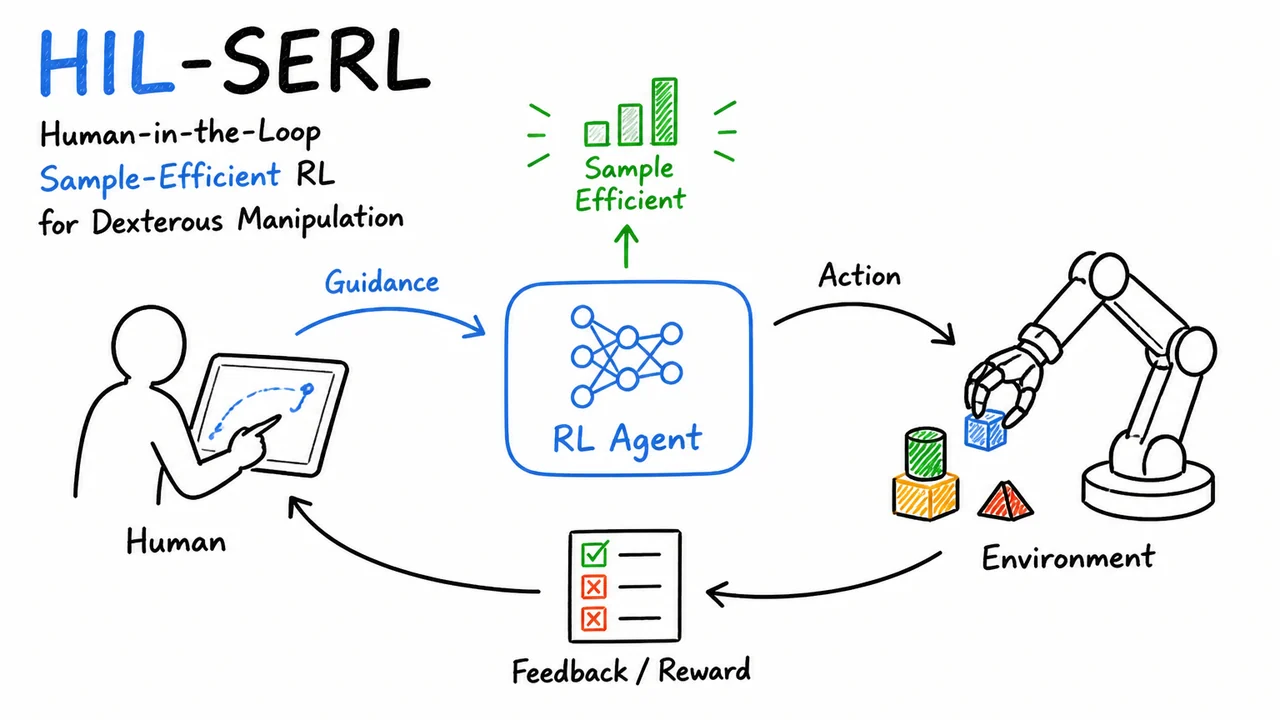
HIL-SERL: Human-in-the-Loop Sample-Efficient Robotic Reinforcement Learning for Dexterous Manipulation
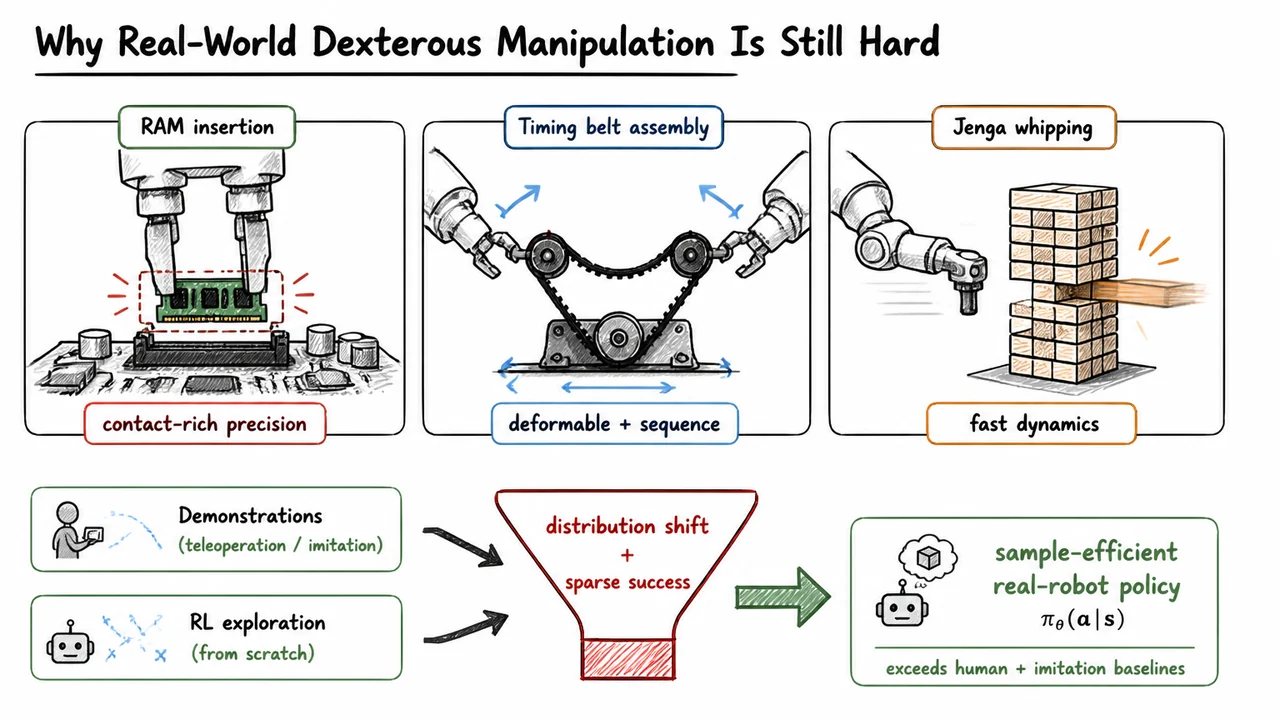
1. Why Real-World Dexterous Manipulation Is Still Hard
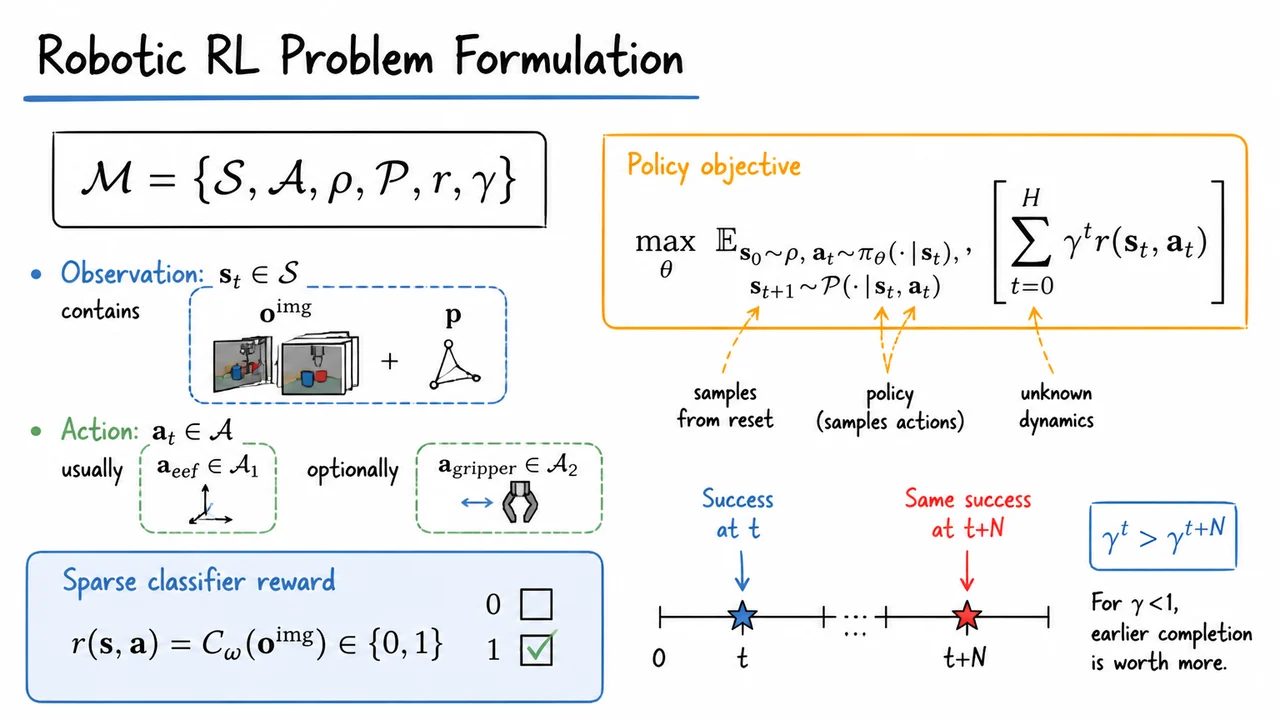
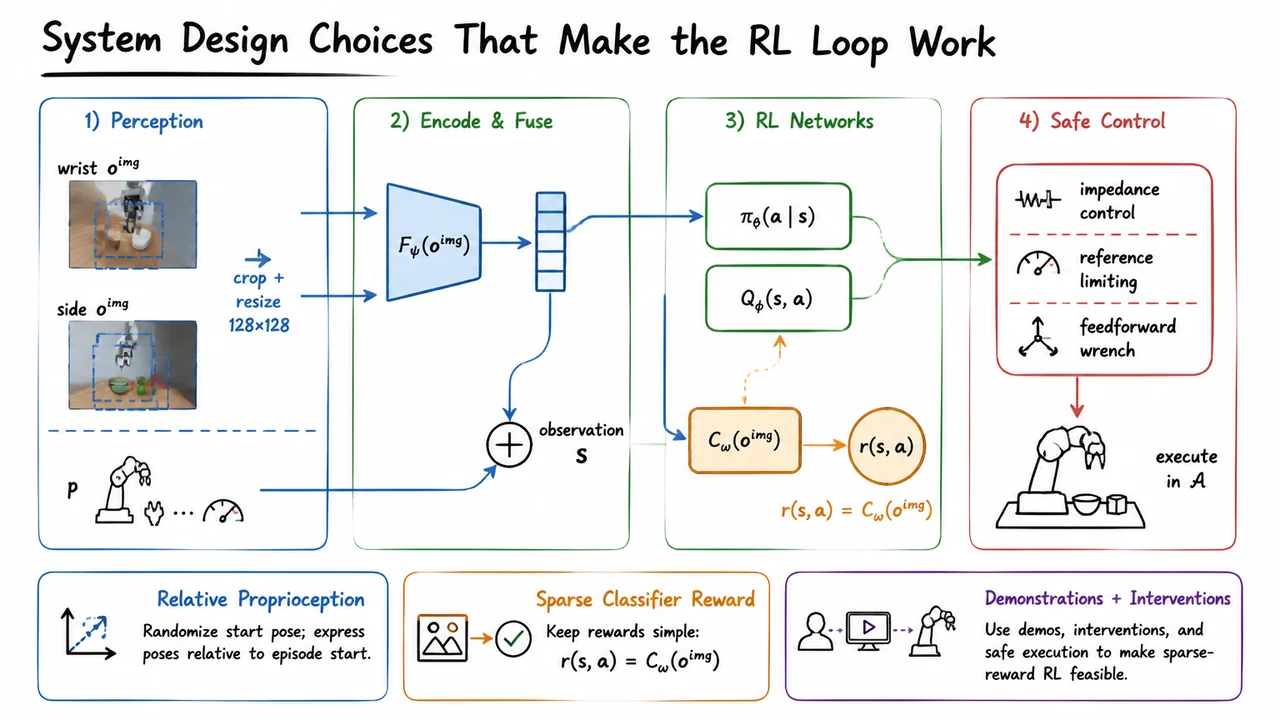
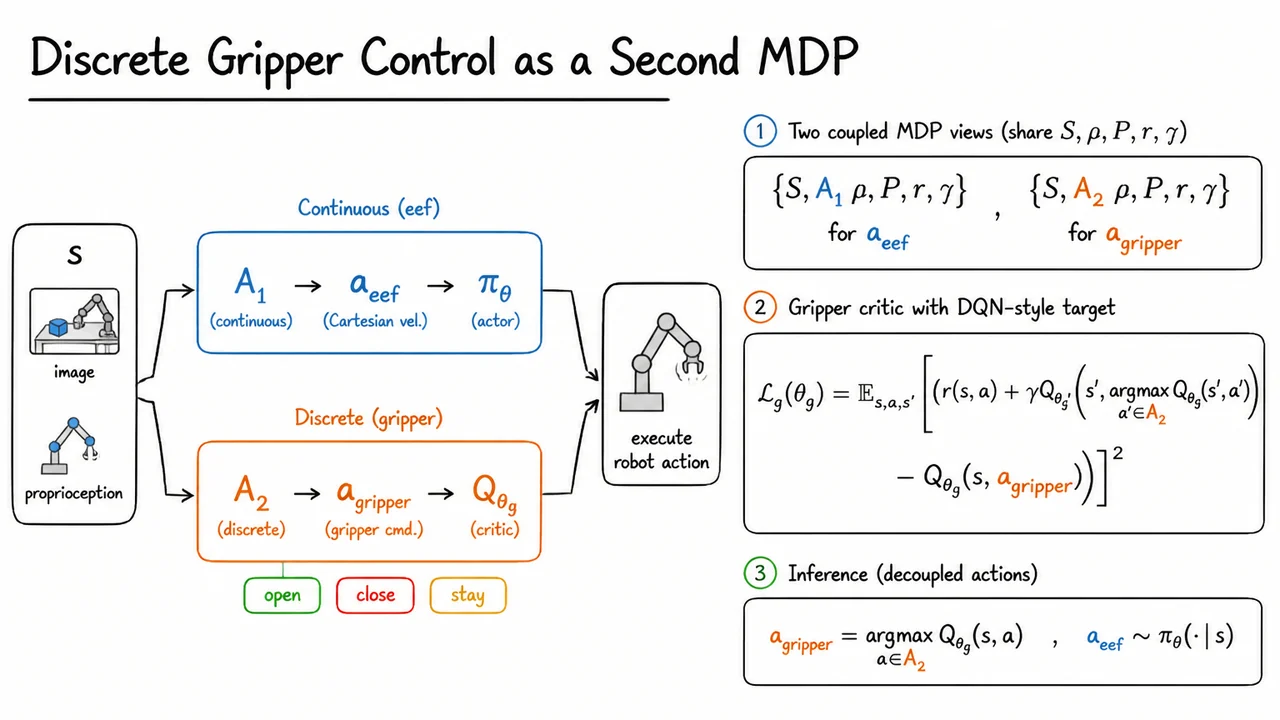
To understand why HIL-SERL is interesting, it helps to start with the uncomfortable reality of real robot learning: many manipulation tasks that look simple to a human are not simple from the perspective of a vision-based control policy. The robot does not receive a clean symbolic state like “the RAM stick is aligned” or “the belt has the right tension.” It sees pixels, proprioception, noisy contacts, deforming objects, and delayed consequences of earlier actions. The policy we ultimately want is something like : given the current observation , choose an action . But in real-world dexterous manipulation, the important parts of are often subtle, partially hidden, and strongly coupled to contact dynamics.
Consider RAM insertion. The task is conceptually straightforward: align a module with a socket and push it in. But physically, it is contact-rich and unforgiving. A millimeter-scale pose error can cause the part to jam, tilt, or scrape against the slot. The policy must not merely reach a visually plausible pose; it must regulate force, orientation, and insertion trajectory under uncertainty. The difference between success and failure may be a tiny correction during contact, not a large visible motion before contact.
Now compare that with timing belt assembly. Here, the difficulty is not just precision, but deformation and sequencing. A belt must be stretched around pulleys, which means its state is distributed across a flexible object. Success depends on maintaining tension while coordinating two arms or contact points. If the robot releases tension too early, approaches the wrong pulley first, or pulls along an unhelpful direction, the belt may slip or fold. The policy must learn a temporally extended strategy, not just a static target pose.
Then there are tasks like Jenga whipping, where the robot must perform a fast dynamic maneuver. Unlike slow quasi-static manipulation, dynamic manipulation has narrow timing windows. If the end-effector strikes too early, too late, too softly, or at the wrong angle, the block may not exit cleanly. Worse, many failures are unrecoverable: once the tower collapses or the block shifts incorrectly, the episode is essentially over. The robot needs a policy that is reactive enough to handle variation, but also predictive enough to commit to a fast motion before all consequences are visible.
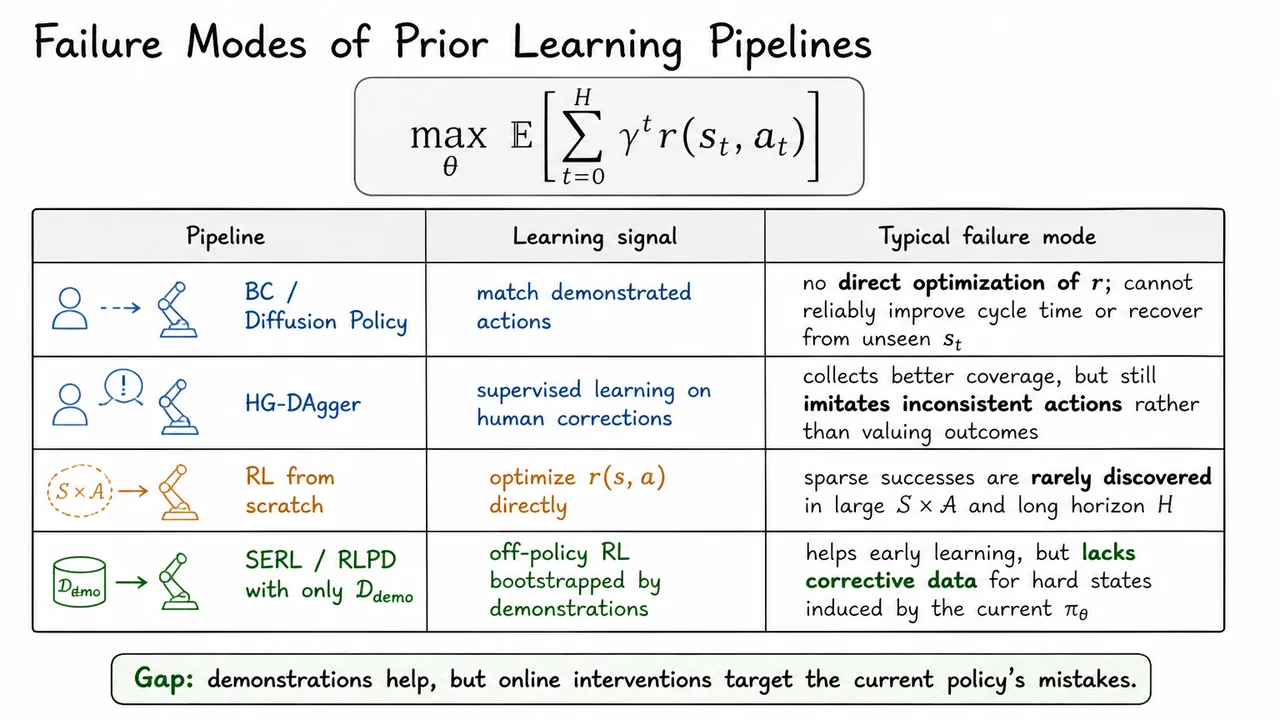
These examples expose a weakness of straightforward behavioral cloning. If a human teleoperator provides successful demonstrations, supervised imitation can learn to reproduce the average-looking behavior on states similar to those demonstrations. But the learned policy is usually trained only on the state distribution induced by the human, not on the distribution induced by its own mistakes. Once the robot drifts slightly off the demonstrated trajectory, it may encounter grasps, contacts, object poses, or timing regimes that were rare or absent in the dataset. This is the classic distribution shift problem: small errors compound, and the policy is asked to act in states where its supervised labels are unreliable or nonexistent.
A useful way to summarize the imitation failure mode is:
- Demonstrations are informative, because they show what successful behavior can look like.
- Demonstrations are narrow, because they mostly cover states reached by a competent human.
- Autonomous execution is broader, because the learned policy visits its own error states.
- Recovery behavior is essential, but often underrepresented in nominal demonstrations.
Reinforcement learning from scratch has the opposite problem. In principle, RL can learn from its own experience and improve beyond the demonstrator. It can discover recovery strategies, exploit the robot’s embodiment, and optimize directly for task success rather than matching human actions. But in real-world vision-based manipulation, naive exploration is brutally inefficient. The action space is continuous, the observation space is high-dimensional, and rewards are often sparse: the robot may receive meaningful positive feedback only after completing the task. If random or weakly guided exploration almost never succeeds, the agent has little signal from which to learn.
This creates the central tension. Imitation learning gives the robot a reasonable starting point, but tends to be brittle under off-distribution contacts and timing errors. Reinforcement learning can in principle correct those mistakes, but starting from nothing on a physical robot is too slow, too costly, and sometimes unsafe. What we need is a method that uses human knowledge without reducing it to static supervised labels, and that uses reinforcement learning without requiring enormous amounts of unguided real-world trial and error.
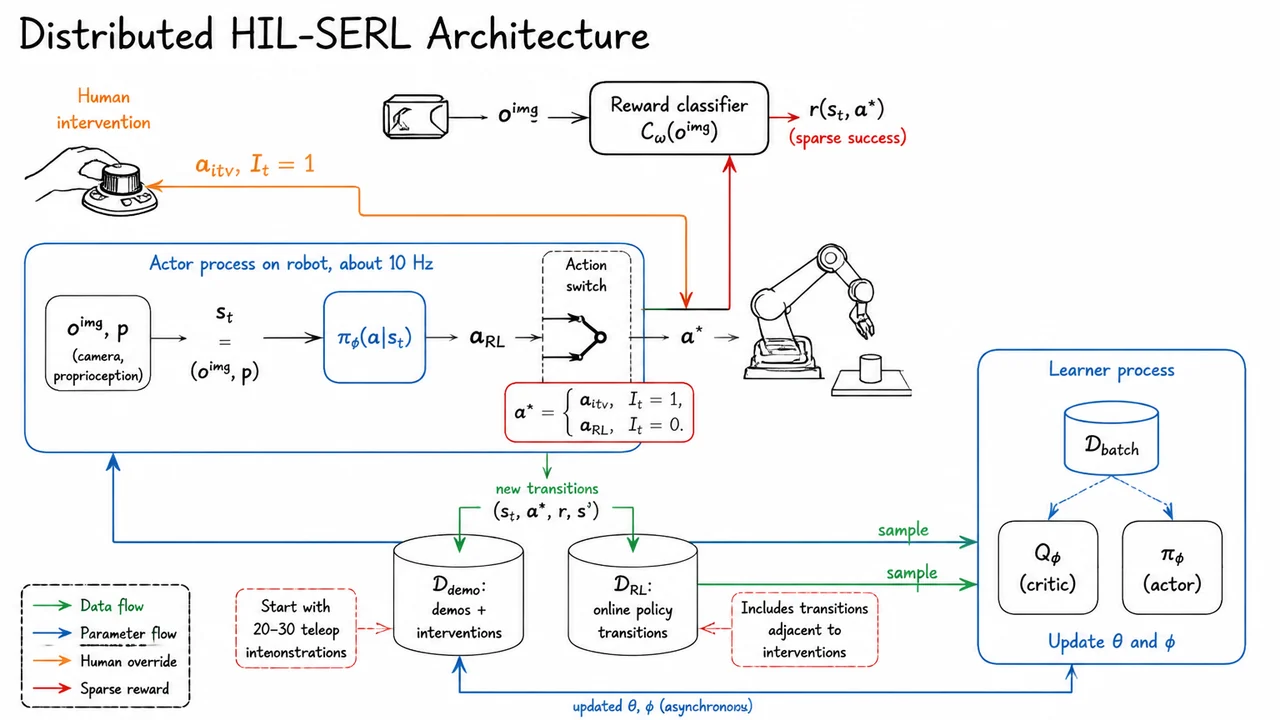
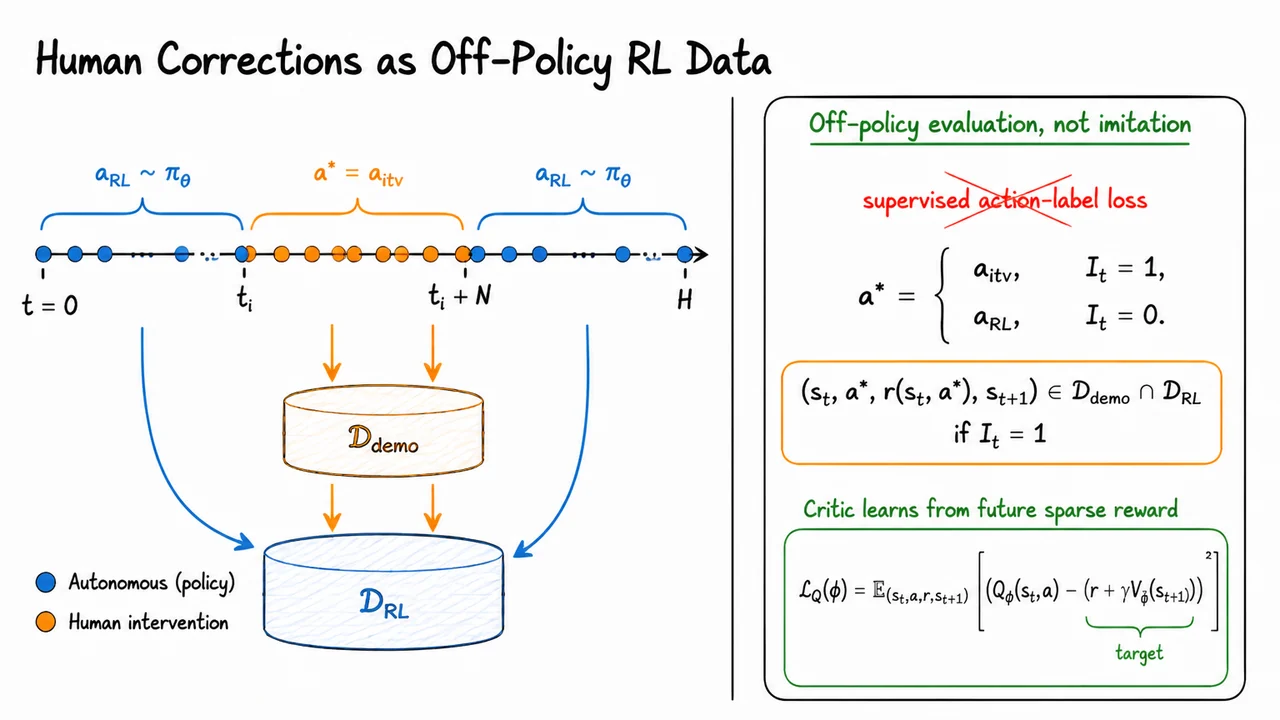
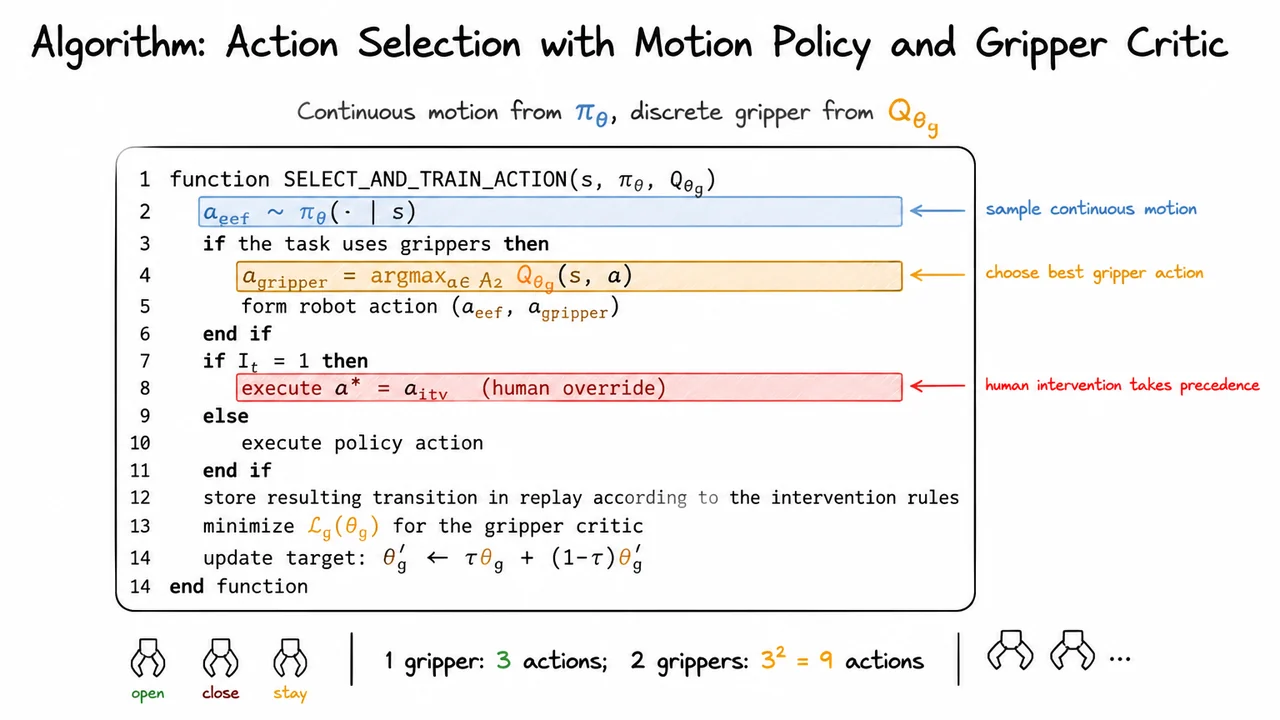
That is the problem setting for HIL-SERL: learn a real-robot, vision-based manipulation policy within practical training time, while eventually exceeding both pure teleoperation and pure imitation baselines. The phrase “human-in-the-loop” is important here, but the key idea is not simply “ask the human for more labels.” The deeper goal is to make human interventions part of an off-policy reinforcement learning process, so that the robot can learn from corrections, failures, recoveries, and successful autonomous experience together.
The visual below compactly organizes this motivation around three representative tasks: one dominated by contact precision, one by deformable bimanual sequencing, and one by fast dynamics. These are not just three benchmark names; they correspond to three different ways real-world manipulation breaks simplistic learning assumptions. A policy that only memorizes nominal trajectories will struggle when contact geometry, object deformation, or timing deviates from the demonstrations.
The bottom funnel summarizes the learning dilemma. Demonstrations and RL exploration are both valuable, but each encounters a bottleneck: distribution shift for imitation and sparse success for scratch RL. HIL-SERL’s motivation is to pass through that bottleneck by combining human guidance with sample-efficient off-policy RL, producing a policy that is not merely a copy of the human, but a robust real-robot controller trained from the data the robot actually needs.