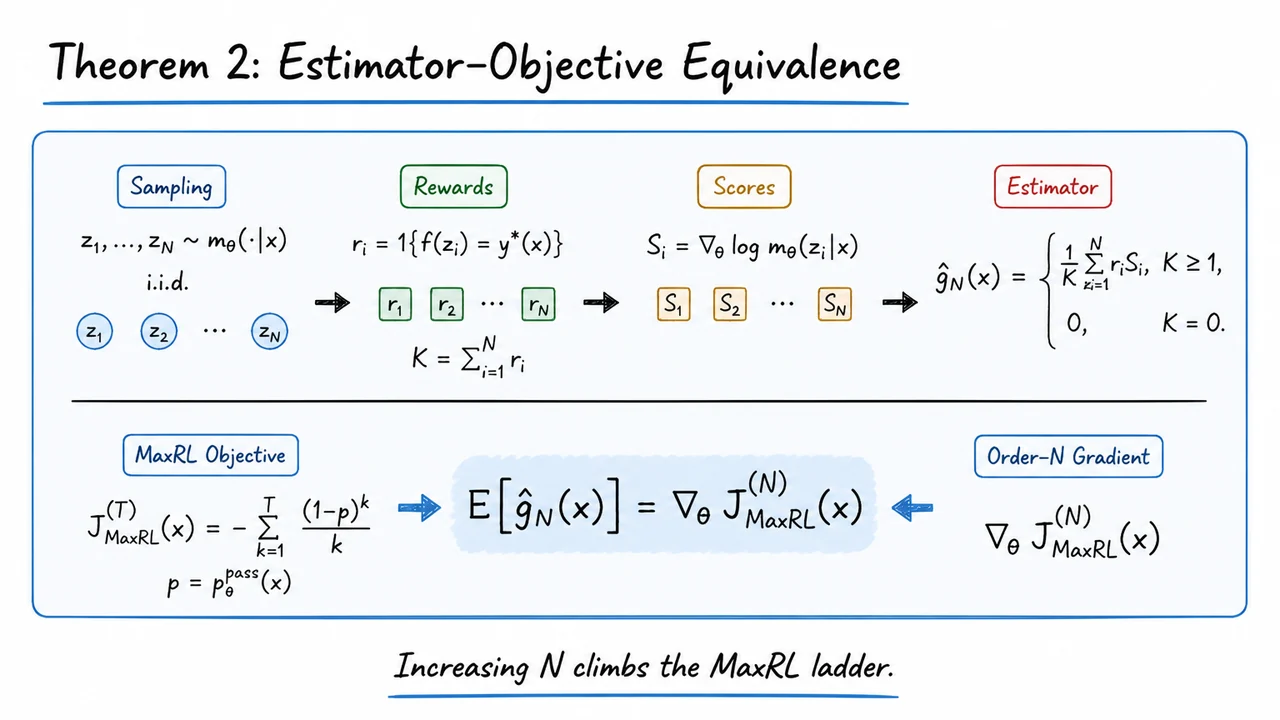
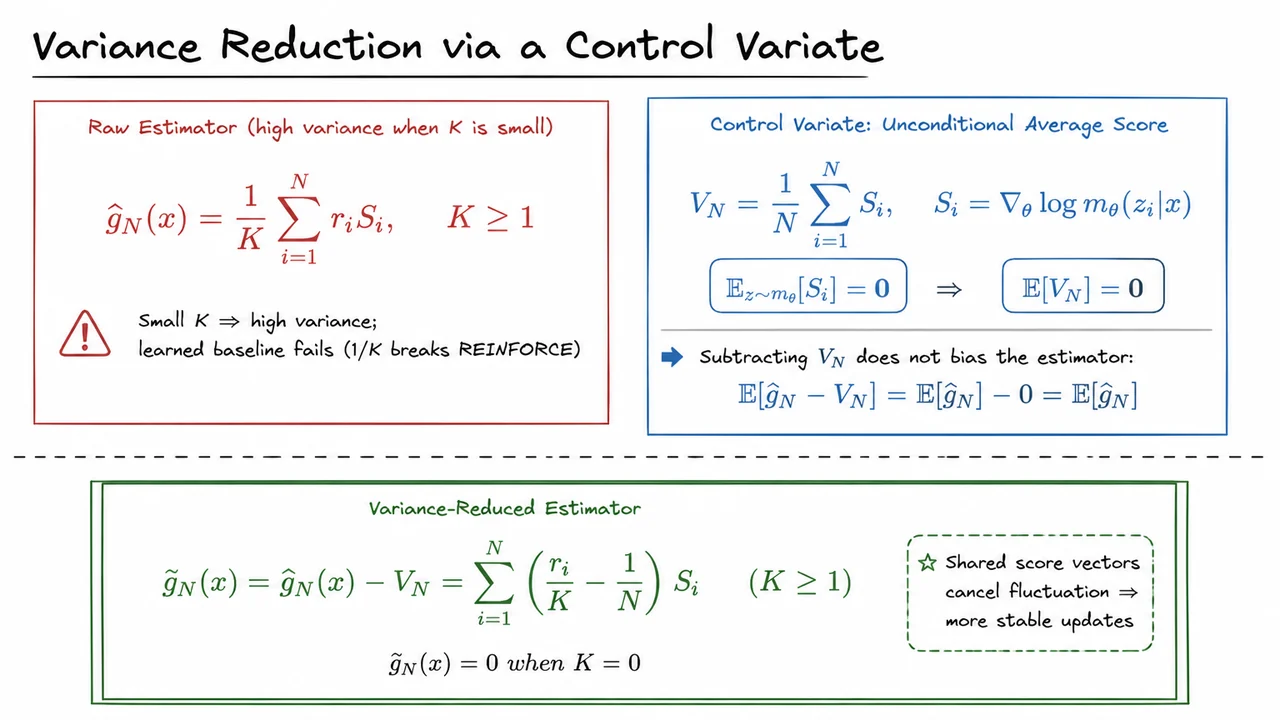
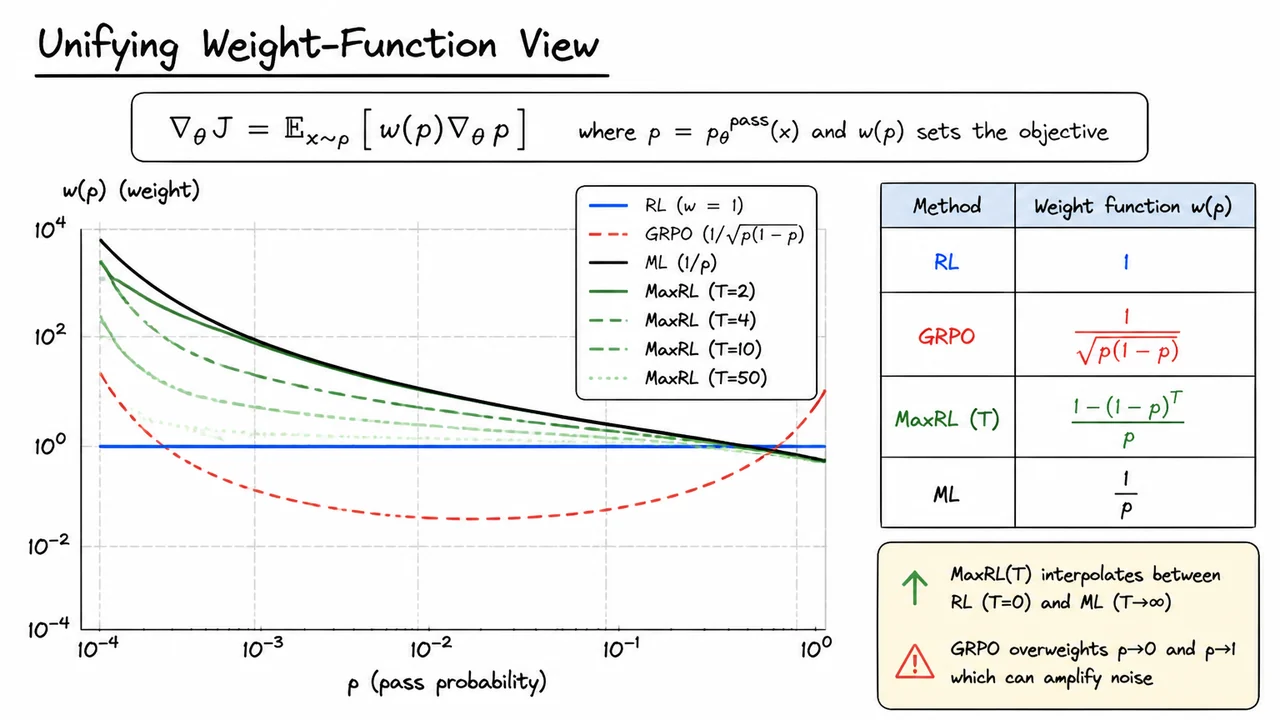
Maximum Likelihood Reinforcement Learning (MaxRL): A Compute-Indexed Bridge from RL to Log-Likelihood
1. Why Standard RL Fails on Hard Correctness Tasks
When we fine-tune language models on reasoning and problem-solving tasks where the feedback is a simple pass/fail judgment, the choice of objective fundamentally shapes which problems the model learns from. Two natural population-level objectives stand out: the expected pass rate, favored by standard reinforcement learning, and the expected log pass probability, which corresponds to maximum likelihood estimation over successful trajectories. At first glance they seem like minor variants, but their gradients reveal a dramatic difference in how they allocate learning signal across easy and hard problems.
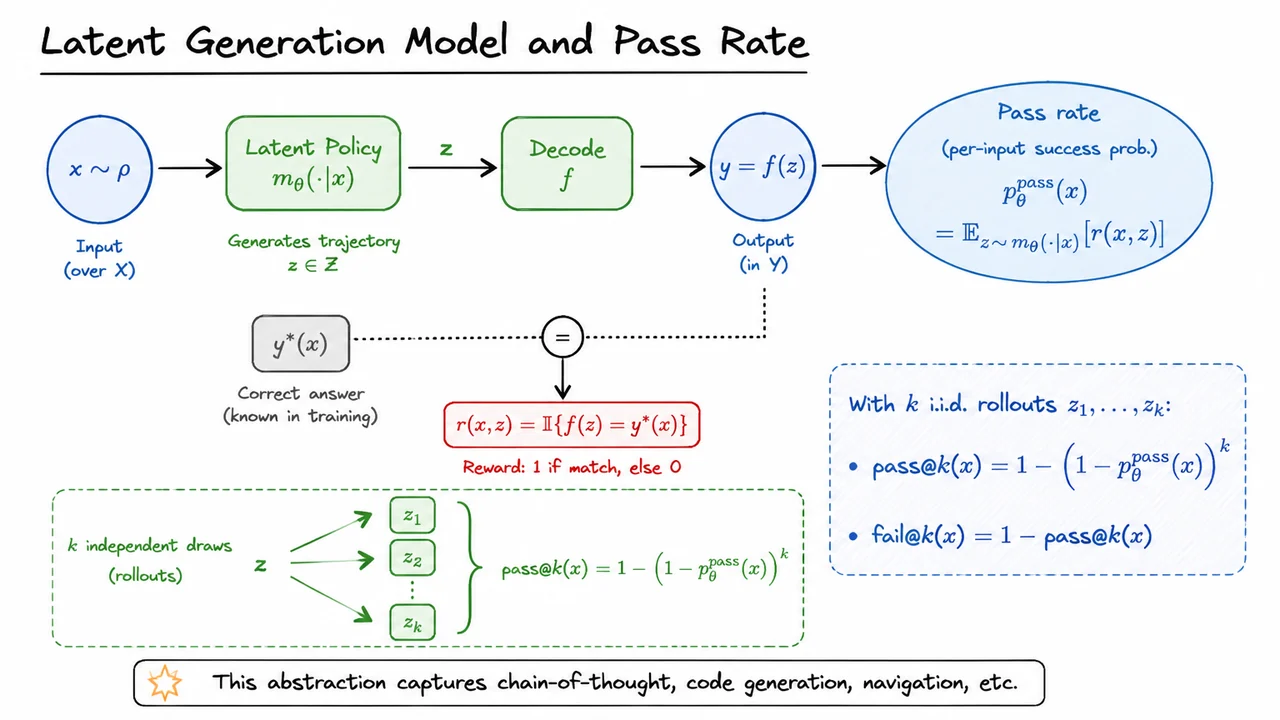
Let denote the probability that the model, parameterized by , produces a correct answer for input . The RL objective that simply maximizes the overall proportion of solved problems is
where is the distribution over prompts. In contrast, the log-likelihood (ML) objective – often used in supervised fine-tuning where we have a set of correct demonstrations – can be written at the population level as
Both are legitimate goals, but they encode very different preferences. The RL objective rewards the model for achieving high average accuracy; it doesn’t care whether that average comes from acing easy problems while ignoring the hardest ones. The ML objective, on the other hand, penalizes the model heavily whenever a problem remains unsolved, even if it’s already extremely difficult – because is sensitive to small probabilities.
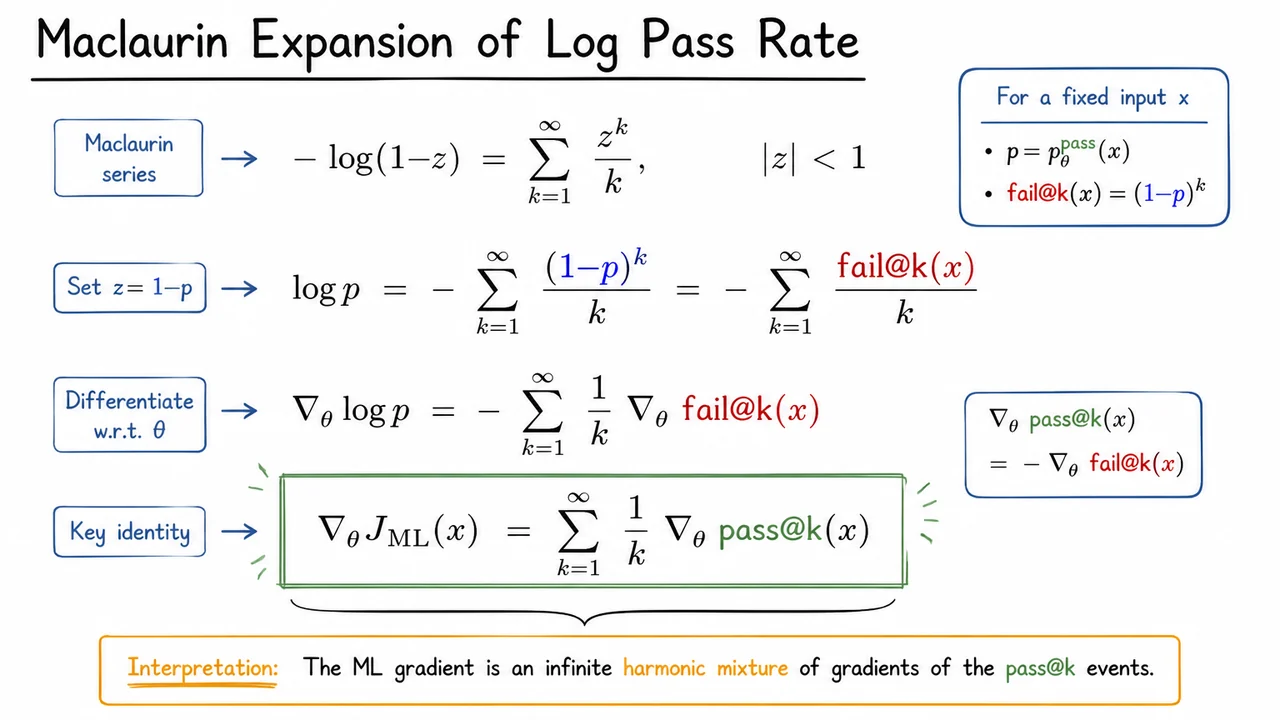
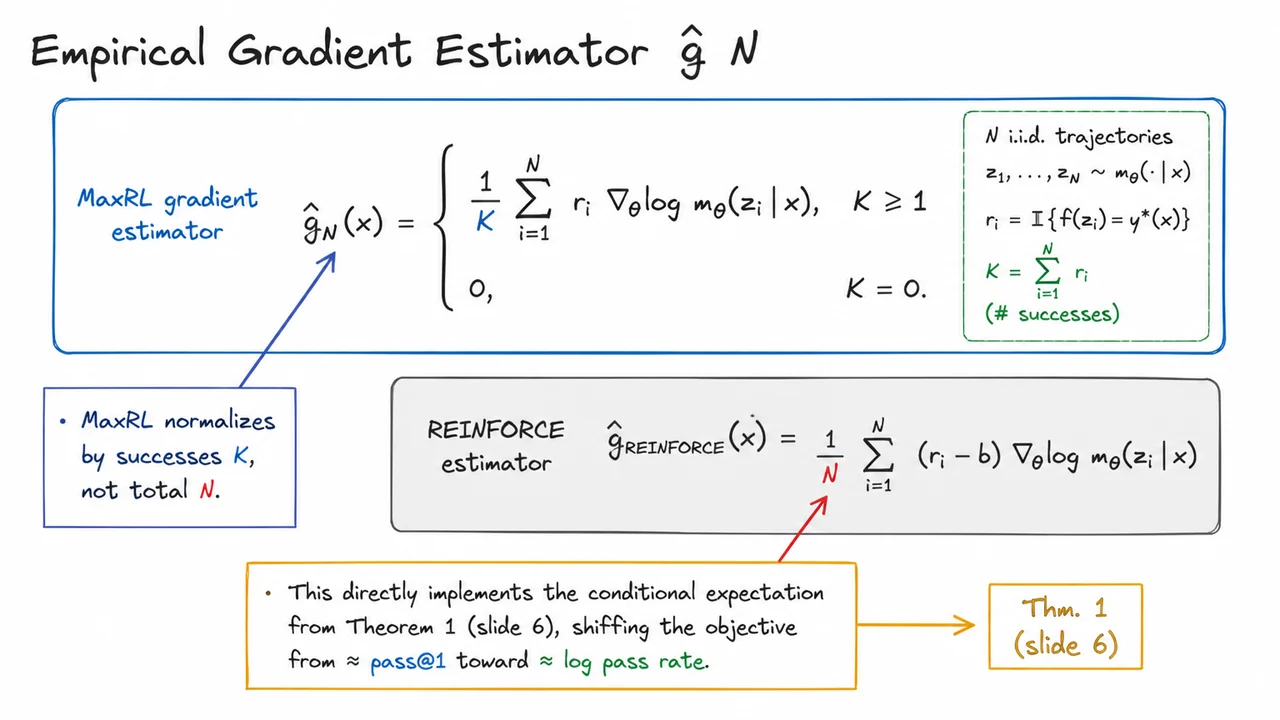
The real tension appears when we inspect the gradients. Taking the derivative under the expectation gives
In the RL gradient, each problem’s gradient vector is weighted equally, with a coefficient of . In the ML gradient, that same vector is amplified by the inverse pass probability . Consequently, hard problems, where is tiny, receive an enormous effective weight in the ML update, while easy problems, with close to , contribute roughly the same as they do under RL. The practical outcome is a binary feedback dilemma: RL almost entirely ignores the hardest prompts, whereas ML over-amplifies them to the point of instability.
To see how severe this imbalance can be, consider a batch of five problems – two hard ones with , and three easy ones with . Under the RL gradient, the hard problems each contribute a weight of (reflecting the tiny magnitude of their relative to easier problems, or more precisely, the gradient coefficient if we rewrite ). Under the ML gradient, the hard problems are each multiplied by , while the easy ones receive a modest . In other words, the two hard problems, which together constitute 40% of the batch, are virtually invisible to the RL update, yet they dominate the ML update, receiving roughly 10,000 times the weight of the easy problems in terms of the factor applied to .
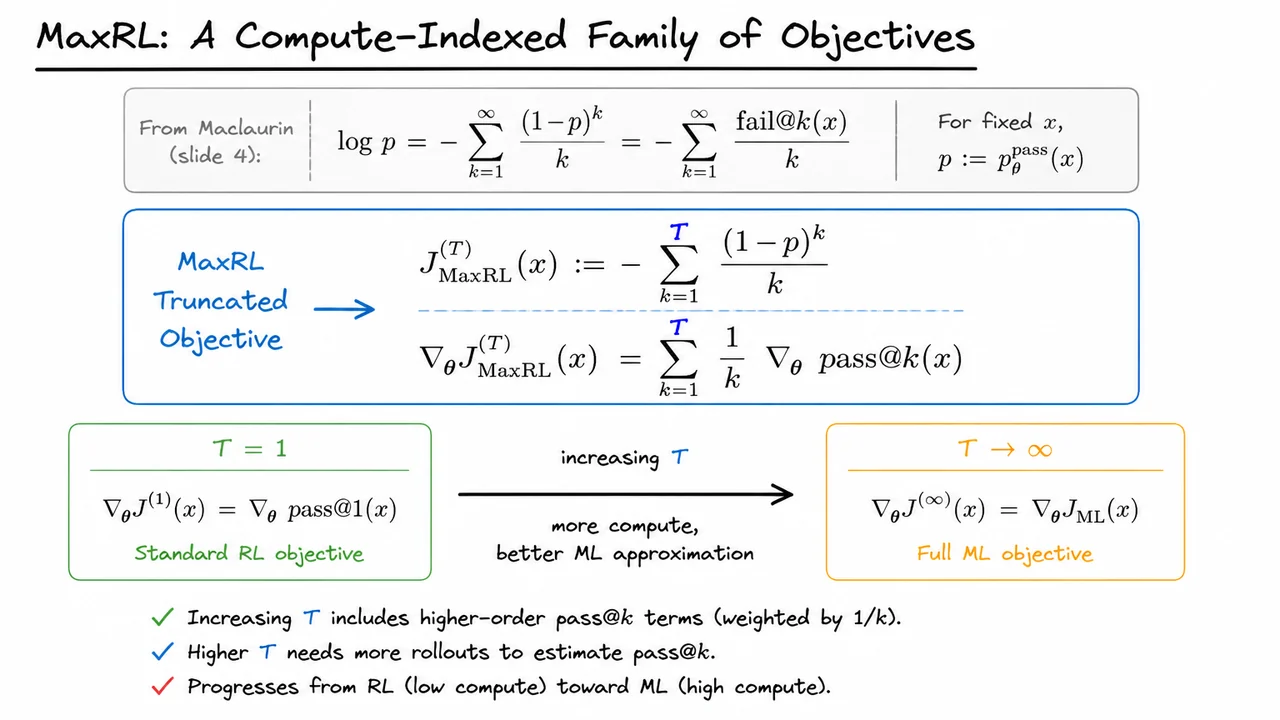
This extreme asymmetry is not just a quirk; it exposes a fundamental gap for correctness-based tasks where we have binary reward signals. Neither objective gives a principled way to control how much we care about hard examples relative to easy ones. We need a compute-indexed bridge that allows us to smoothly interpolate between these two poles – giving enough emphasis to challenging problems to learn from them, while still maintaining the stability that comes from solving a broad set of tasks. The MaxRL framework, introduced after this motivation, defines exactly such a family of objectives, controlled by a single hyperparameter that governs how many samples we invest per prompt.
The visual below – a clean diagrammatic slide titled Why Standard RL Fails on Hard Correctness Tasks – reinforces this idea at a glance. On the left, it displays the gradient equations side by side, highlighting the coefficient versus . On the right, a simple color-coded table lays out the five‑task example, with hard rows in a muted red and easy rows in green. An arrow dramatically connects the RL weight column to the ML column, underscoring the factor‑of‑ jump. The image distills the quantitative argument into a single compelling snapshot: it leaves no doubt that neither RL nor ML alone provides a satisfactory answer for binary‑correctness training, and that the missing ingredient is a tunable knob between them.