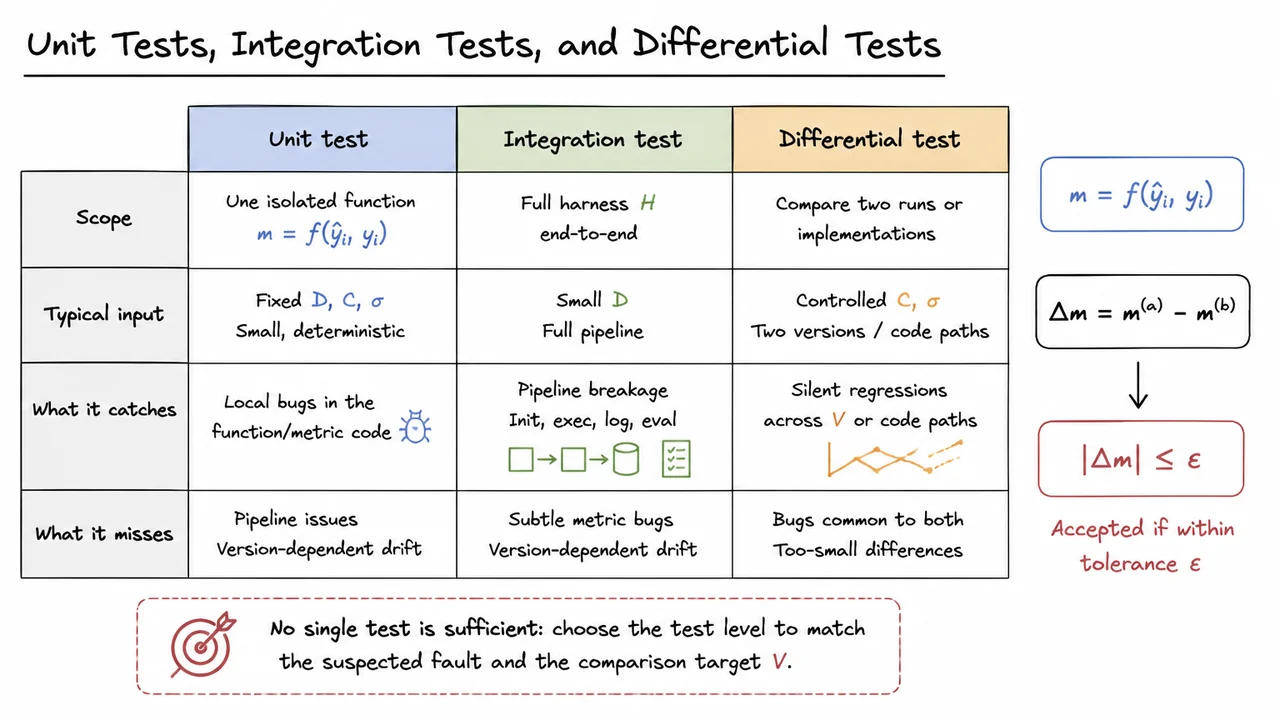
There are several distinct sources of noise that a good harness isolates. Some are obvious, like random seeds in initialization, shuffling, augmentation, or batched sampling. Others are more subtle: nondeterministic GPU operations, different library versions, changes in tokenization, schema drift in input data, or metric code that averages over a different subset than intended. A robust harness treats each of these as a failure mode to be controlled, not as an implementation detail to be hoped away.
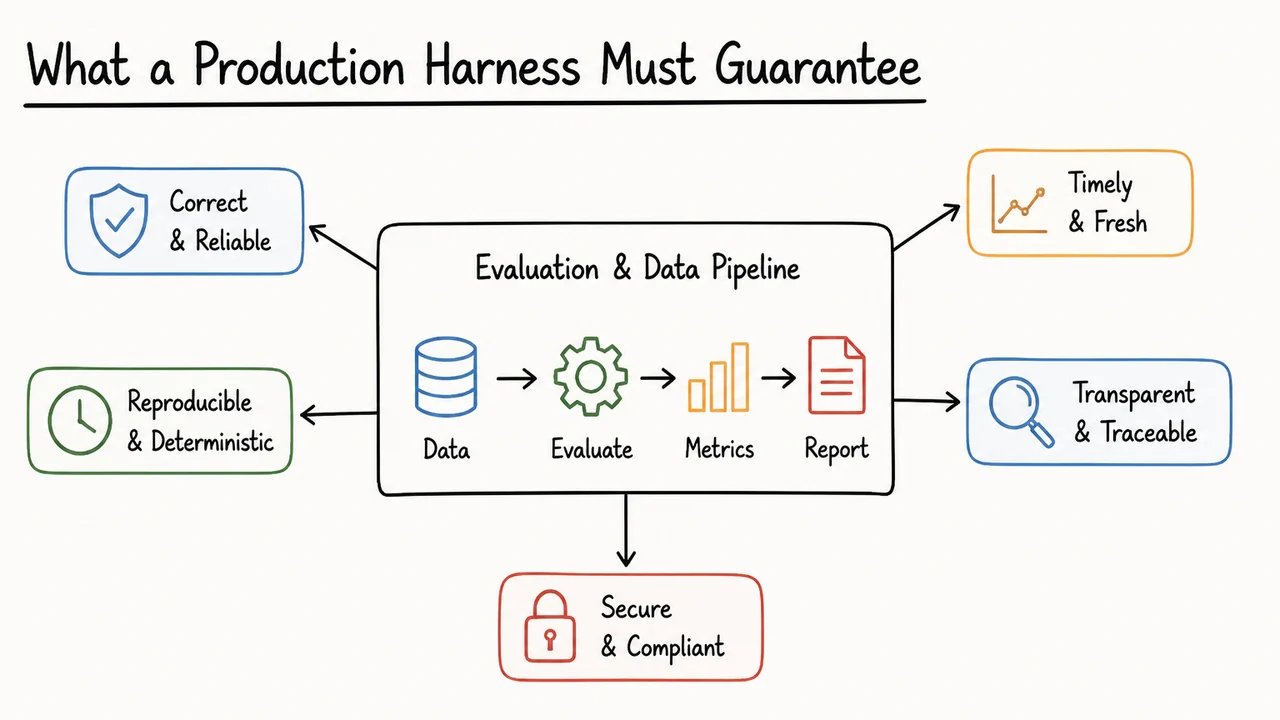
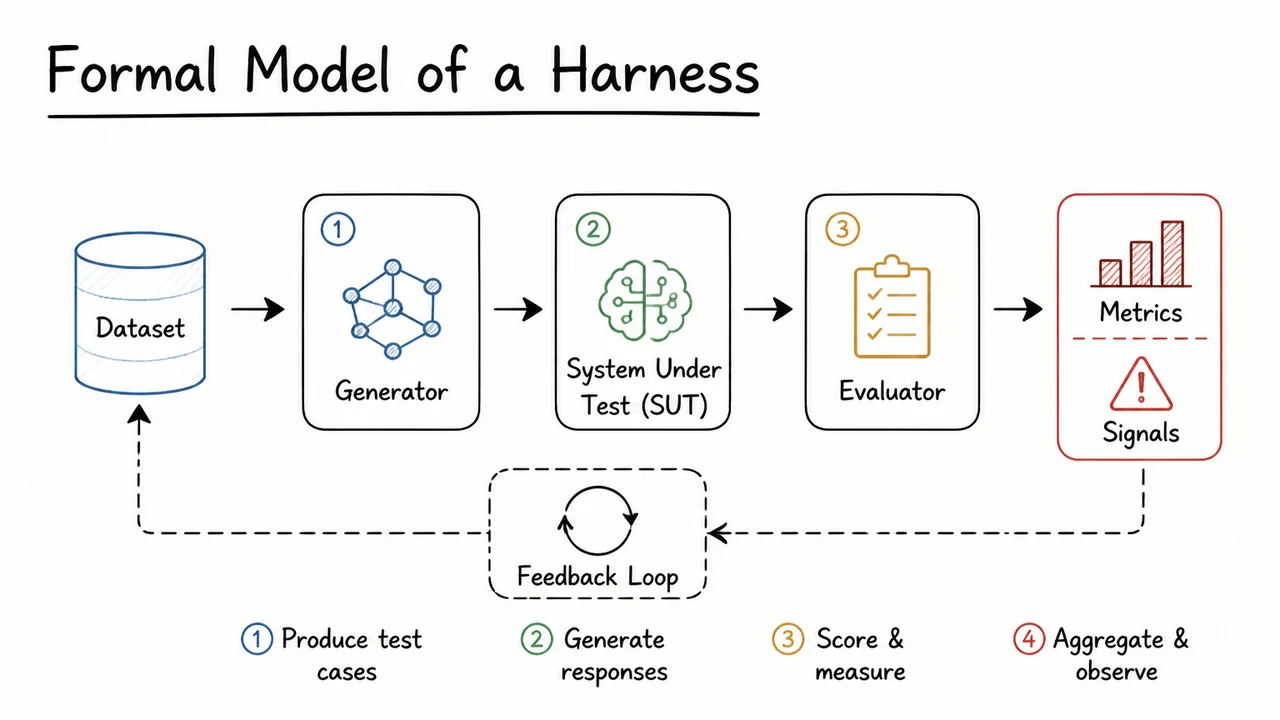
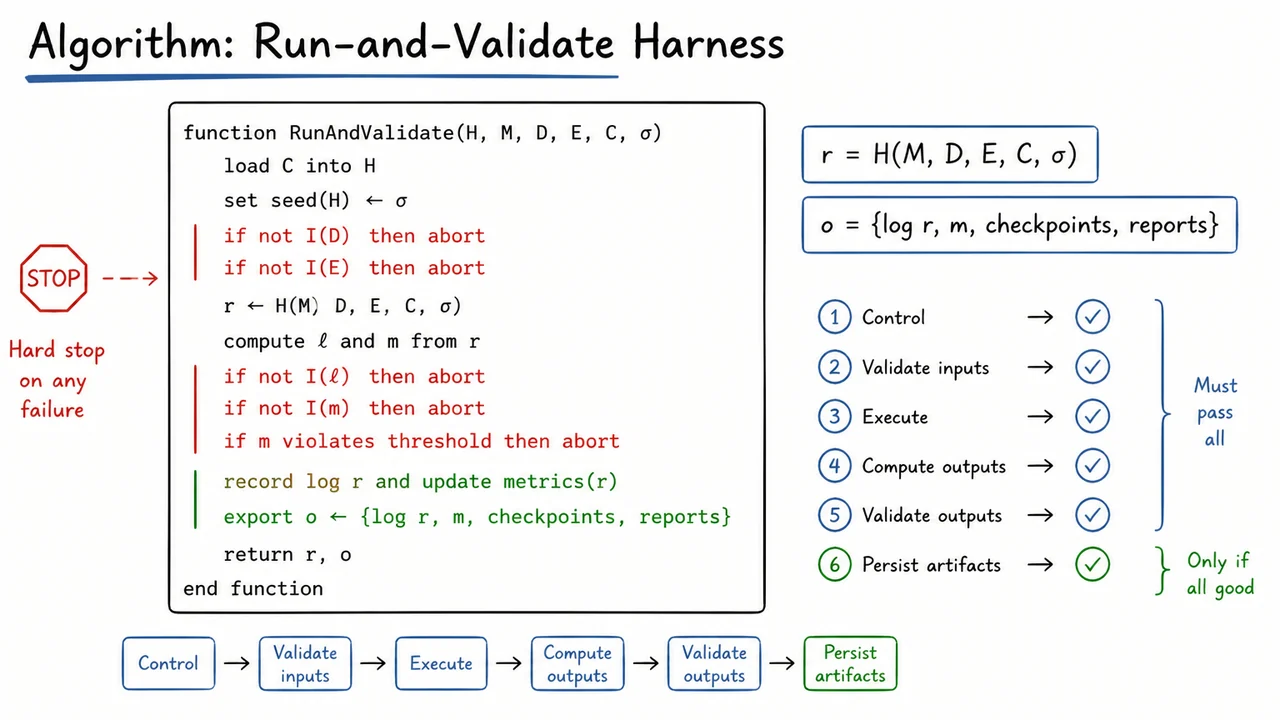
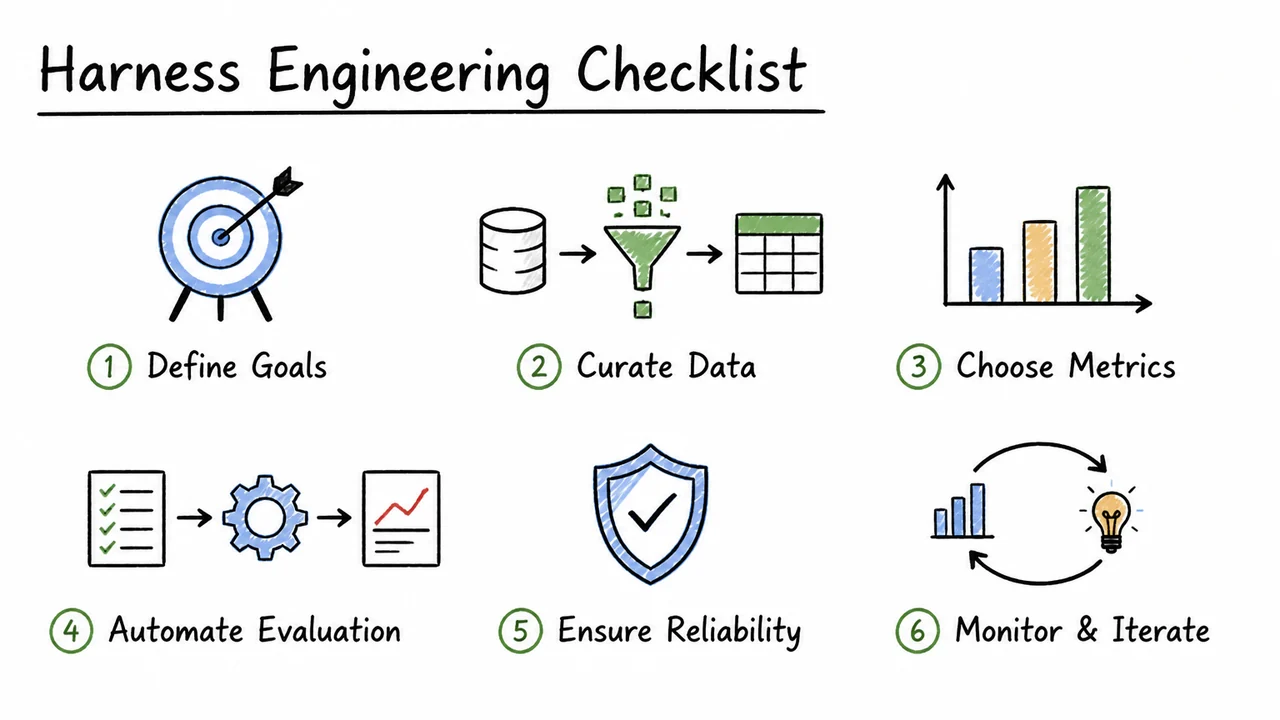
A useful way to think about the harness is as a small contract with five parts:
- Configuration: what model, data, and metric settings are being used.
- Seeding: what randomness is allowed, and how it is made repeatable.
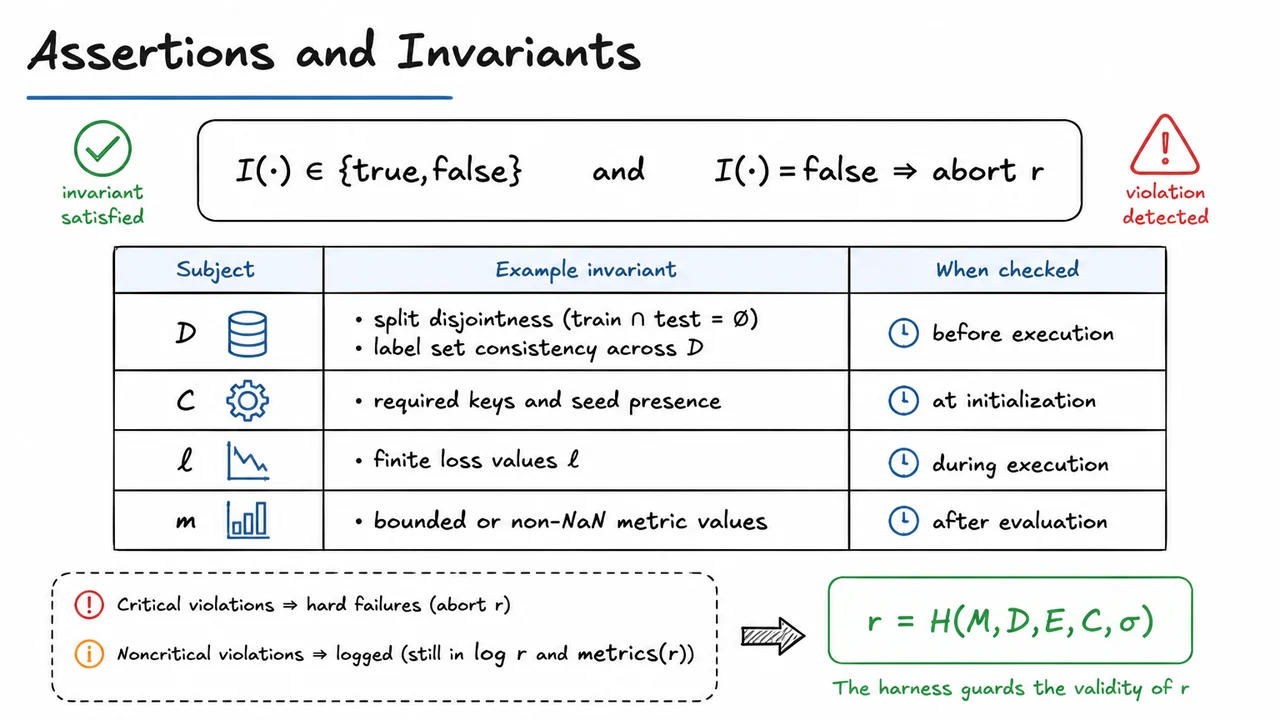
- Assertions: what invariants must hold before and after execution.
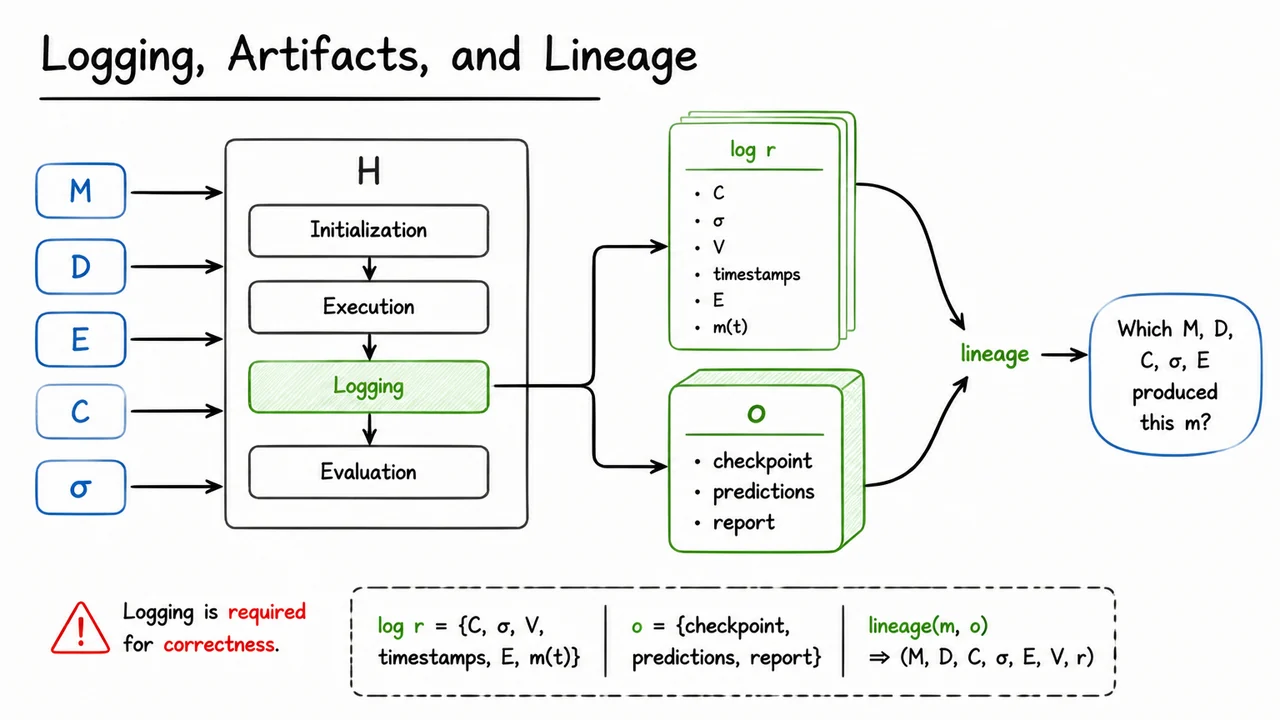
- Logging: what evidence is recorded for later inspection.
- Versioning: what exact code, data, and environment produced the result.
Each piece exists because a different kind of confusion can otherwise sneak into the workflow. Configuration prevents ambiguity about “which run” we are discussing. Seeding prevents stochastic drift from masquerading as progress. Assertions catch invalid inputs early, before they become believable metrics. Logging makes the run auditable. Versioning lets us re-create the run months later, which is essential once a metric becomes part of a launch decision or regression analysis.
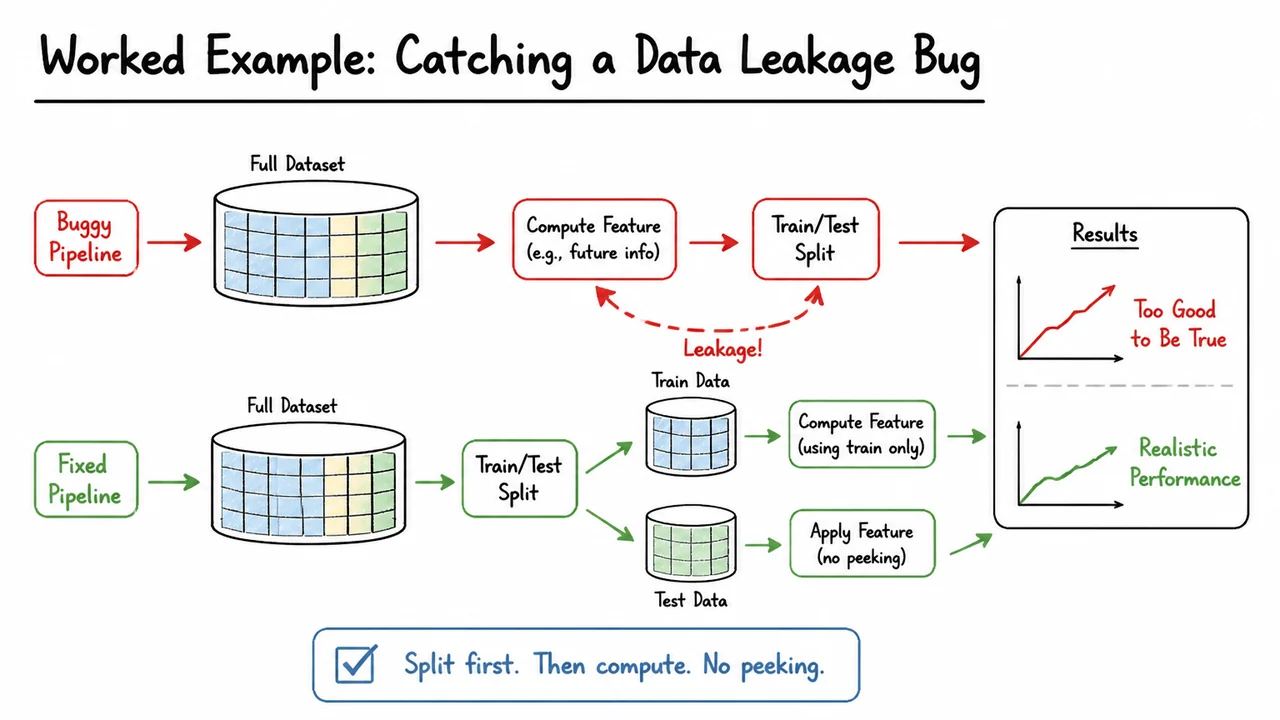
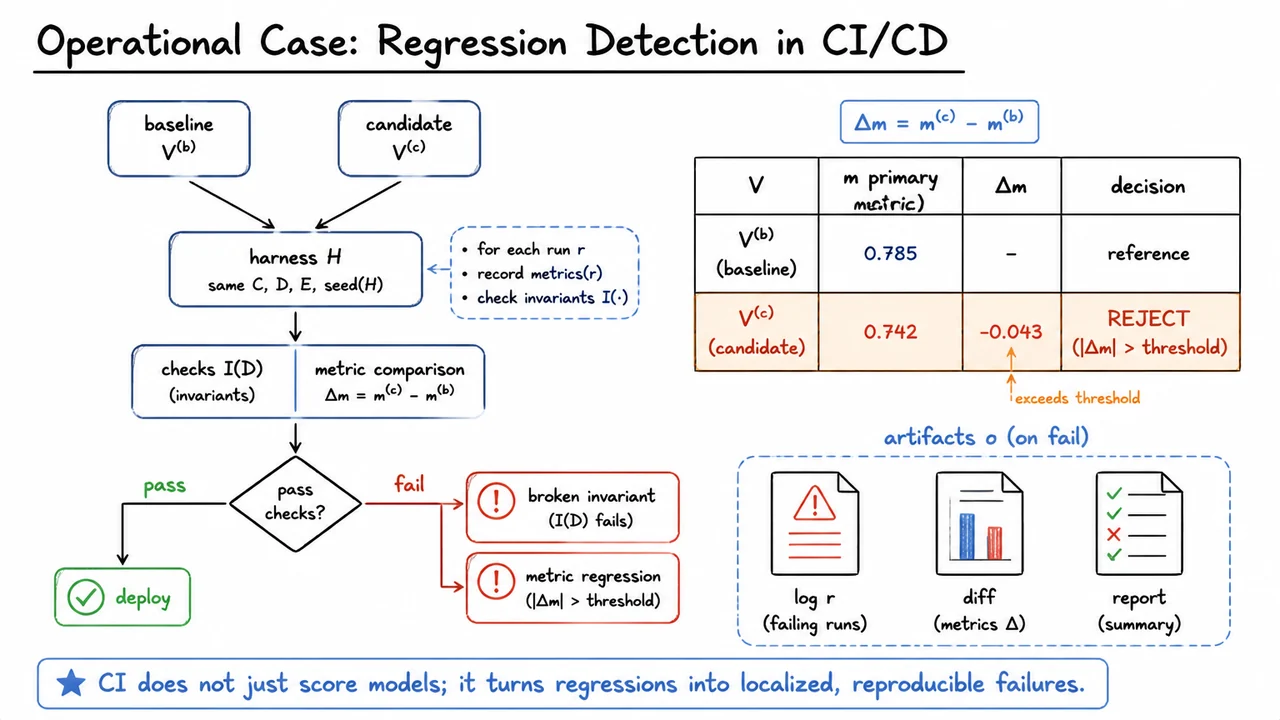
The subtle point is that harness engineering is not mainly about convenience; it is about epistemic control. In an ML system, the model is only one component in a larger causal chain. If the chain is unstable, then the score is not a reliable observation. That is why harness failures are often expensive: they produce false confidence, delayed bugs, and difficult postmortems. A small leak in the harness can make an offline experiment look like a genuine gain when it was really caused by data leakage, changed normalization, or a metric mismatch.
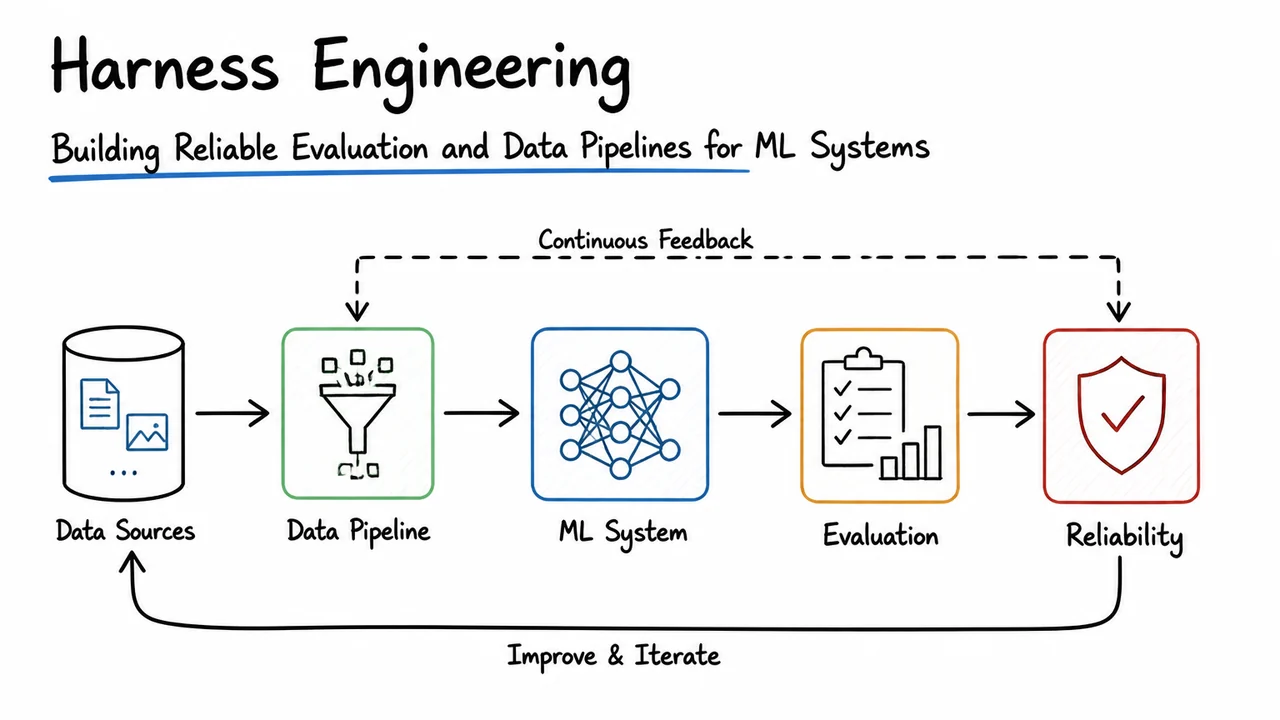
Put differently, the harness converts an ML workflow from an improvised experiment into a repeatable measurement apparatus. In the same way that a lab instrument must be calibrated before its readings mean anything, an evaluation harness must be calibrated around the model and dataset before its numbers deserve interpretation. The better the harness, the less time engineers spend asking whether the result is “real” and the more time they can spend asking the more interesting question: what changed in the model, and why did it help?
The visual below is a compact summary of that idea. The central model is not surrounded by decoration; it is surrounded by the things that usually distort measurement. That framing makes the key point visible at a glance: a harness is the controlled interface between a model and the messy world around it. The arrows, boundaries, and labeled safeguards are there to emphasize that reliable evaluation is not a property of the model alone, but of the entire path from inputs to metrics.
Seen this way, the diagram is not just a schematic. It is evidence for the argument that harness engineering is a first-class ML systems problem. The model sits in the middle, but the real engineering challenge is to ensure that everything around it is stable enough that the resulting number means what we think it means.