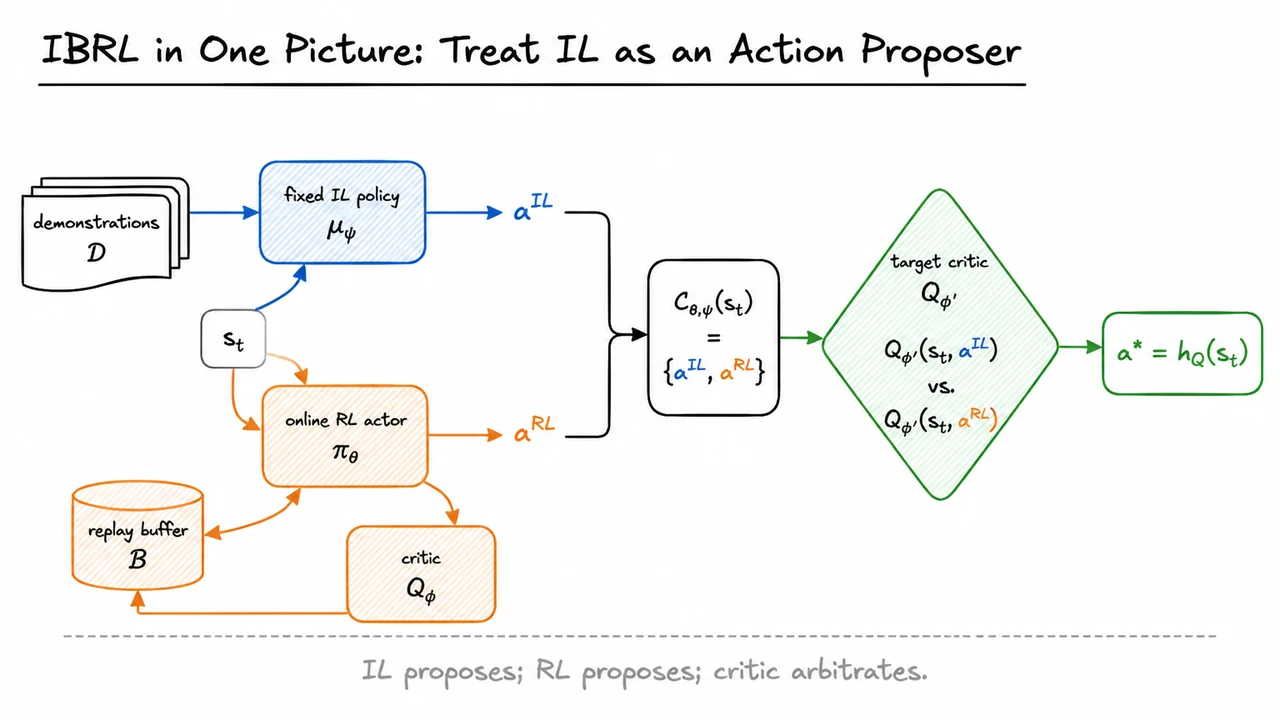
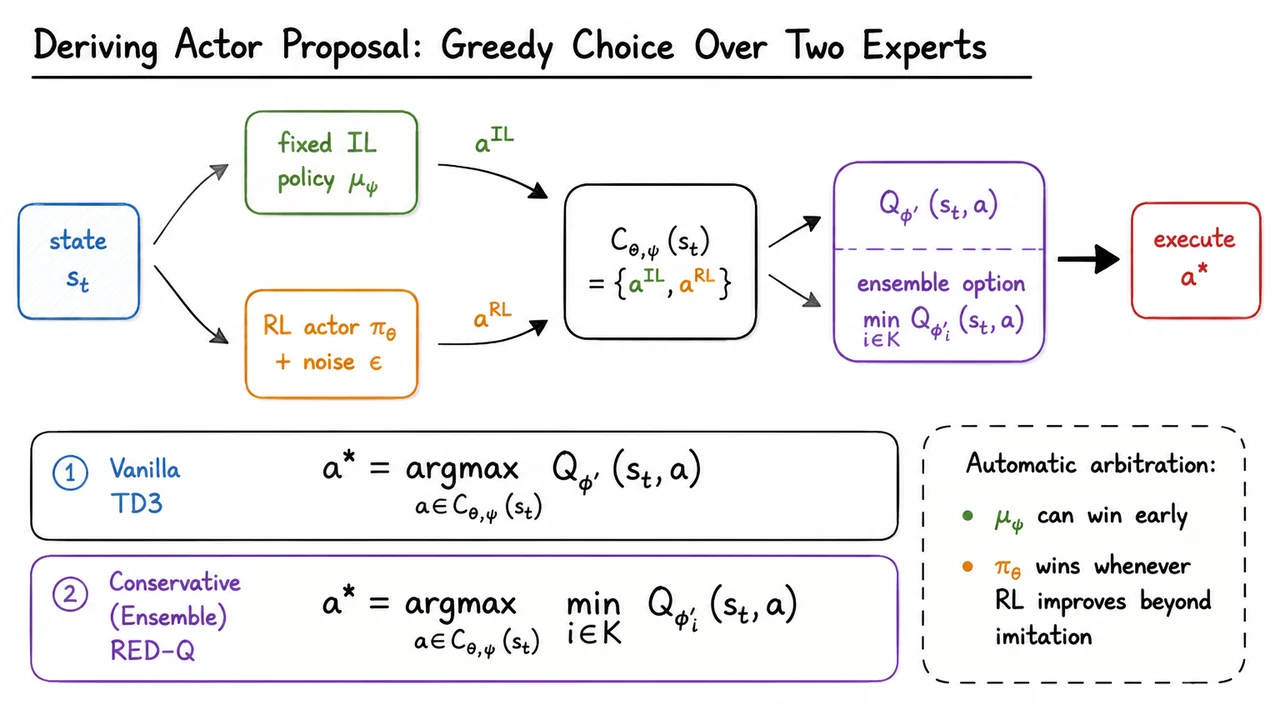
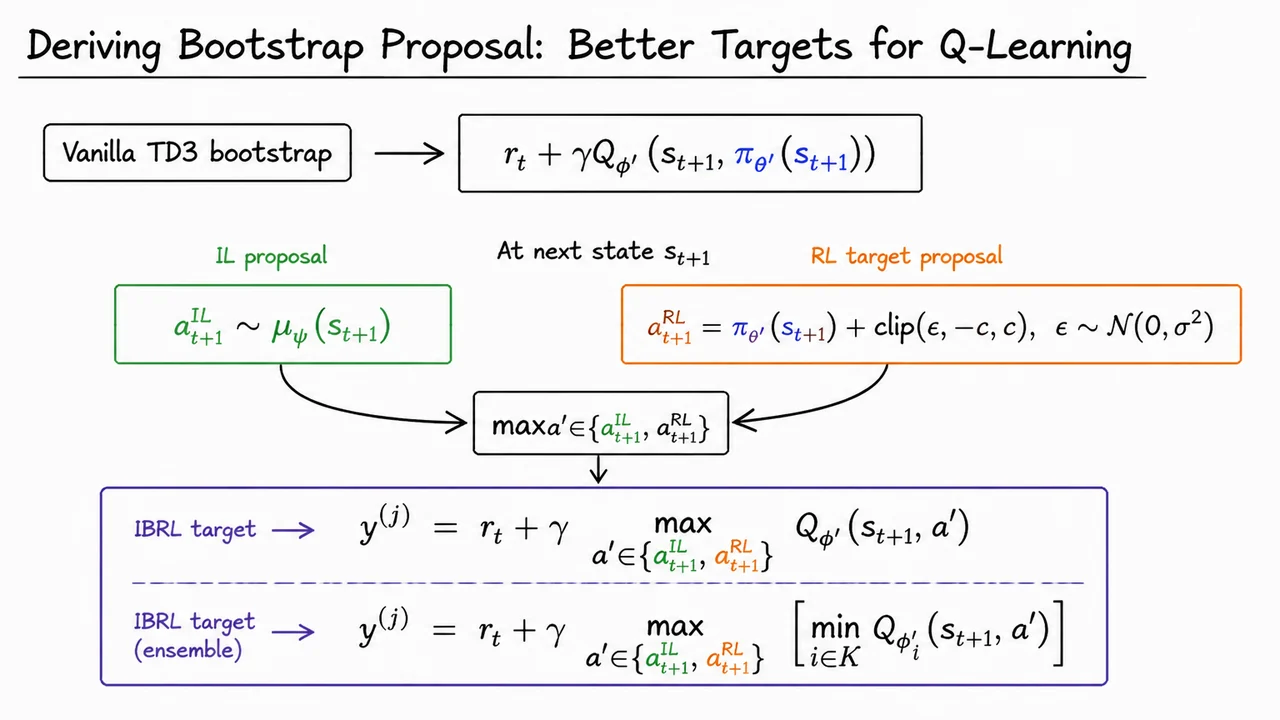
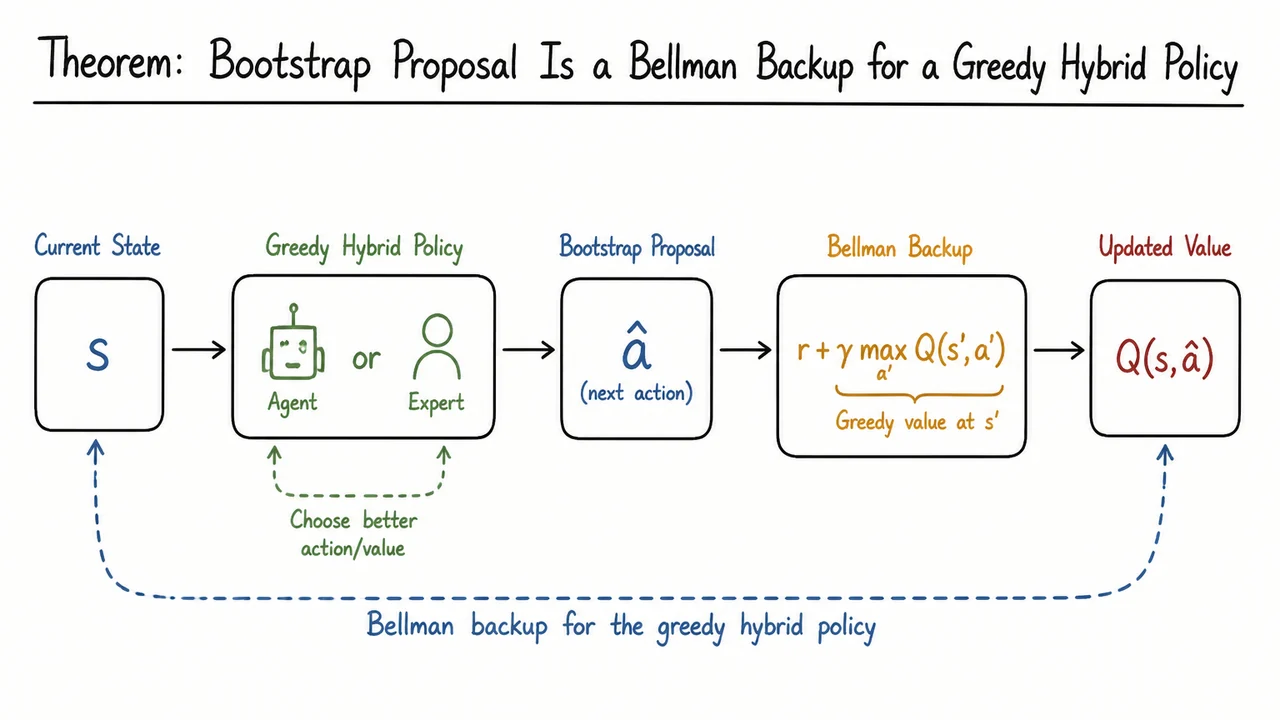
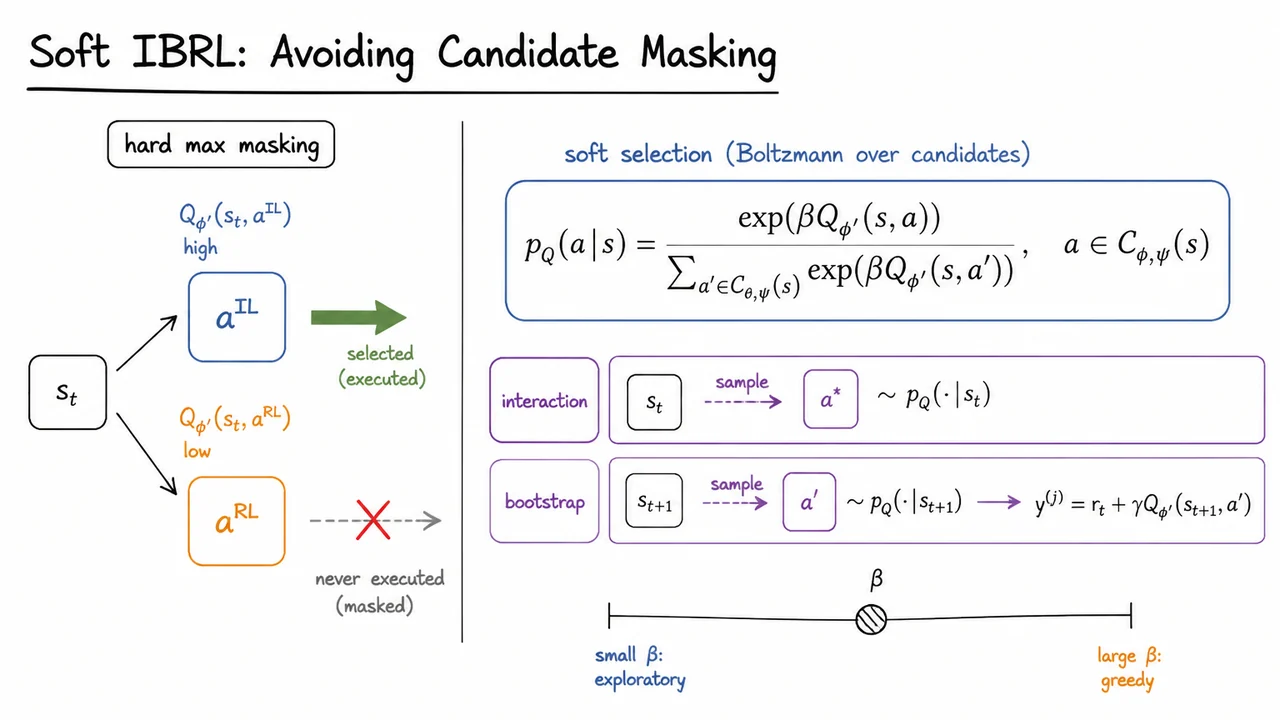
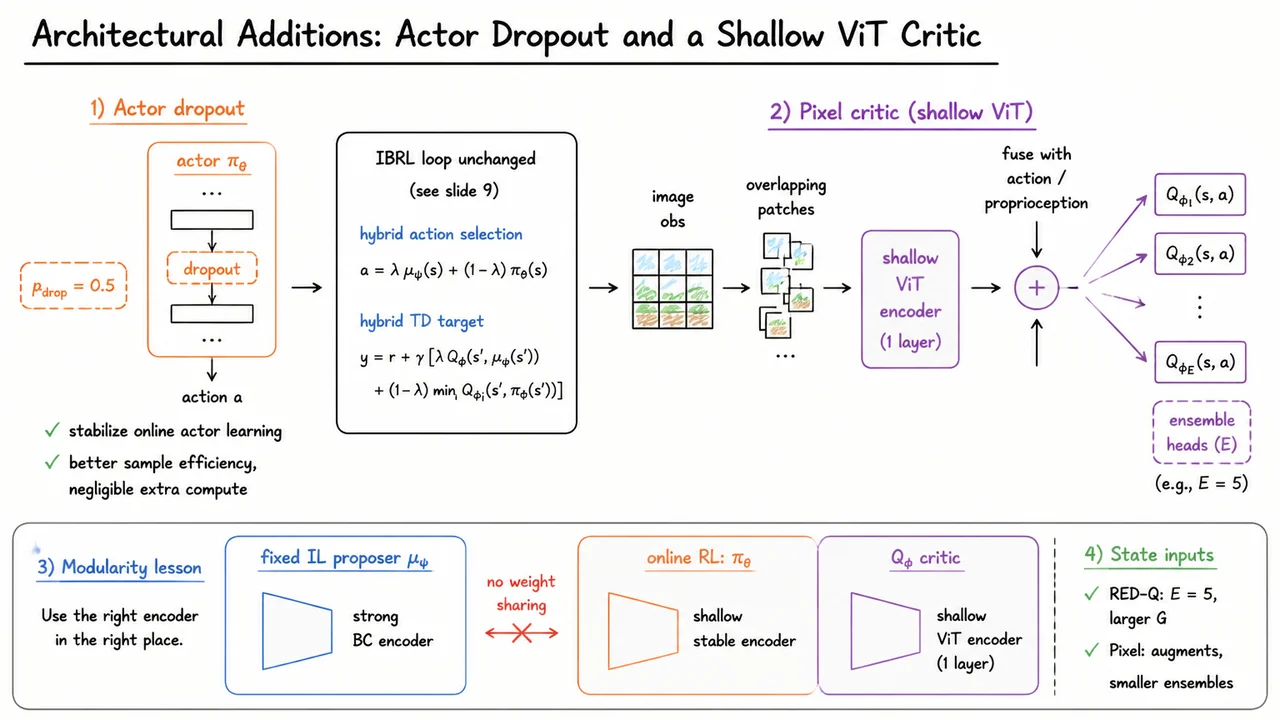
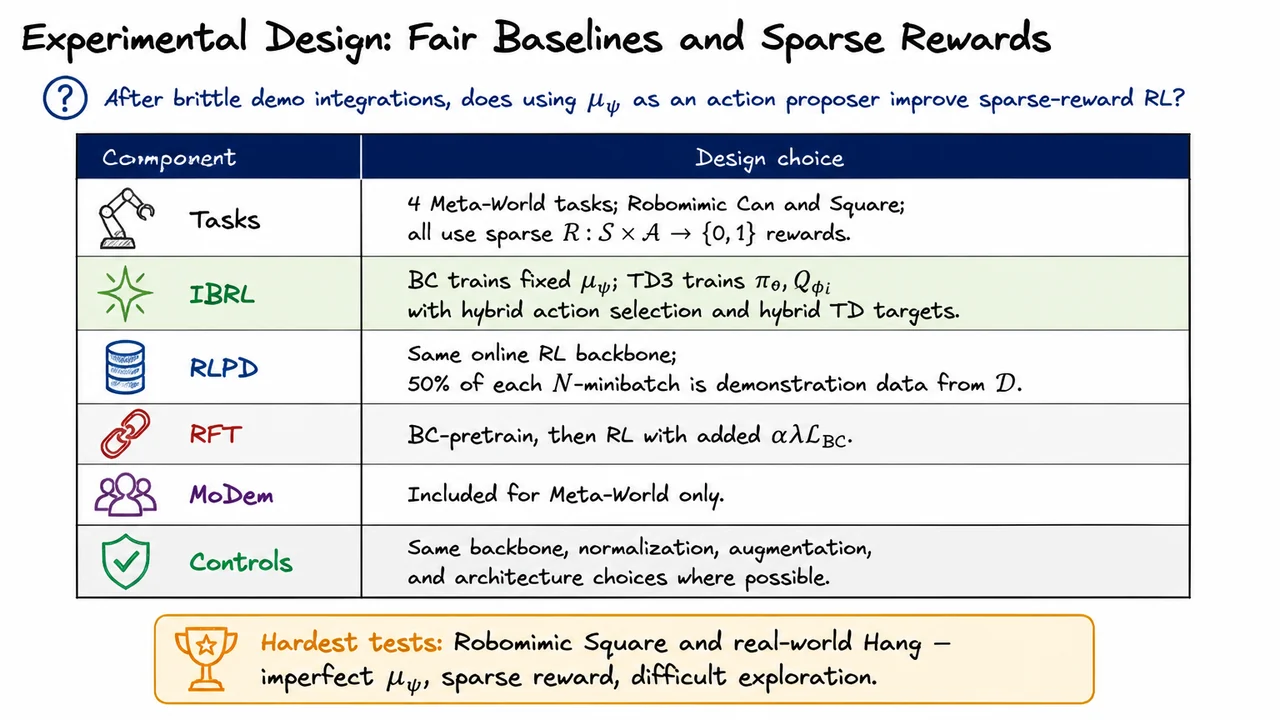
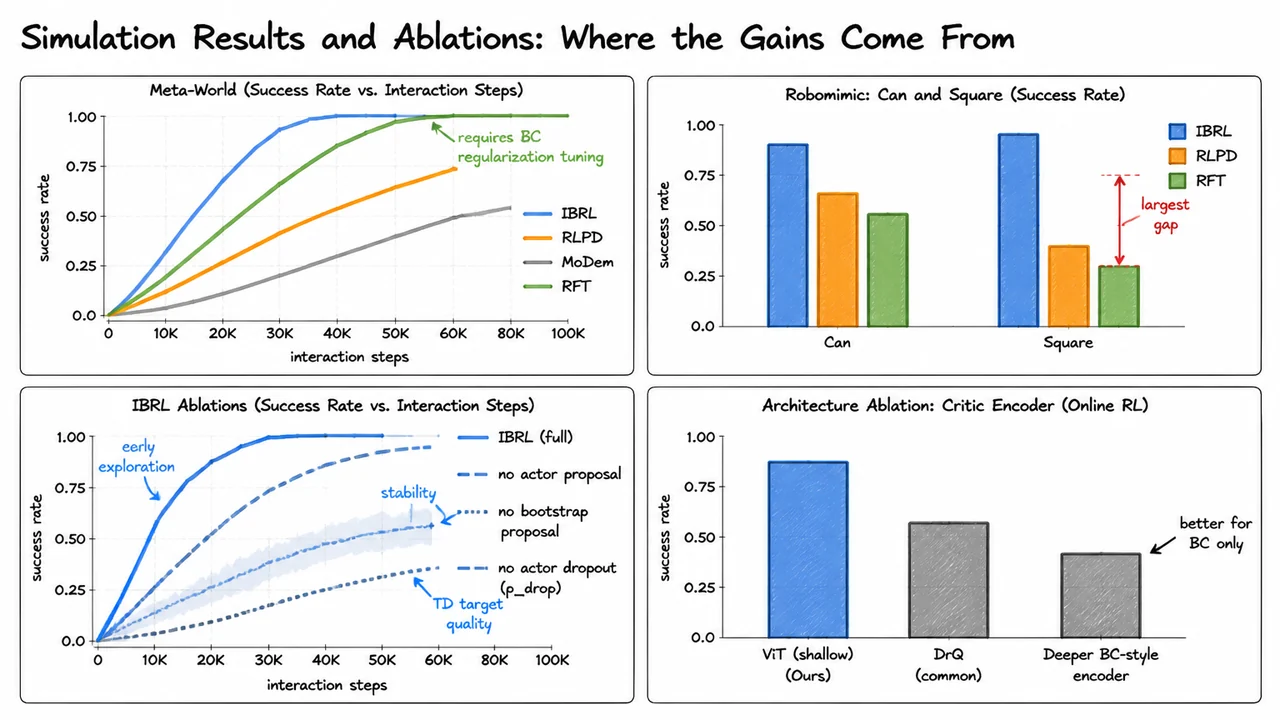
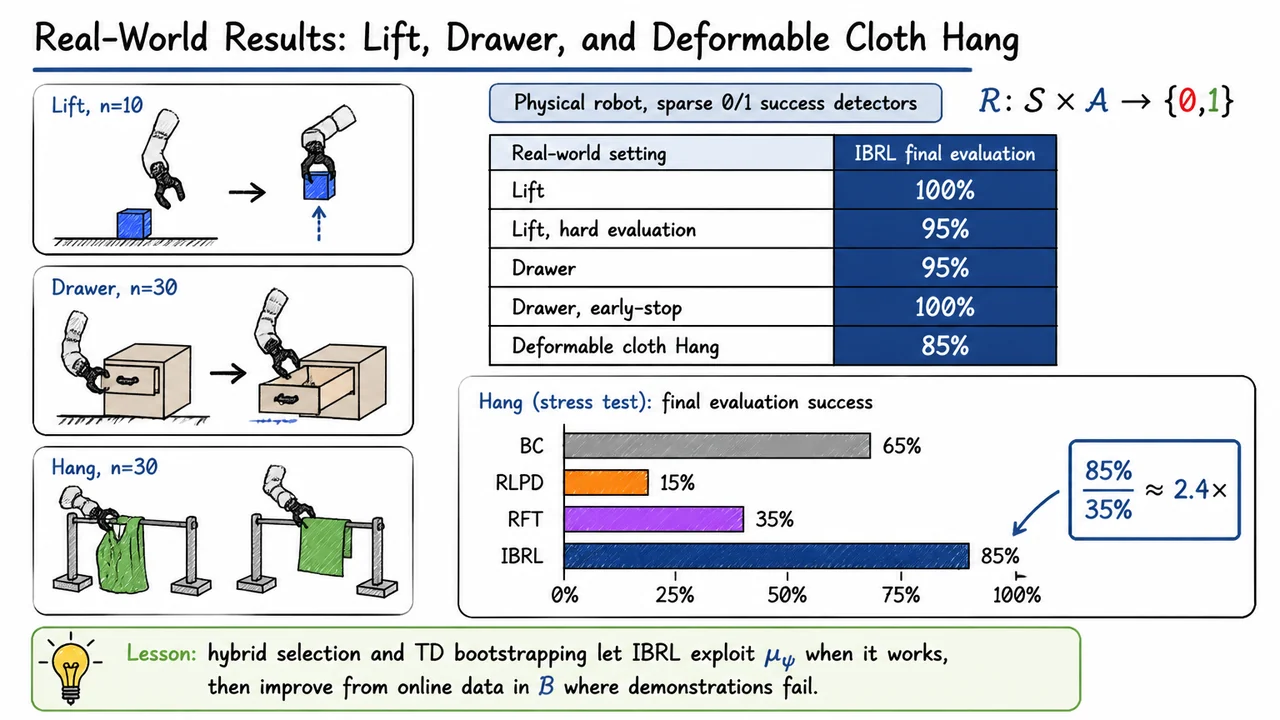
Imitation Bootstrapped Reinforcement Learning (IBRL)
1. Sparse-Reward Robotics: Why Vanilla RL Fails First
To understand why IBRL is needed at all, it helps to start with the uncomfortable baseline: in many robotic manipulation tasks, vanilla reinforcement learning does not merely learn slowly—it may fail to generate the first meaningful learning signal within the available interaction budget.
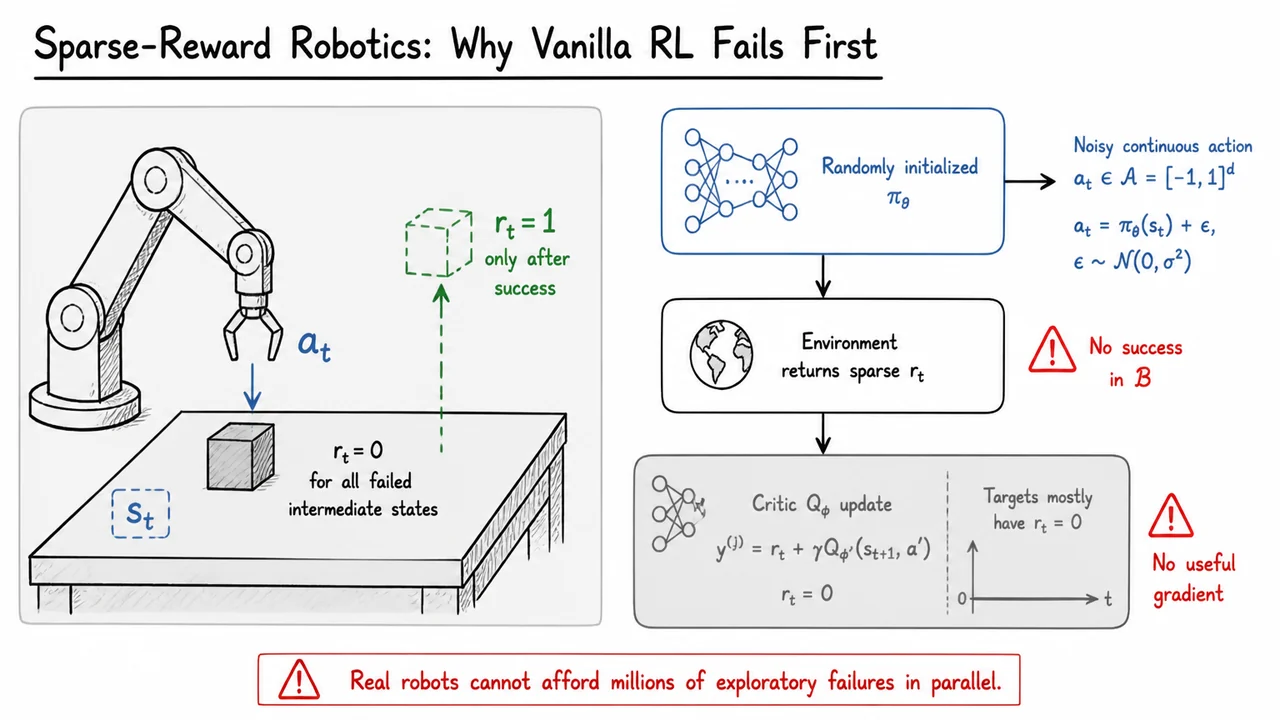
The core issue is that robot tasks often provide task-completion rewards rather than dense feedback. A policy may receive no reward for approaching the object, aligning the gripper, touching the handle, or partially lifting the cube. It receives reward only when the full task succeeds:
This is a very different regime from simulated locomotion benchmarks where every timestep may reward forward velocity, posture, or energy efficiency. In sparse-reward manipulation, almost every transition collected by an untrained agent looks identical from the reward perspective: failure, failure, failure, failure.
The difficulty is amplified by the action space. Robot actions are usually continuous and high-dimensional: joint velocities, end-effector deltas, gripper commands, or hybrid combinations of these. A common exploration rule perturbs the actor’s output with Gaussian noise,
But in a high-dimensional continuous space, random noise is an extremely weak strategy for discovering a precise, temporally extended behavior. Opening a drawer, inserting a peg, lifting an object, or pressing a button may require many coordinated actions in sequence. The probability that a randomly initialized policy plus local Gaussian perturbations stumbles into a successful trajectory can be effectively negligible.
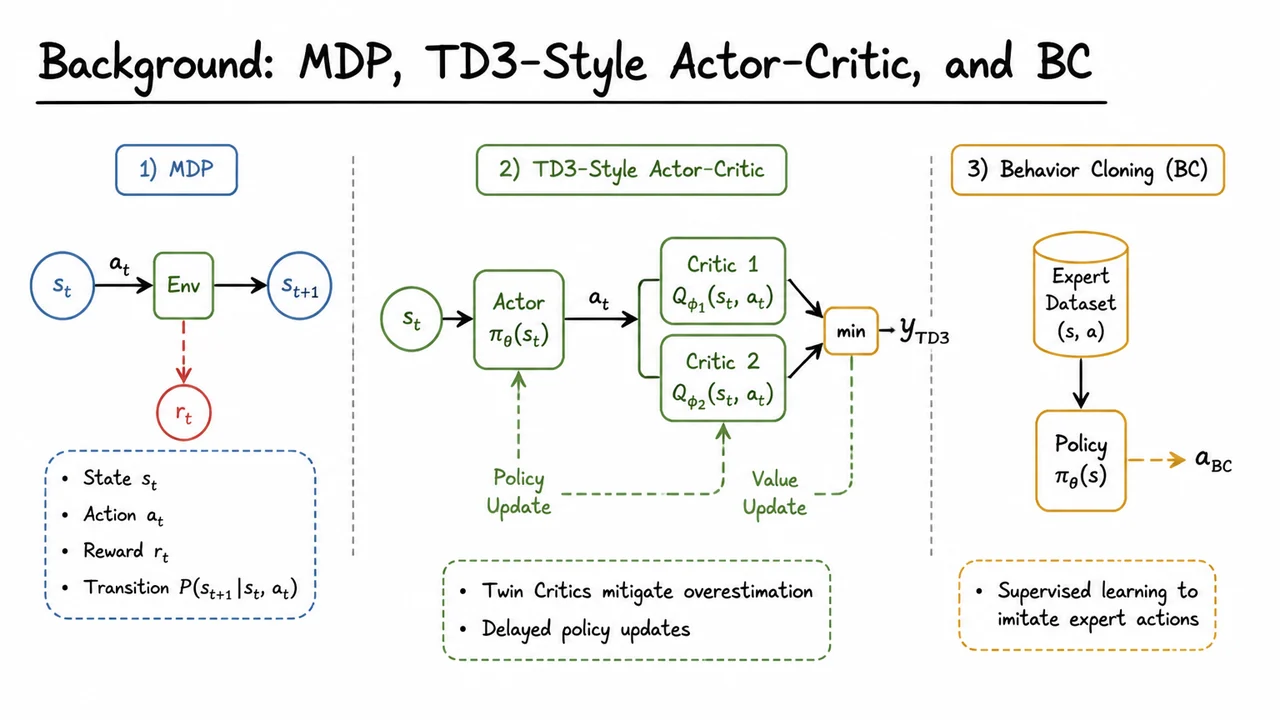
This is not just an exploration inconvenience. It directly corrupts the early learning dynamics of off-policy actor-critic methods such as TD3, DDPG-style algorithms, or SAC-like variants. These methods rely on a replay buffer of observed transitions and train a critic using temporal-difference targets such as
If the buffer contains only failures, then the immediate reward term is almost always zero. The target depends entirely on bootstrapping from another learned value estimate, which itself was trained mostly on zero-reward data. The result is a kind of self-referential emptiness: the critic is asked to distinguish good actions from bad actions before it has ever observed evidence of success.
In principle, bootstrapping can propagate reward backward from rare successful transitions. But that assumes those transitions exist in the replay buffer. When they do not, the critic may learn a nearly flat value landscape. The actor then optimizes against this critic and receives little useful directional information:
- if all actions appear equally bad, the actor gradient is uninformative;
- if value estimates are dominated by approximation noise, the actor may exploit critic errors;
- if exploration remains local around a poor policy, the buffer continues to contain mostly failures.
This creates a feedback loop: bad exploration produces an uninformative critic, and an uninformative critic produces a bad policy, which then continues collecting unhelpful data.
Modern off-policy RL algorithms are powerful partly because they reuse experience efficiently. But reuse does not solve the problem when the experience itself lacks task-relevant signal. A replay buffer with one million failed grasp attempts may still contain very little information about how to grasp. It tells the agent what did not work, but not necessarily which infinitesimal changes would move it toward success—especially when failures are all assigned the same scalar reward.
Robotics makes this failure mode especially costly. In simulation, one might brute-force exploration by running thousands of environments in parallel for millions or billions of steps. On real robots, that is rarely acceptable. Hardware wears out, resets are slow, human supervision may be required, and safety constraints limit reckless exploration. Sparse-reward robotic RL therefore faces a severe mismatch: the algorithm may require many exploratory failures before learning starts, while the real system can only afford a small number.
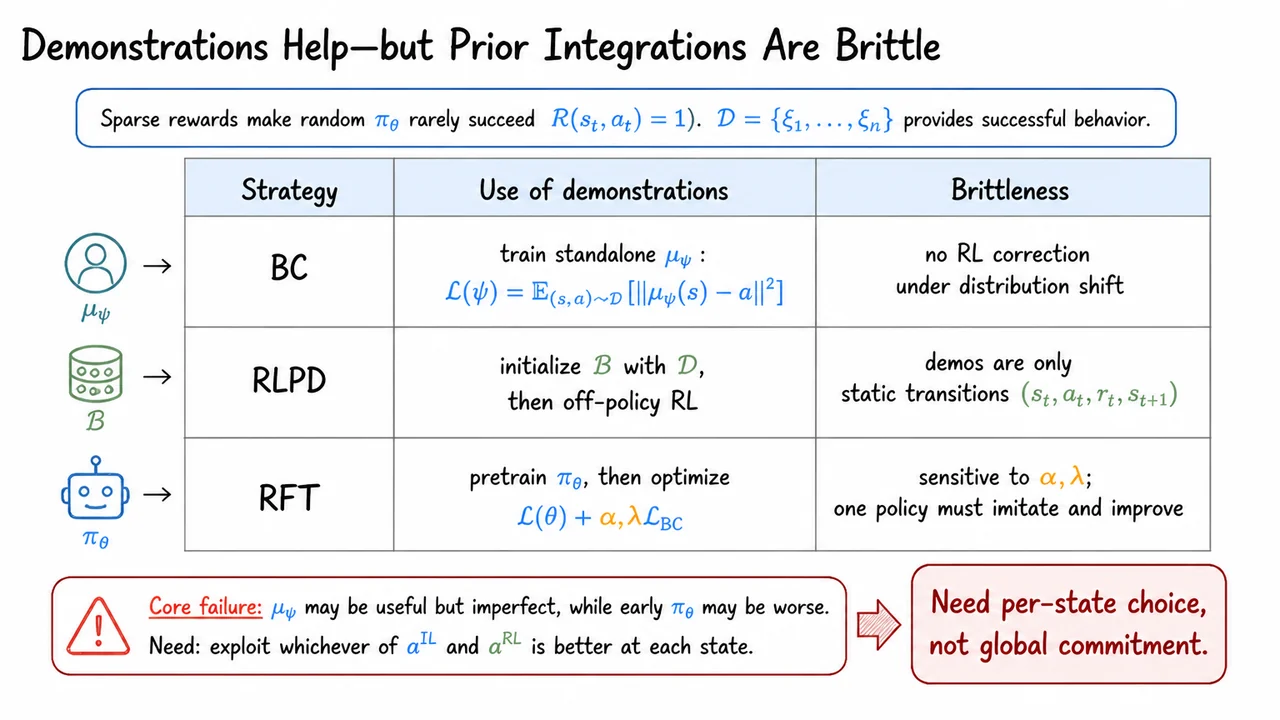
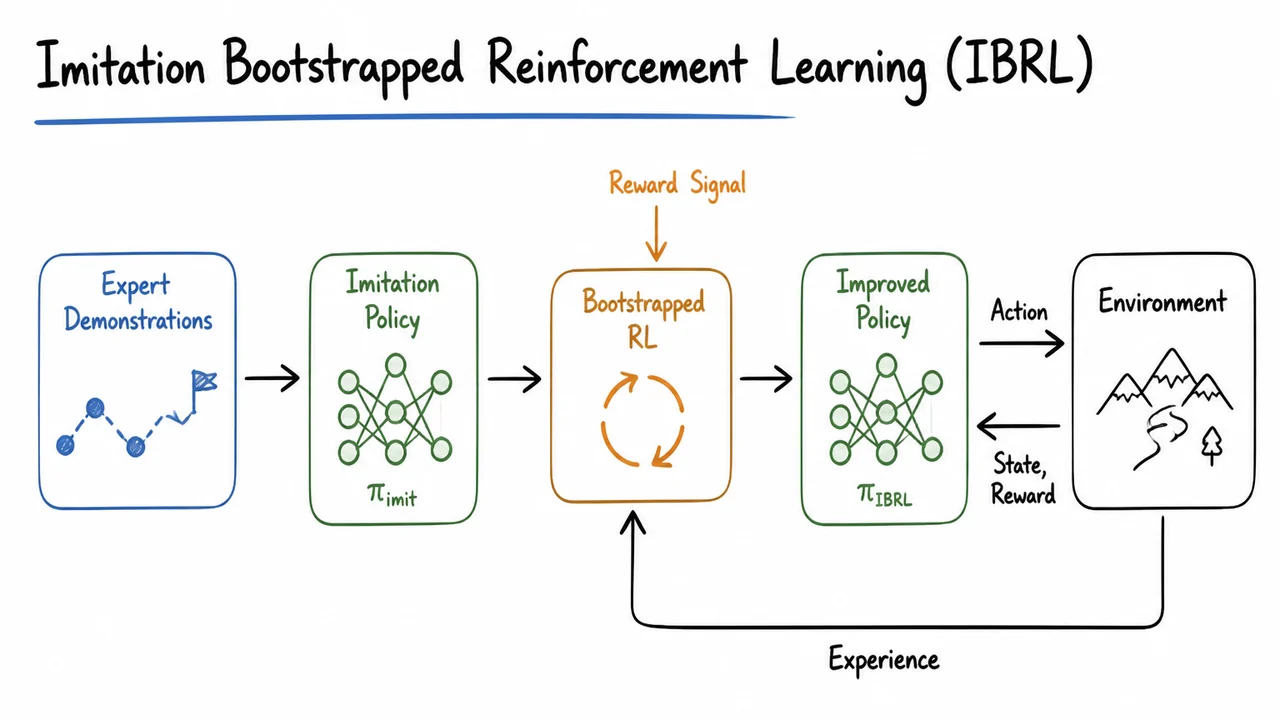
This is the motivation for bringing demonstrations into the picture. But before discussing how to use them well, we need to be precise about what they are fixing. Demonstrations are not merely “extra data”; they provide successful trajectories that break the zero-reward deadlock. They give the critic examples of states and actions near success, and they give the actor behavioral structure that random exploration is unlikely to discover quickly.
The visual below compresses this failure mode into two coupled views. On the left is the robot’s interaction problem: many intermediate states receive , while the green success condition is rare and hard to reach by chance. On the right is the learning system: a randomly initialized actor samples noisy continuous actions, the environment returns sparse rewards, and the critic update is dominated by targets with .
The key takeaway is that vanilla RL can fail before the usual optimization story begins. The critic is not yet learning a useful value function, because the replay buffer has not captured successful behavior. The actor is not improving meaningfully, because the critic cannot tell it which continuous actions lead toward success. This is the specific bottleneck IBRL is designed to address.