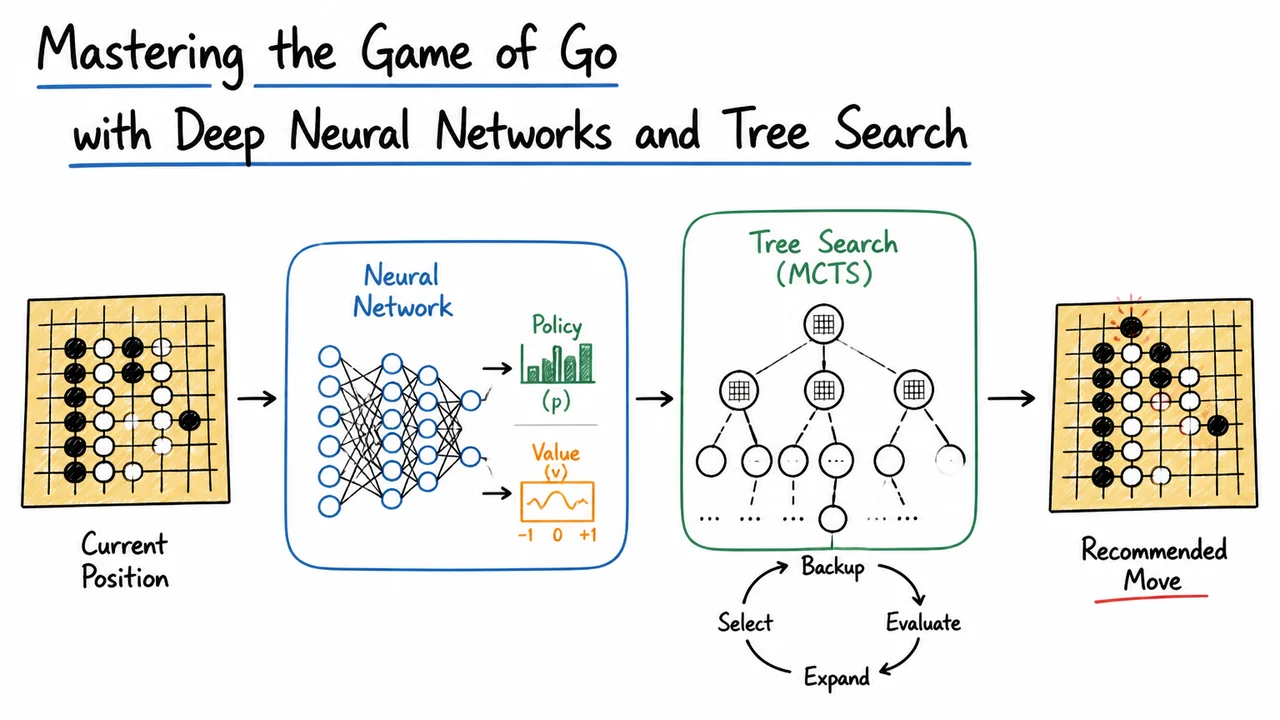
Mastering the Game of Go with Deep Neural Networks and Tree Search
1. The Grand Challenge of Computer Go
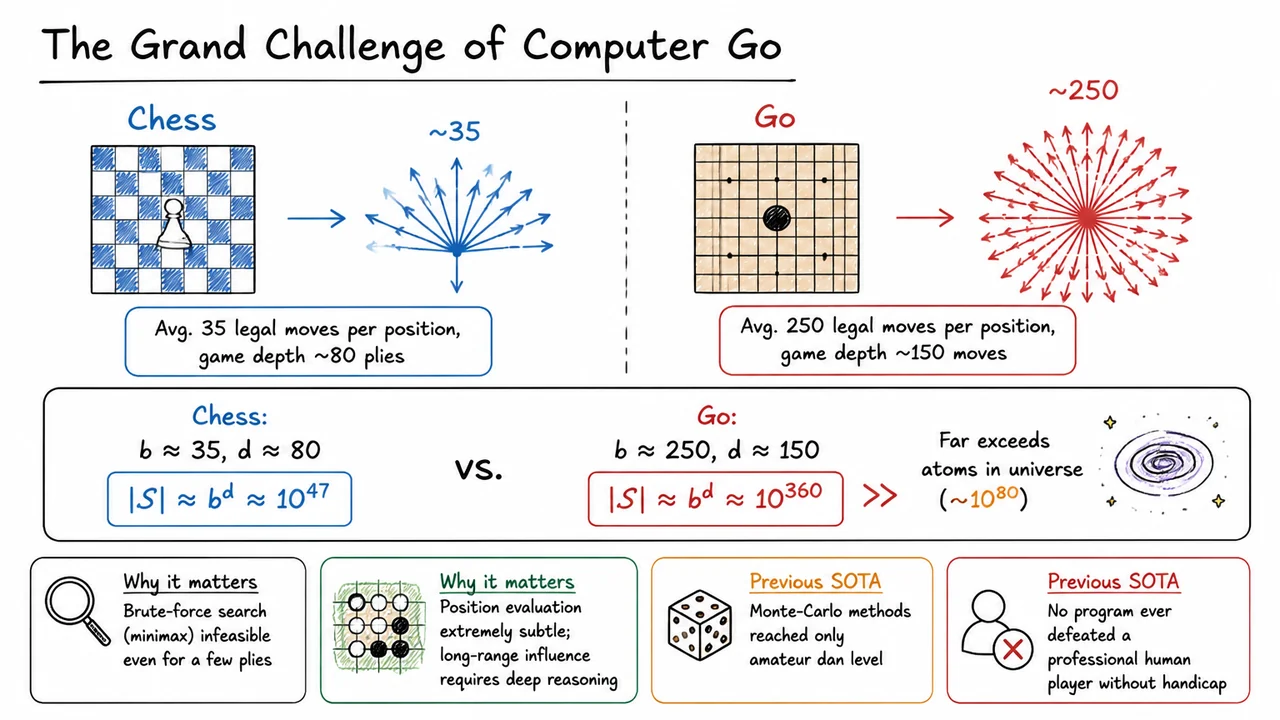
For decades, building a computer program that could play Go at a competitive level stood as one of the most tantalizing unsolved problems in artificial intelligence. The game seems straightforward—two players alternately place black and white stones on a 19×19 grid—but beneath this simplicity lies a combinatorial explosion that makes brute-force reasoning utterly impotent. The fundamental difficulty is not a lack of hardware, but the sheer scale of the search space, which forces us to rethink what it means to evaluate a position and to select a move.
To appreciate the magnitude of the challenge, consider the raw numbers. In a typical Go position, a player must choose among roughly legal moves. A full game lasts around moves. If we naively multiply these to estimate the total number of possible board states, we obtain an astronomical figure:
Even if we could examine a trillion states per second, the age of the universe would be a negligible fraction of the time required to explore a meaningful portion of this space. The estimated number of atoms in the observable universe—a mere —is dwarfed by Go’s state-space by some 280 orders of magnitude. This is not just a “hard” problem; it is a category of scale that resists any approach based on exhaustive enumeration.
The crushing complexity of Go becomes even clearer when contrasted with chess, the historical benchmark for game-playing AI. Chess offers an average branching factor of and a typical game length of plies, yielding a state-space estimate around
Though is still an enormous number, it is over three hundred orders of magnitude smaller than Go’s . This gap has profound practical consequences. In chess, deep minimax search combined with clever pruning and endgame tables enabled programs to outplay human champions by the late 1990s. In Go, however, even a three‑ply search from a mid‑game position would require billions of evaluations, and the tree continues to explode with each additional move. The minimax–alpha‑beta paradigm, so successful in chess, is effectively useless here.
The difference is not merely quantitative. In chess, material balance provides a reliable heuristic signal; a queen is almost always better than a pawn. In Go, the value of a stone depends on subtle, long‑range interactions that unfold across the entire board. A group that appears solid may become vulnerable thirty moves later due to a distant opponent stone that has been quietly exerting influence. Position evaluation in Go demands a kind of holistic, almost intuitive reasoning that statistical or rule‑based evaluations have historically failed to capture. This conceptual depth is what allowed strong amateur players to easily defeat the best computer programs for many years.
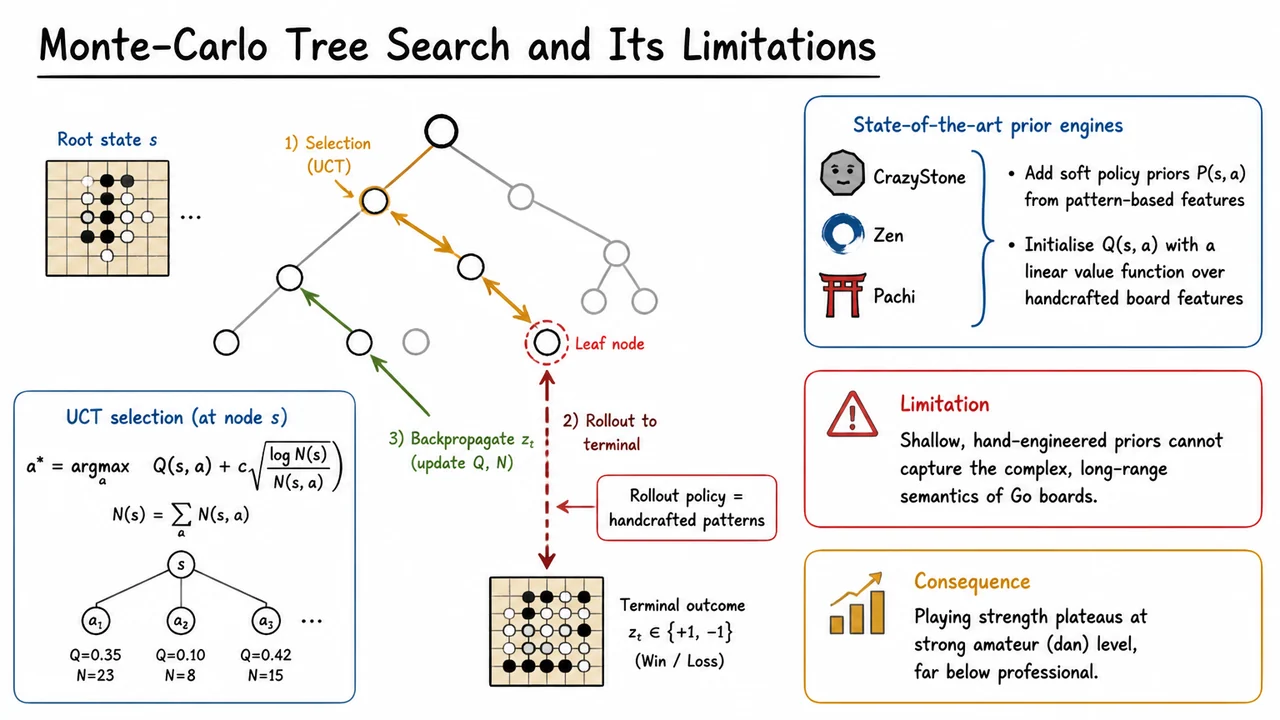
Before the advent of deep neural networks, state-of-the-art Go programs relied on Monte‑Carlo methods—randomized playouts from a position to estimate the winning probability of each move. This approach could occasionally produce surprising configurations, but it plateaued at the level of a strong amateur. No program ever defeated a professional human player in an even game; the best systems required large handicaps to be competitive. The inference was clear: generating random sequences of moves, even with clever biases, could not substitute for a genuine understanding of the game.
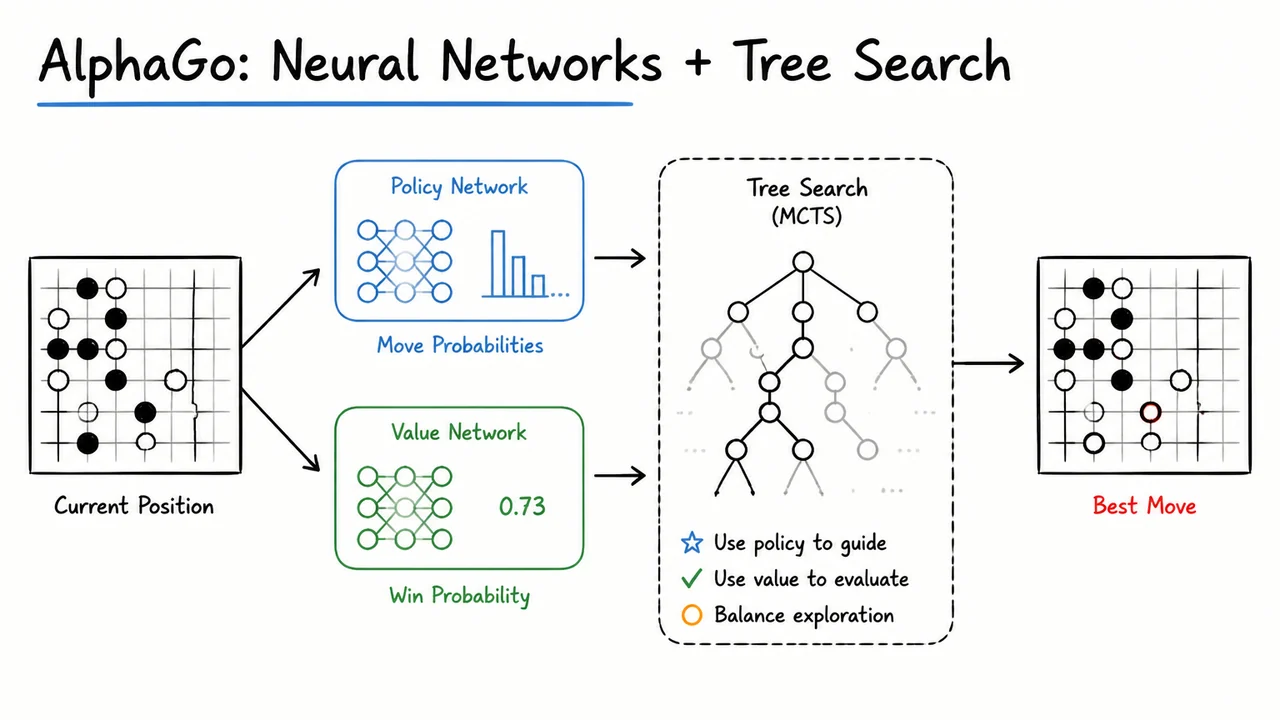
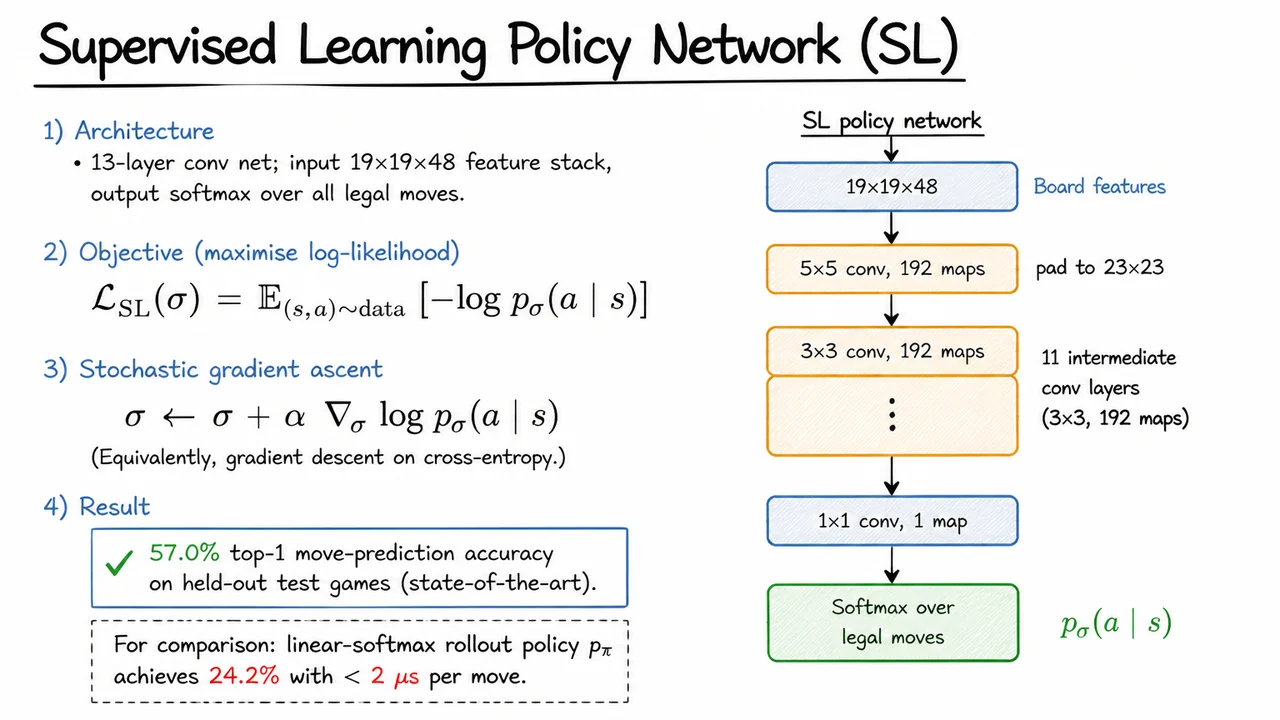
The story of Go therefore encapsulates a classic AI dilemma: how do you make decisions in a domain whose complexity annihilates search-based methods and whose evaluation function cannot be written down by human experts? The solution—the marriage of deep neural networks with tree search—required learning to imitate human moves, learning to evaluate positions from self-play, and then fusing these learned capabilities inside a non‑brute‑force search algorithm. The following sections will unpack each piece of that pipeline, but first we need to internalize exactly why this challenge existed for so long.
The visual below distills this entire argument into a side‑by‑side comparison that makes the exponential gap visceral. On the left is chess, with its modest branching and manageable state‑space; on the right, Go explodes into a branching tsunami of possibilities. The diagram’s color coding—calm blue/green for chess, aggressive red/orange for Go—reinforces the impossibility. The callout formulas versus anchor the abstract numbers, and the tiny icon of the observable universe next to Go’s estimate serves as a humbling reminder that even the entire physical cosmos is many orders of magnitude too small to contain all possible Go boards. By presenting the data graphically, the slide transforms an already staggering numerical comparison into an intuitive recognition: to conquer Go, we need to stop searching the universe and start learning it.