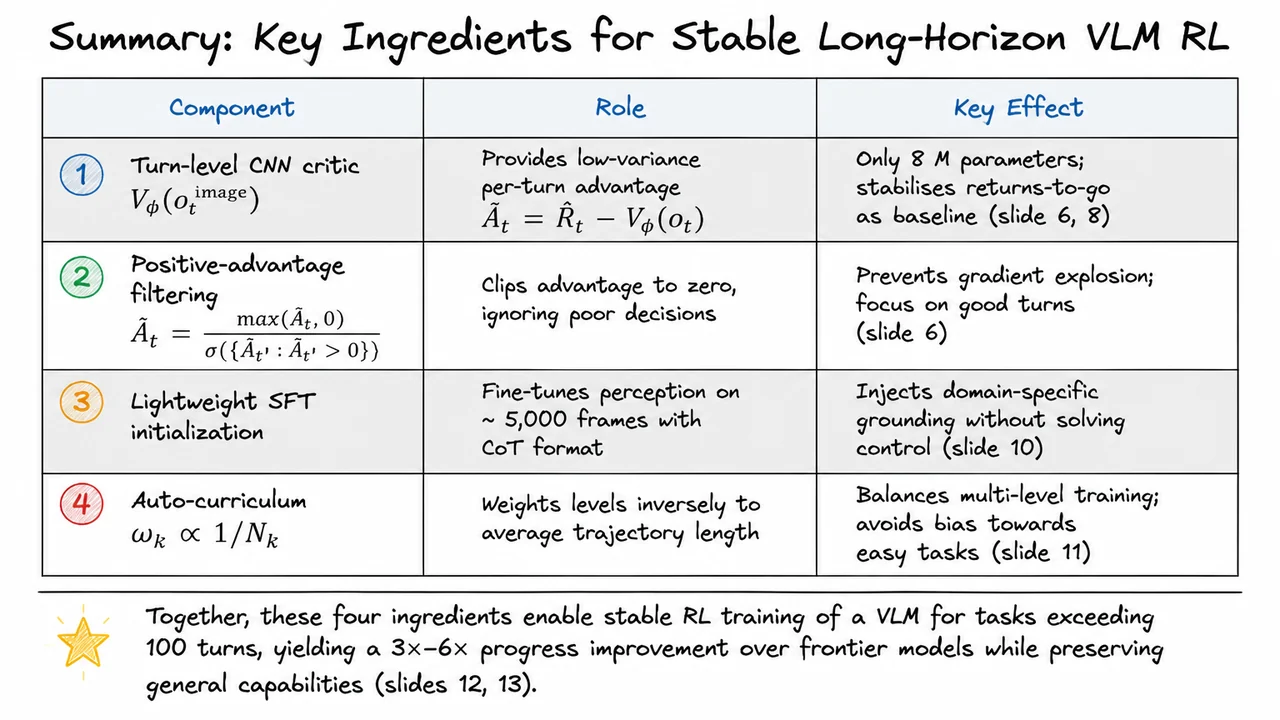
Odysseus: Stable RL Training of VLMs for Long-Horizon Game Decision-Making
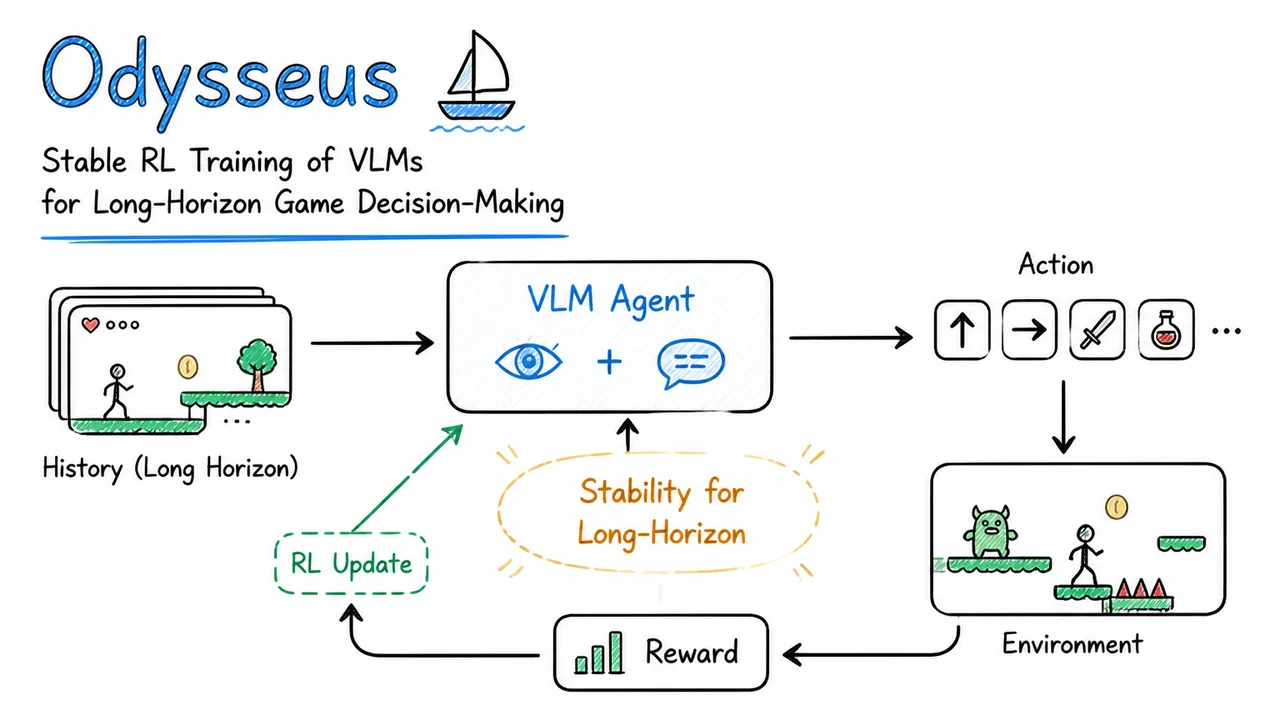
1. Long-Horizon VLM Decision-Making in Super Mario Land
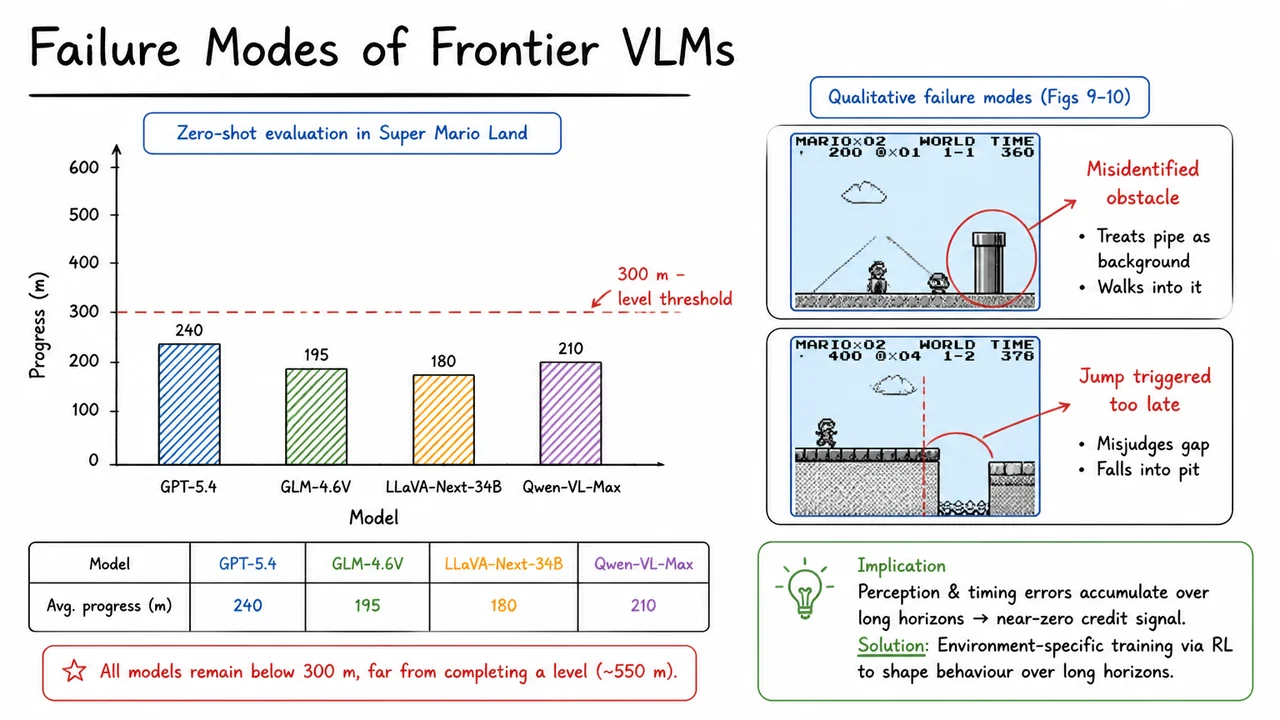
If you’ve ever watched a frontier vision-language model try to play a platformer for more than a few seconds, you know the arc is predictable: a promising first jump, a moment of hesitation, then a dead-end pattern of button mashing or total paralysis. The core challenge isn’t visual recognition—it’s coherent, extended decision-making under sparse feedback. In Super Mario Land, a single misstep can cascade into failure dozens of frames later, and the reward (finishing the level) arrives only at the very end, if at all. Turning a VLM into an agent that can sustain precise, reactive control for thousands of timesteps requires rethinking how we train these models, and Odysseus sets out to do exactly that by combining reinforcement learning with a lightweight critic architecture.
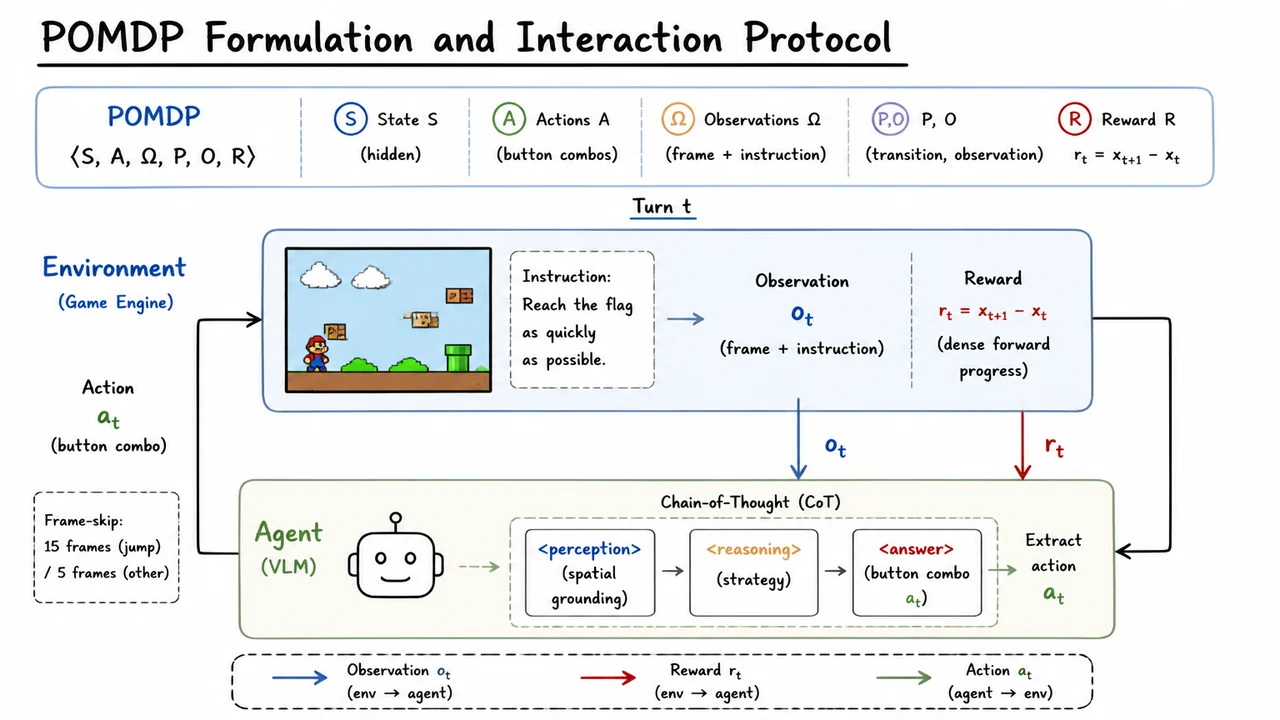
The task is deceptively hard. The agent sees raw RGB frames of the Game Boy screen at 60 fps and must output one of a small set of button combinations: move right, jump, dash, or some chord thereof. The physical world of Mario—gravity, momentum, enemy AI patterns—is never explicitly communicated to the model; it must infer the latent state from raw pixels and a brief textual instruction. Small errors compound: a slightly mistimed jump over a Goomba may cause the agent to land on it, lose a life, and then struggle to recover its previous progress. This is the textbook definition of a long-horizon control problem, where the temporal gap between an action and its consequences suffocates naive credit assignment.
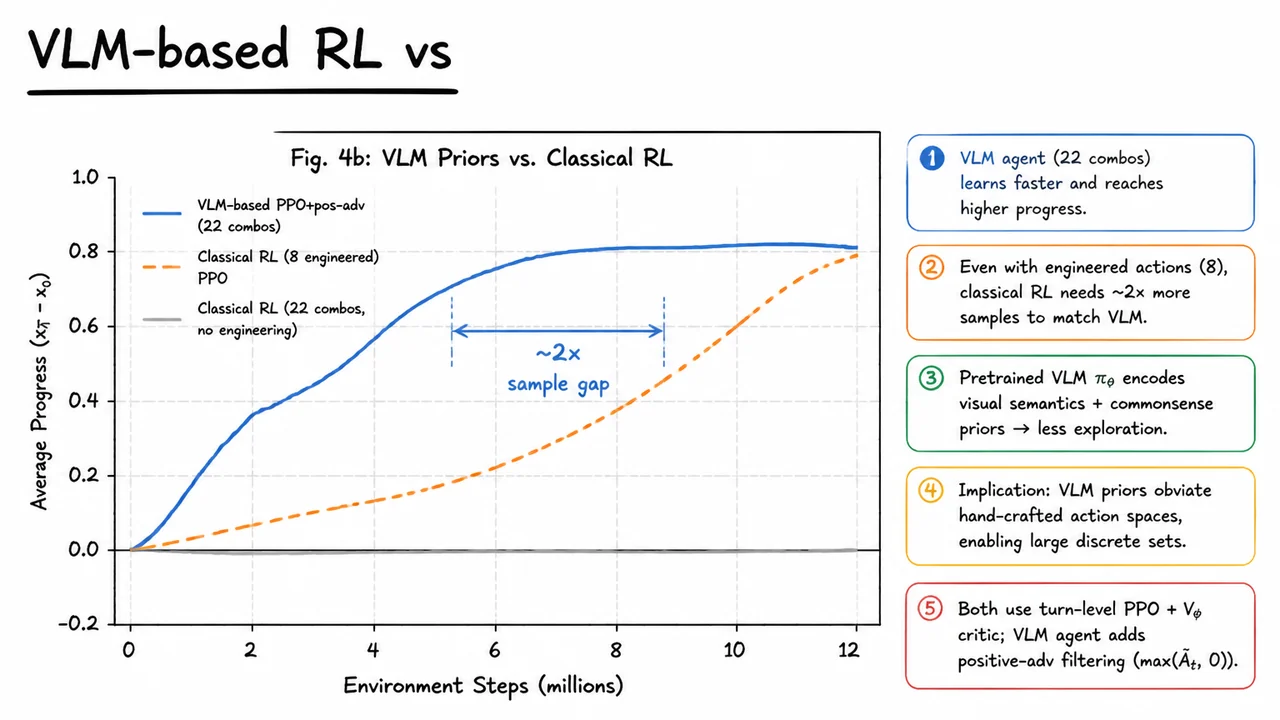
Why use a VLM at all? Historically, deep RL with compact CNNs has performed admirably on Atari games and even some platformers. But those agents are brittle, trained from scratch for every new game, and they cannot leverage natural language instructions, commonsense reasoning, or cross-game priors. A VLM, especially one pretrained on web-scale image–text data, brings a rich semantic understanding of objects (a pipe, a Koopa, a block) and a semblance of affordance reasoning. The hope is that this prior knowledge can dramatically improve sample efficiency and enable the kind of generalization that makes an agent play a user-described novel level without retraining. The challenge is that VLMs are enormous, their internal representations are not directly shaped for sequential decision-making, and fine-tuning them on a per-task basis with RL can be catastrophically unstable if done carelessly.
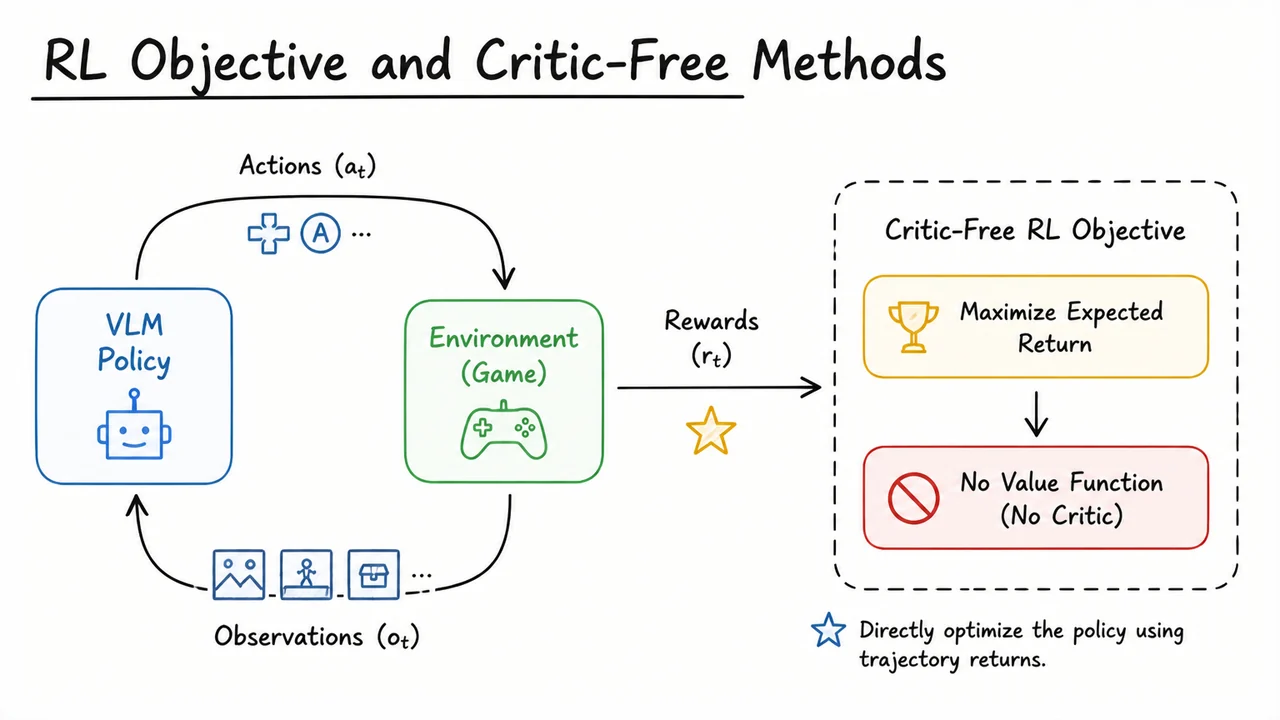
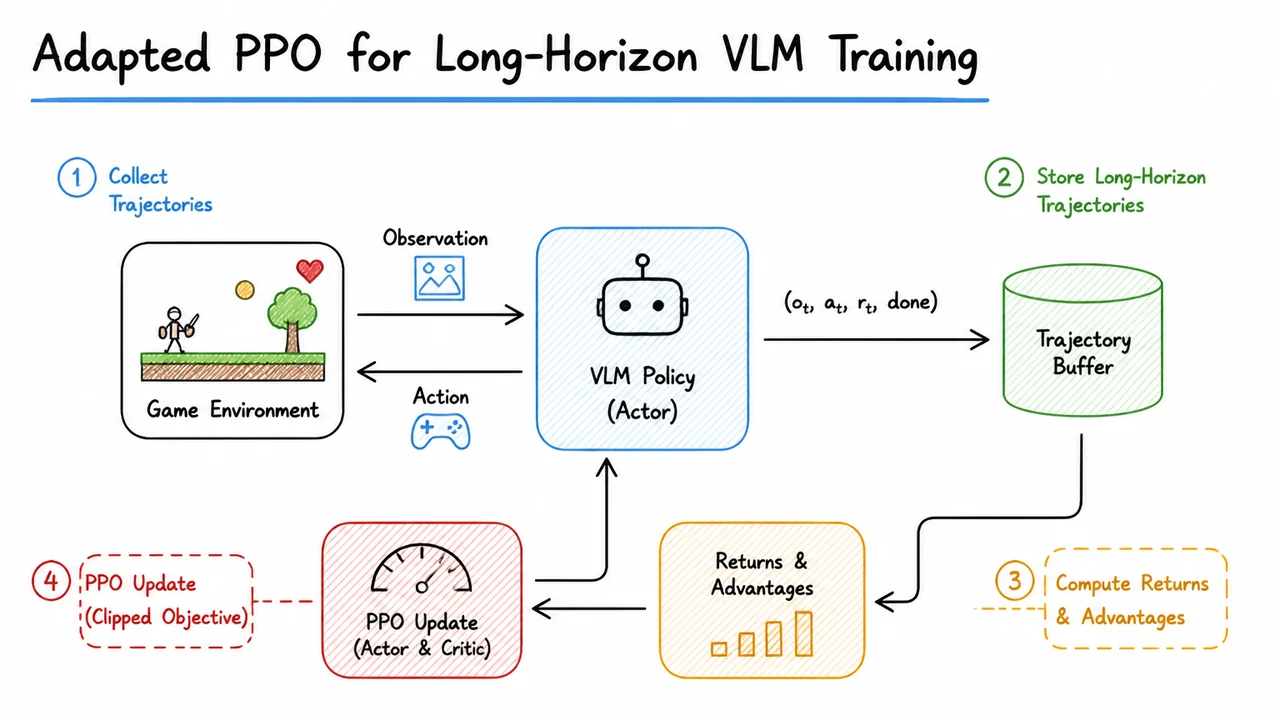
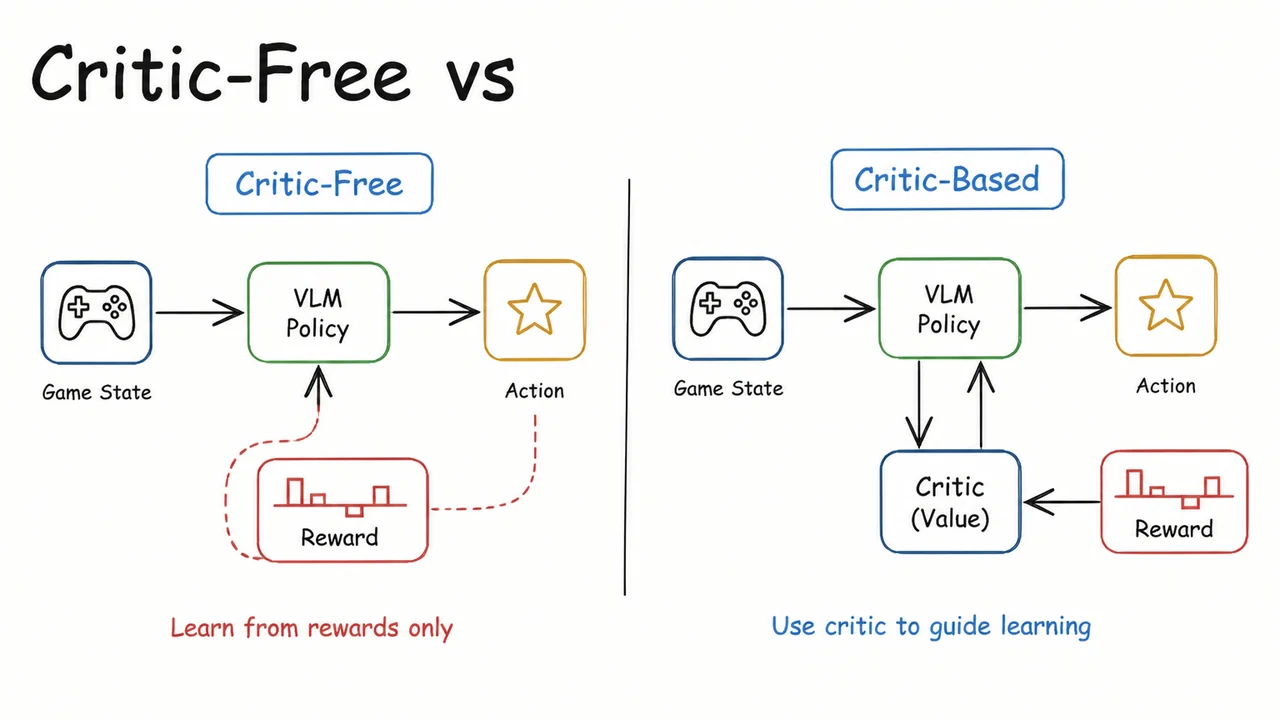
The standard RL formulation for such a game casts the VLM as a stochastic policy that maps the current observation and the human-readable goal to a distribution over discrete actions . The environment then transitions to and emits a scalar reward . In Super Mario Land, the reward signal is engineered to be slightly denser than the final win—typically a small positive reward for progressing rightward and a penalty upon death—but it is still extremely noisy. With a purely policy-gradient approach like REINFORCE, the gradient estimator has high variance because the action log-probability is weighted by the entire future cumulative reward, an estimate that fluctuates wildly across the long horizon. This is why a value function—a critic—becomes indispensable: it provides a learned baseline that reduces variance and enables more stable, sample-efficient updates.
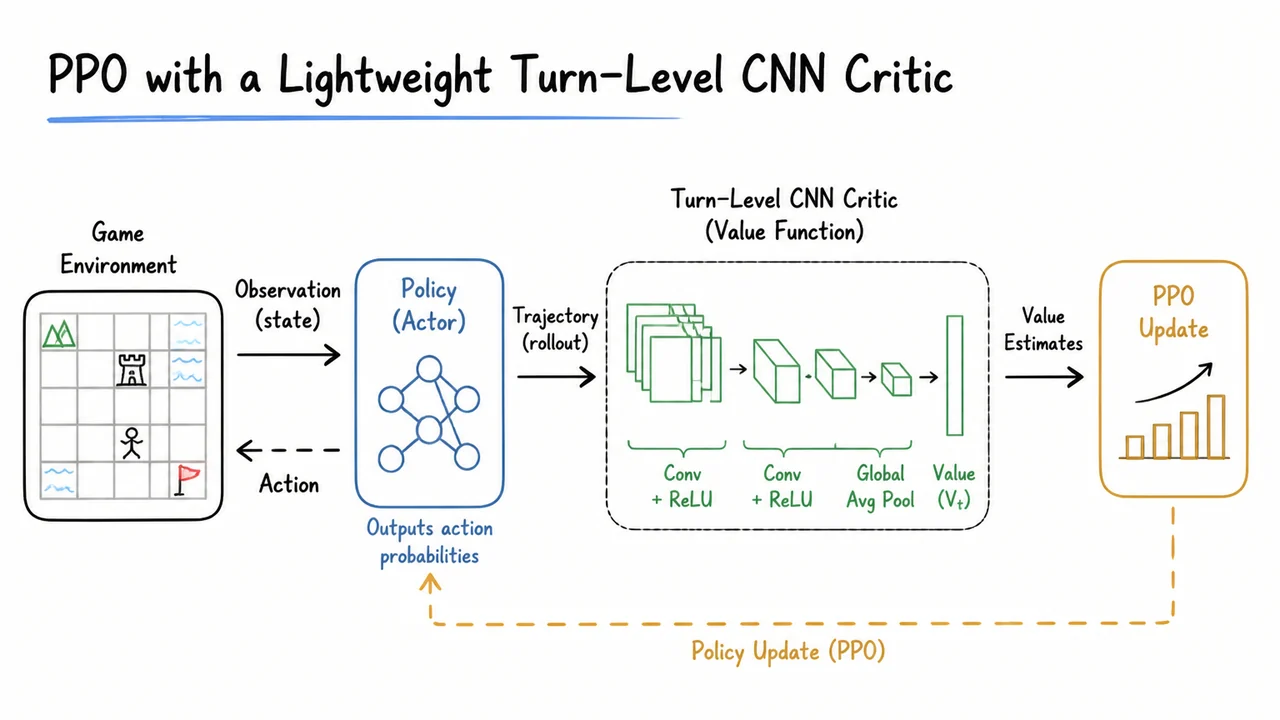
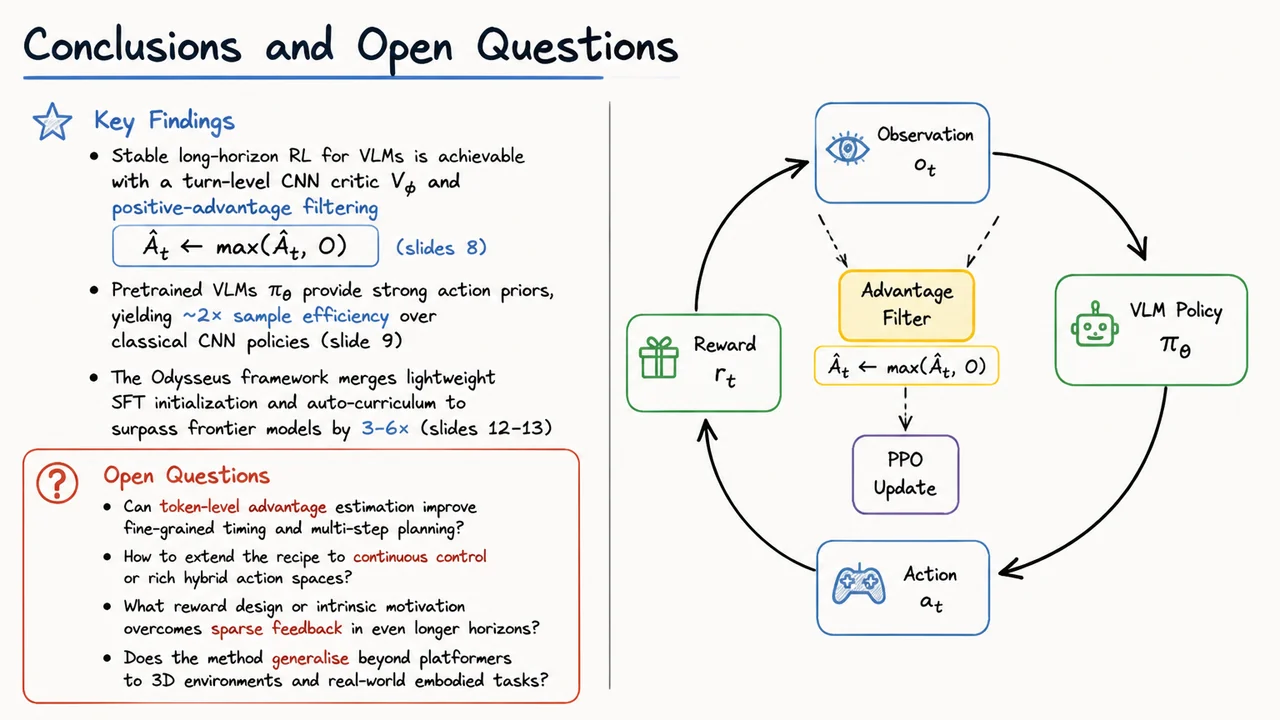
Enter PPO (Proximal Policy Optimization), the workhorse of modern RL. PPO clips policy updates to stay within a trust region, but it relies on an advantage estimate . For VLMs, the computation of is not trivial. You could augment the VLM with a value head that shares its visual backbone, but that couples the critic’s stability to the same gigantic transformer that needs to be updated cautiously. Odysseus instead pairs the VLM policy with a lightweight, turn-level CNN critic that operates on compact summaries of the game state. This separation decouples the heavy visual-language reasoning (where a few updates can destabilize the policy) from the fast, low-variance value estimation needed for stable PPO. The critic is quick to train and can be aggressively updated to provide reliable advantage signals, while the VLM policy is updated more conservatively—sometimes only on actions where the estimated advantage is positive, a trick we’ll unpack later.
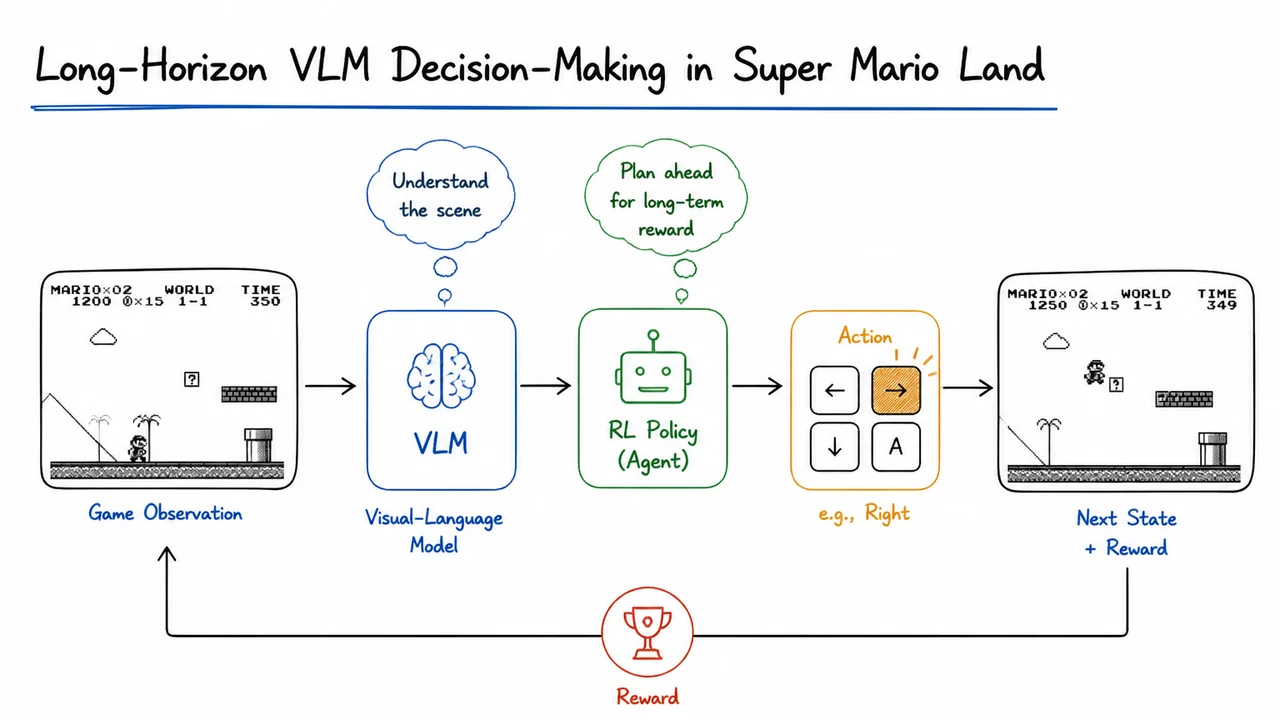
The visual below captures the high-level architecture of this decision-making loop. It depicts an agent observing a screen from Super Mario Land, processing it through a VLM module that outputs both an action and, optionally, a textual reasoning trace, while a separate CNN critic consumes a compressed visual representation (or a dedicated feature map) to estimate the state’s value. The diagram emphasizes the two-stream design: the heavy VLM for policy and the lightweight critic for advantage estimation, with the environment feedback flowing back into both. Importantly, the VLM’s policy is not constantly retrained from scratch; it builds on pretrained knowledge, and the RL pipeline is carefully gated to preserve that knowledge while adapting to the game’s physics and control demands. This separation is the key that makes long-horizon RL with VLMs feasible, avoiding the variance explosion that plagues critic-free methods and the slow, unstable fine-tuning that comes from coupling the critic too tightly to the huge model.