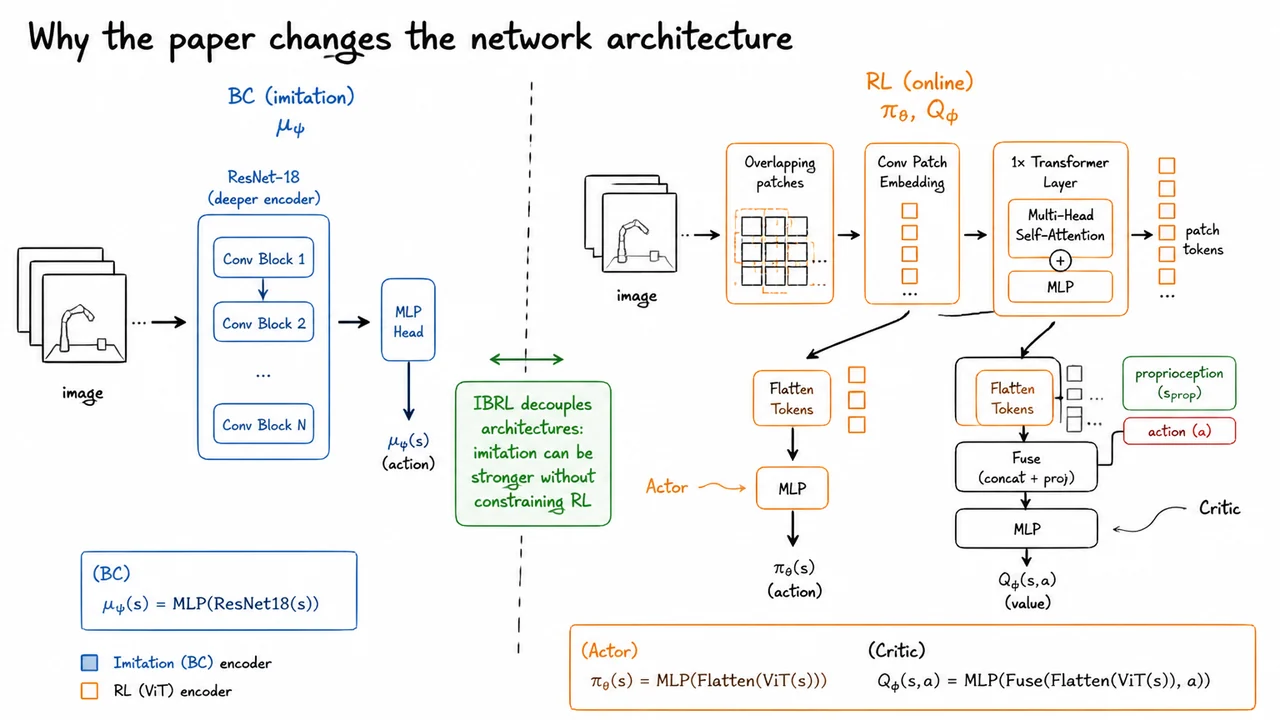
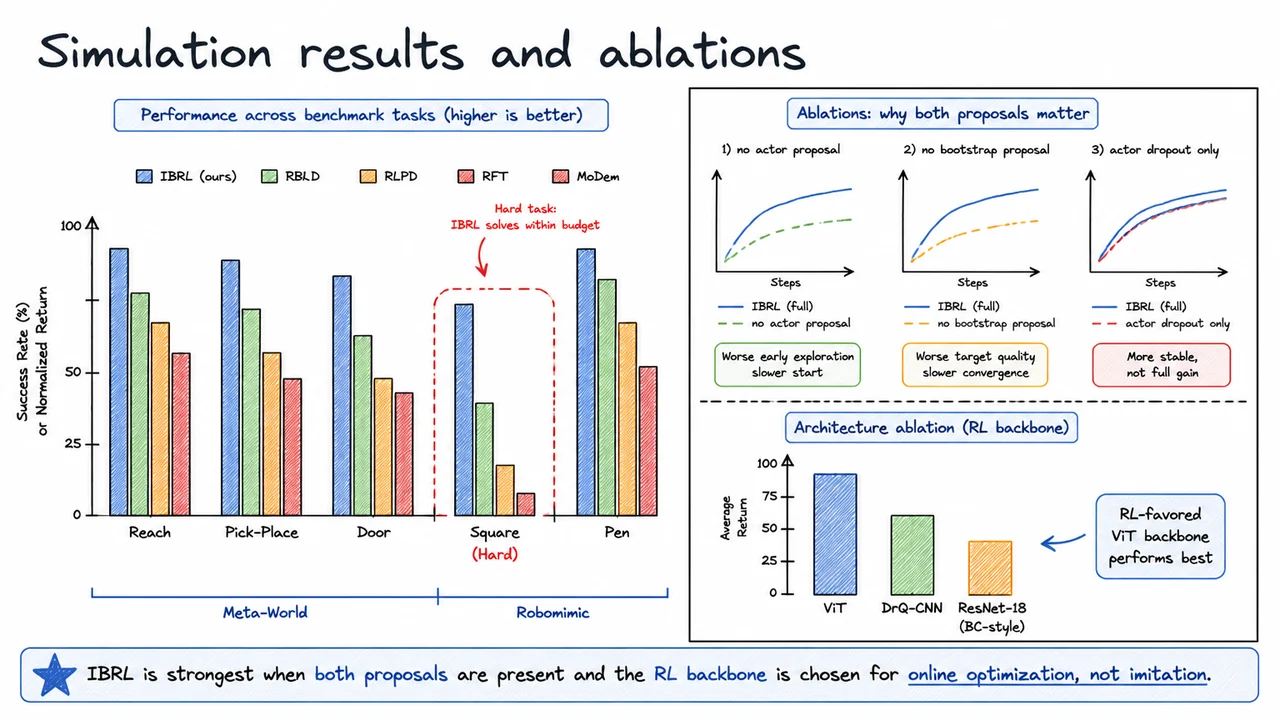
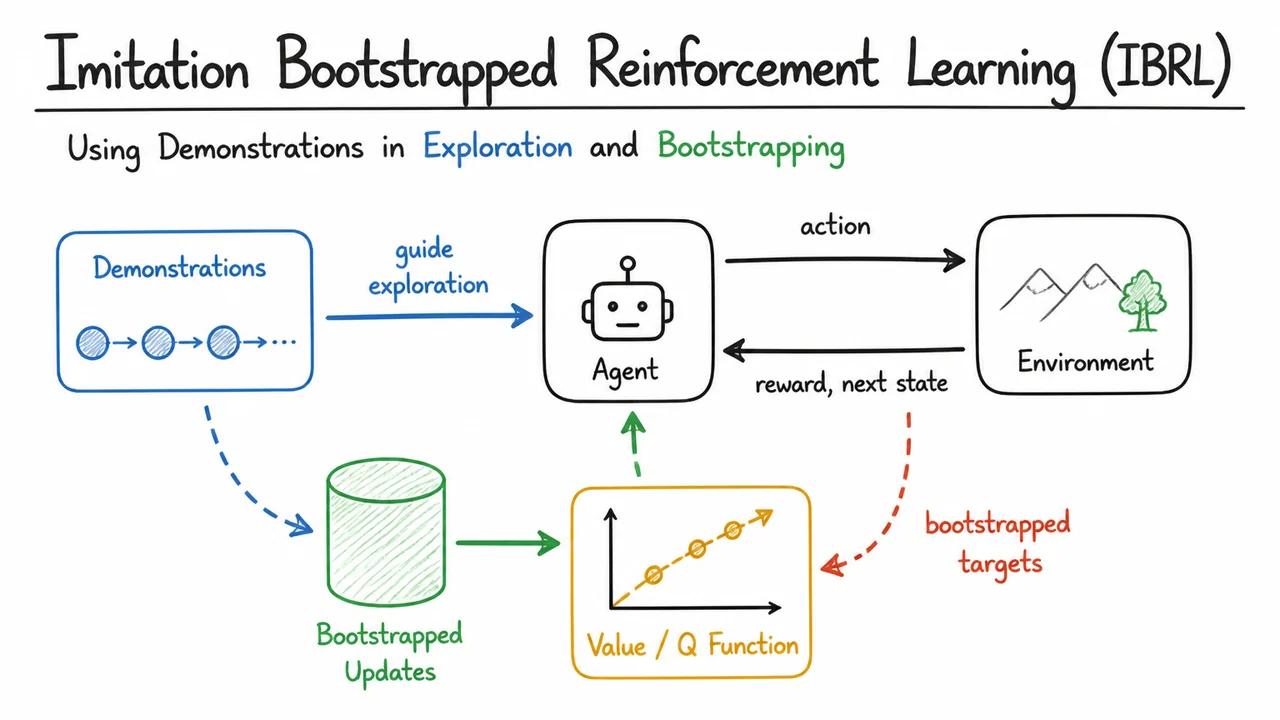
Imitation Bootstrapped Reinforcement Learning (IBRL): Using Demonstrations in Exploration and Bootstrapping
1. Why sparse-reward robotics is hard
A useful way to think about sparse-reward robotics is that the task is conceptually simple but statistically brutal. In the idealized MDP view, we have a state space , a continuous action space , and dynamics . The challenge is not that the formalism is complicated; the challenge is that the reward signal is almost absent. When and the appears only at true success, most trajectories are indistinguishable from one another for long stretches of time.
That has a very specific consequence for reinforcement learning. If the policy starts out randomly, then the agent explores a huge continuous action space with no meaningful guidance. In discrete domains, random exploration can sometimes stumble into informative events often enough to get learning started. In robotics, however, the geometry is much harsher: each action is a vector in , and the “correct” combination of forces, torques, or end-effector motions may occupy an extremely small region of that space. The probability of accidentally producing a successful trajectory can be tiny.
When success is that rare, the critic has almost nothing to learn from. Temporal-difference methods need nontrivial targets, but if nearly every rollout receives zero reward, then the estimated returns collapse toward zero as well. Formally, the bootstrapping signal becomes uninformative: the agent cannot reliably distinguish a slightly better trajectory from a slightly worse one because both look like failure. This is one of the most frustrating failure modes in sparse-reward RL: the algorithm is working as designed, but the data distribution contains almost no evidence of progress.
The problem is amplified by the fact that robotics is a sample-efficiency regime. We usually cannot depend on millions of parallel simulated episodes to brute-force our way into reward. Real robots are expensive, slow, and brittle; every rollout consumes time and may risk hardware wear. So even if random exploration is theoretically sufficient in the limit, it is often practically useless. The question is not whether learning could happen eventually, but whether it can happen before the robot runs out of data or patience.
There is also a subtler point hiding underneath the sparse-reward story: the transition dynamics may be deterministic, but determinism alone does not make exploration easy. A deterministic means the next state is fully determined by the current state and action, yet that does not tell us which actions matter. Without a reward gradient, the policy has no direct signal pointing toward the narrow subset of state-action pairs that eventually lead to success. In other words, the environment is predictable, but not legible.
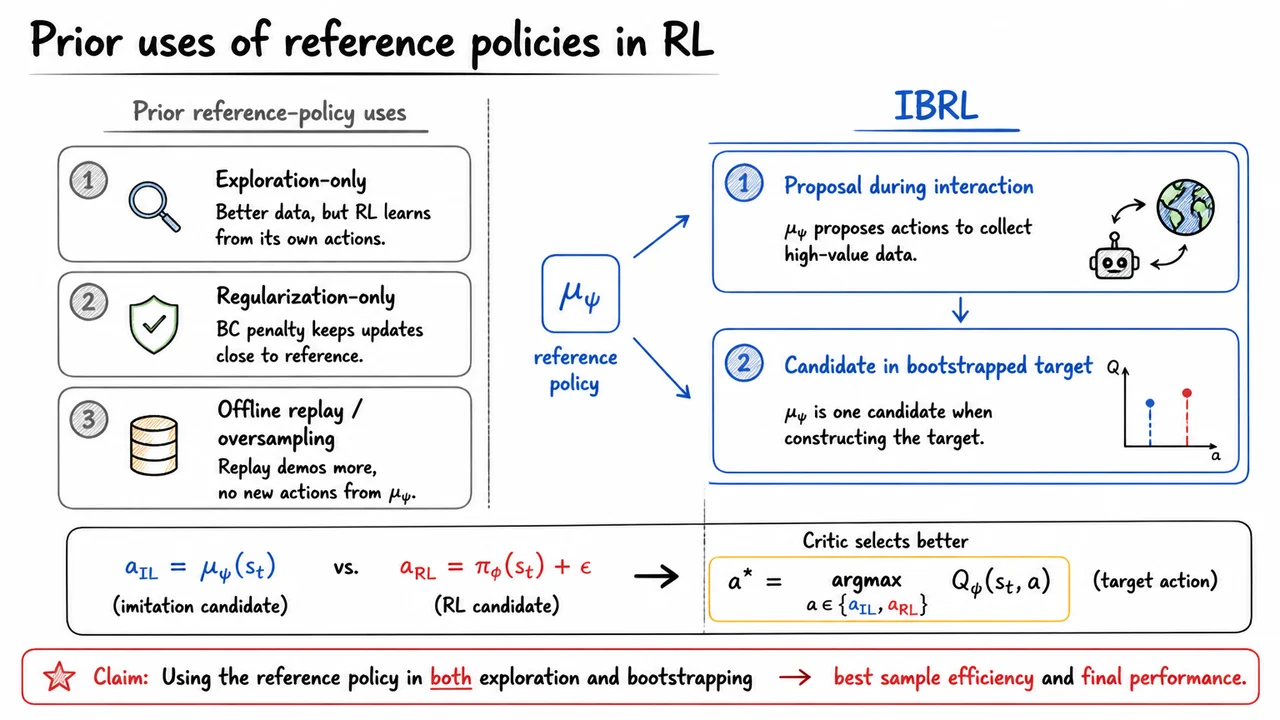
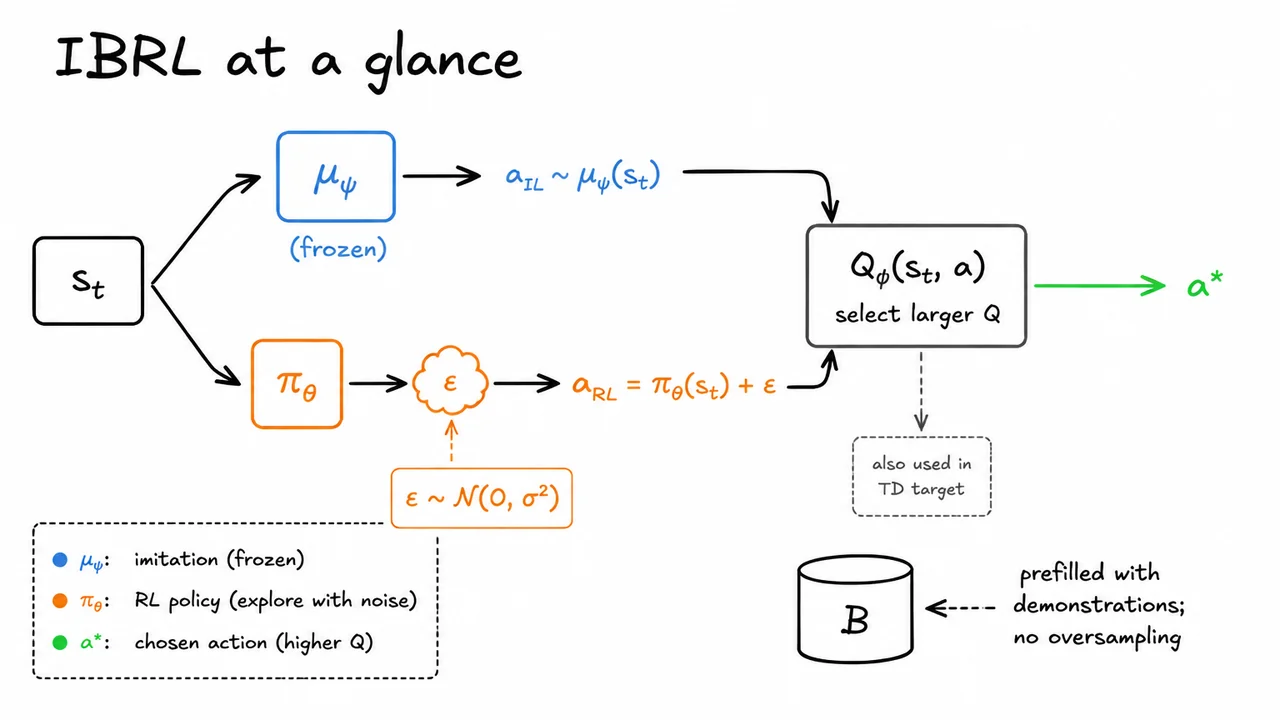
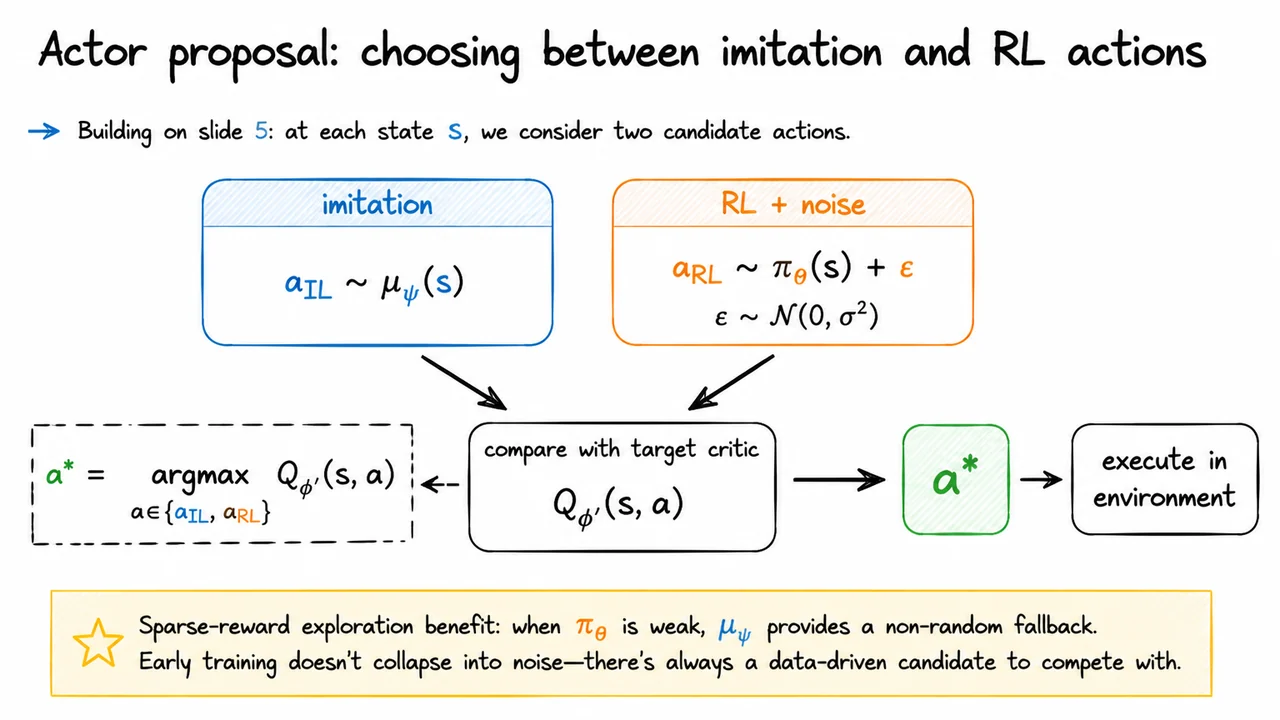
This is exactly the regime where demonstrations become useful. A demonstration can inject structure into exploration by revealing that successful trajectories exist at all, and by placing the agent in states that random rollouts almost never reach. But the important point is that demonstrations are not a replacement for RL here; they are a way to start RL when reward alone is too sparse to do the job. The later IBRL machinery builds on this idea, using demonstrations to guide both exploration and bootstrapping rather than treating them as a separate imitation-only solution.
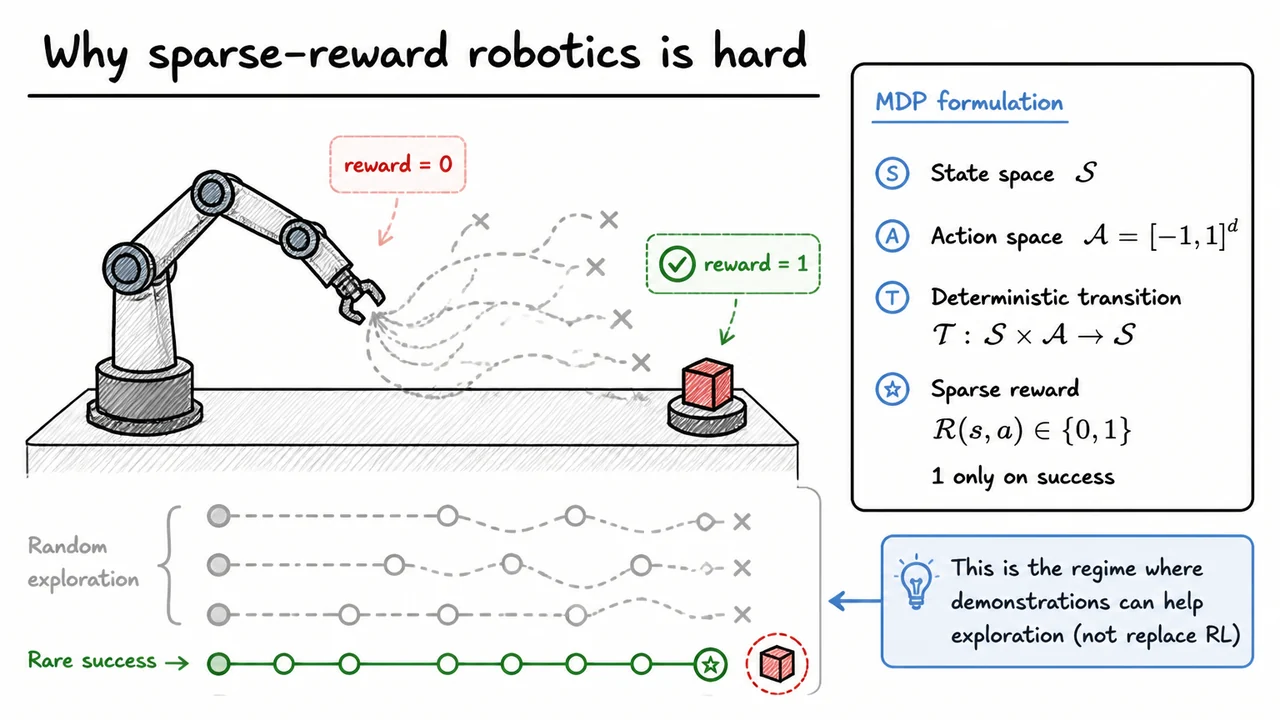
The visual below condenses this failure mode into a compact picture. The left side captures the robotics intuition: many random trajectories wander around the workspace and die out with , while only a rare successful path reaches the goal and earns . The right side packages the formal setup—, , , and —so you can see why the learning problem is so brittle even before we introduce demonstrations.
Taken together, the diagram is meant to make one point feel inevitable: in sparse-reward robotics, the issue is not model capacity or optimization tricks, but data availability. If success is rare enough that random rollouts almost never touch it, then the first challenge is not improving the policy—it is simply producing any informative experience at all.