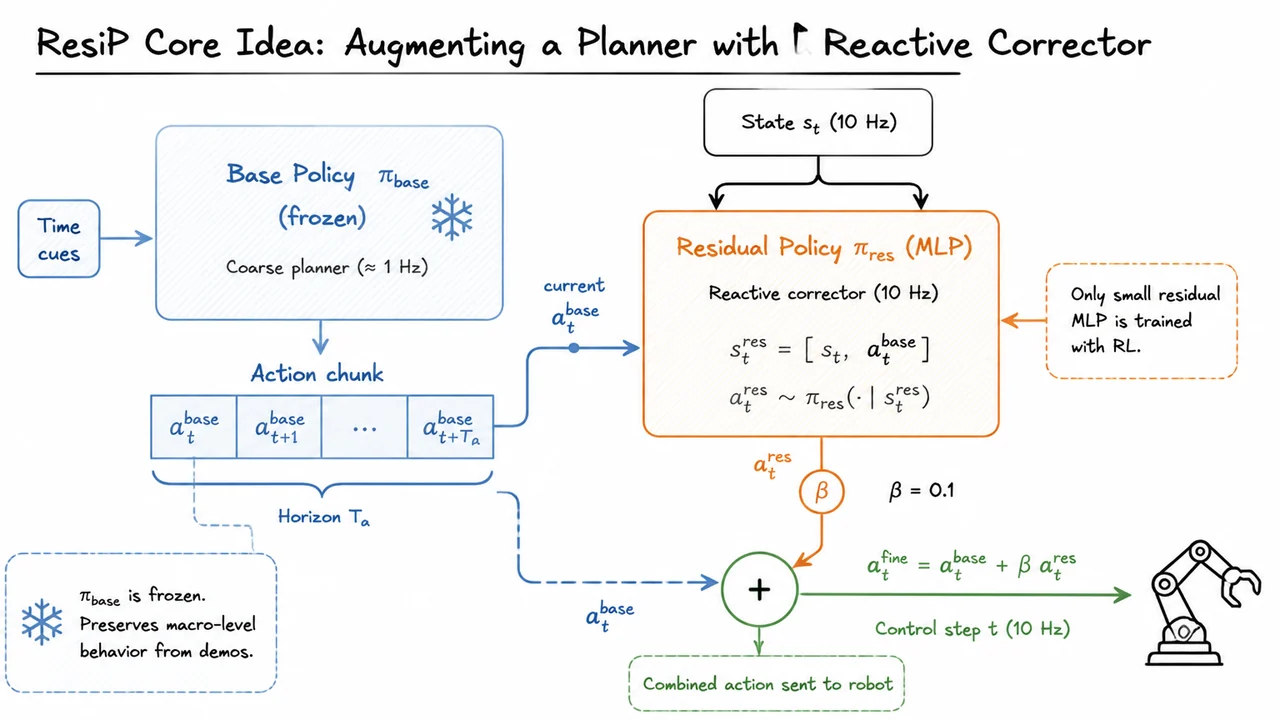
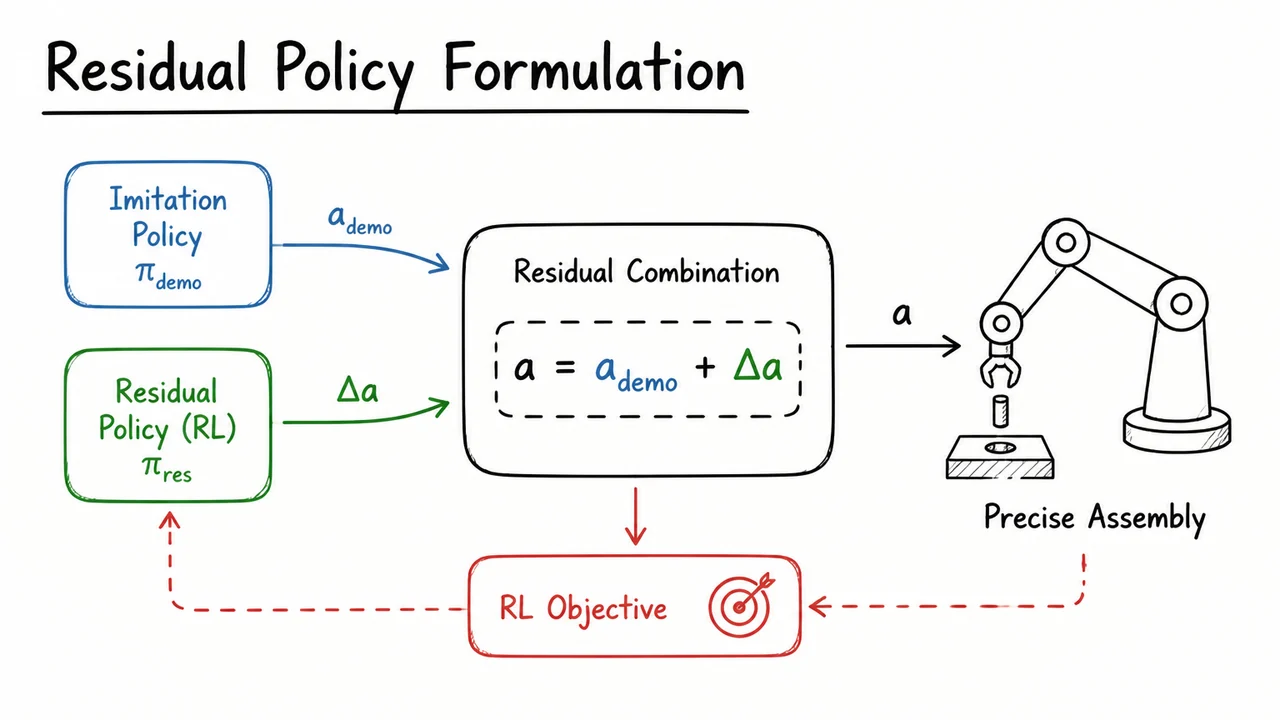
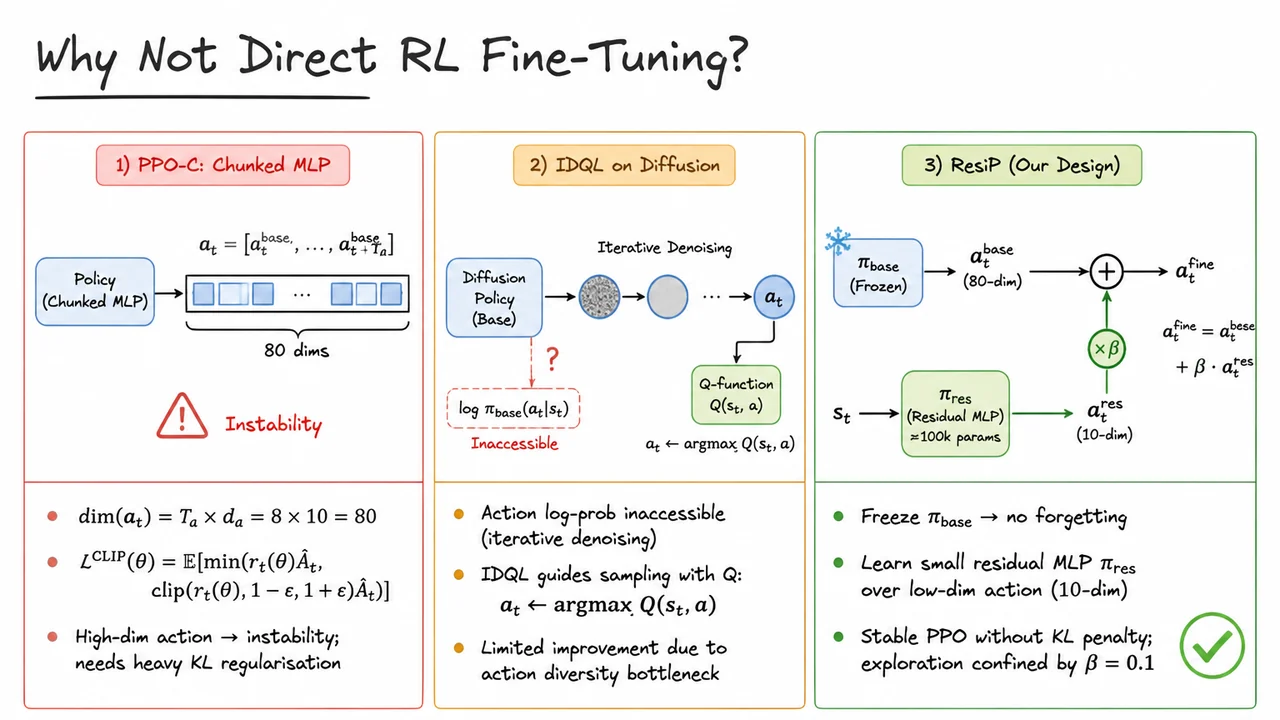
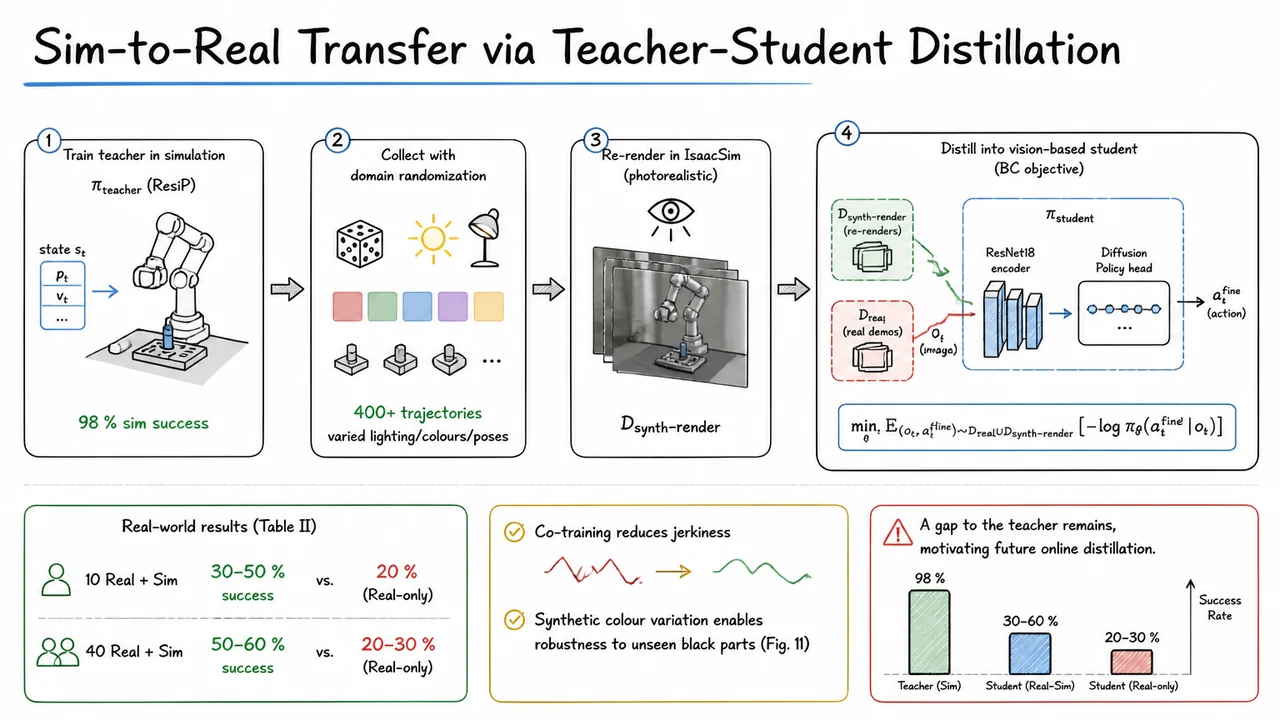
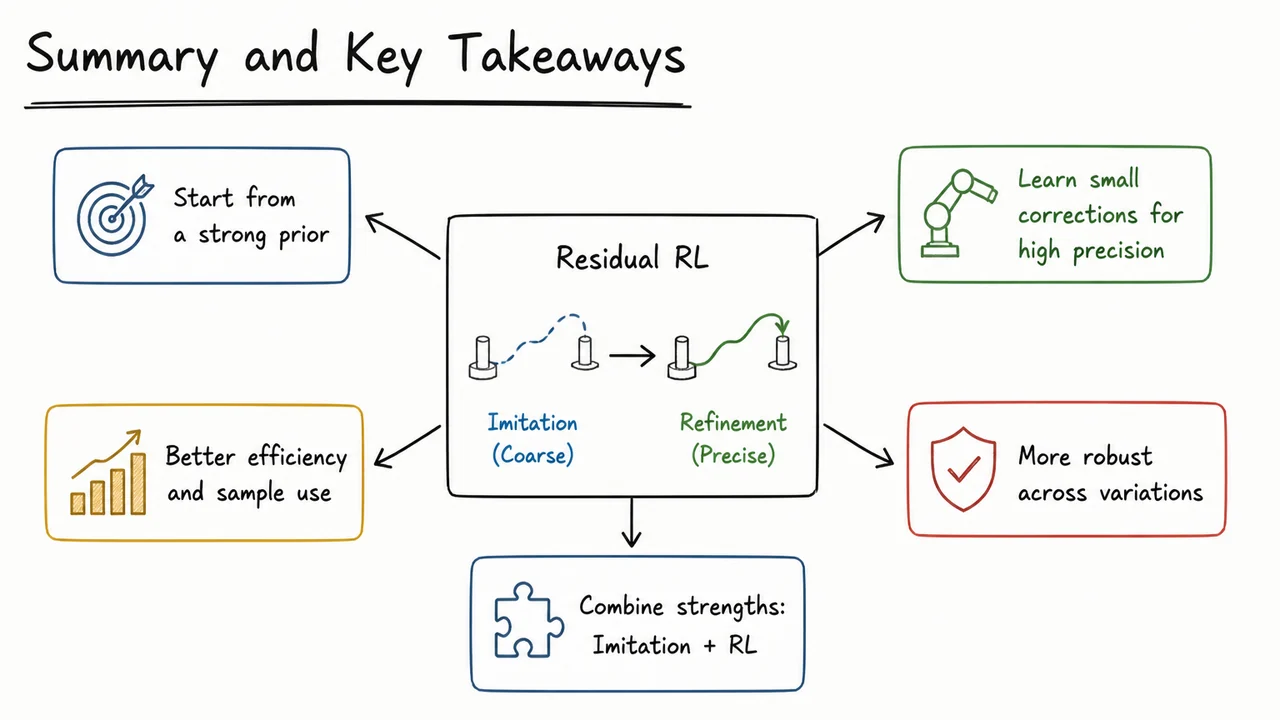
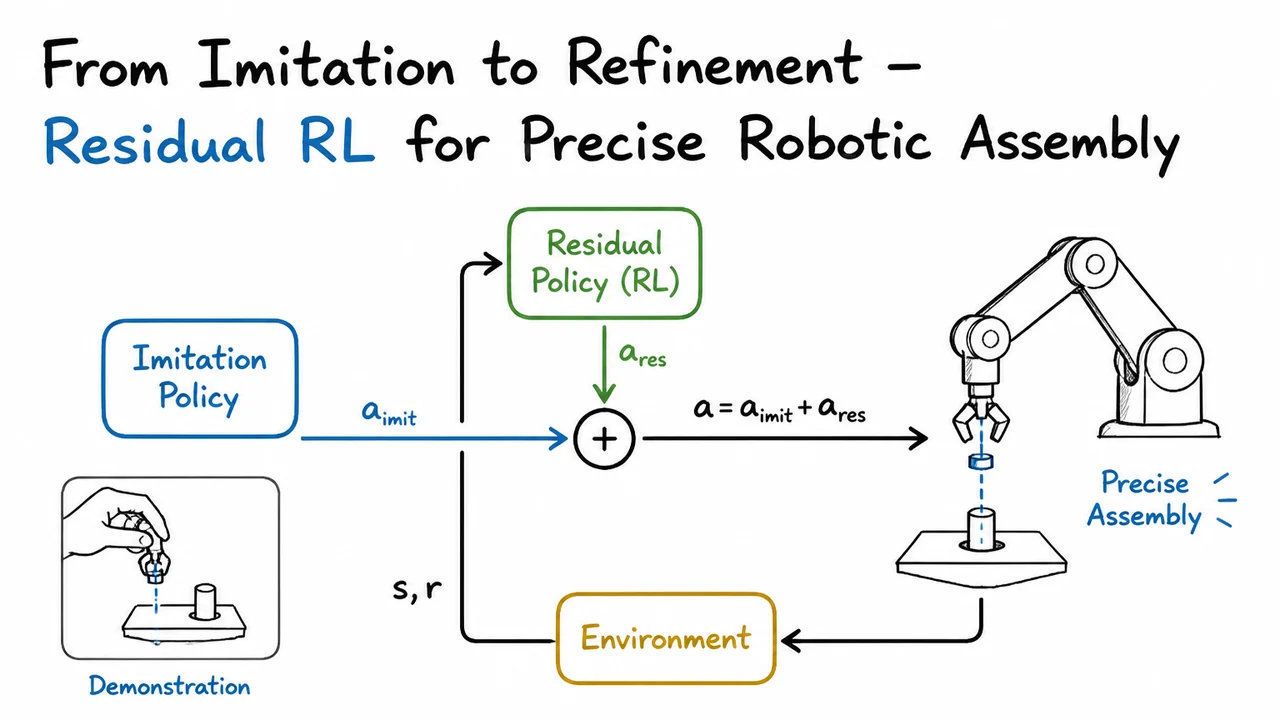
From Imitation to Refinement – Residual RL for Precise Robotic Assembly
1. Precision Assembly: A Hard Problem for Imitation Learning
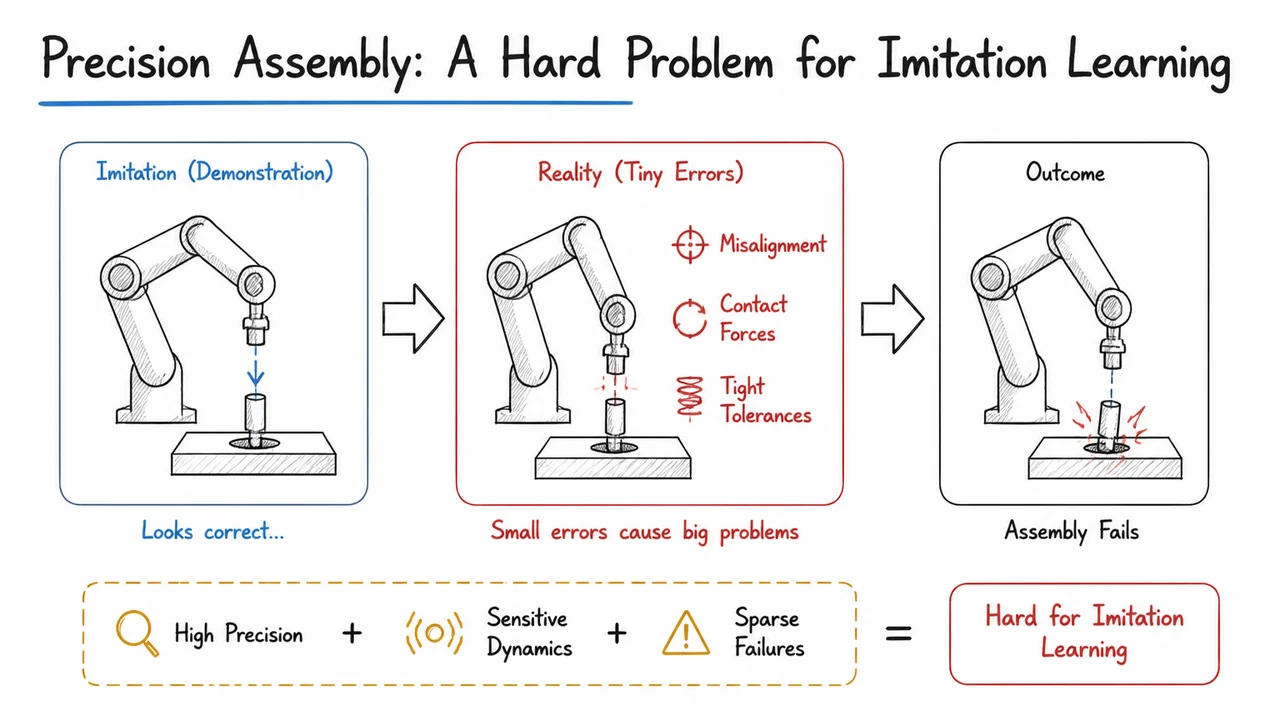
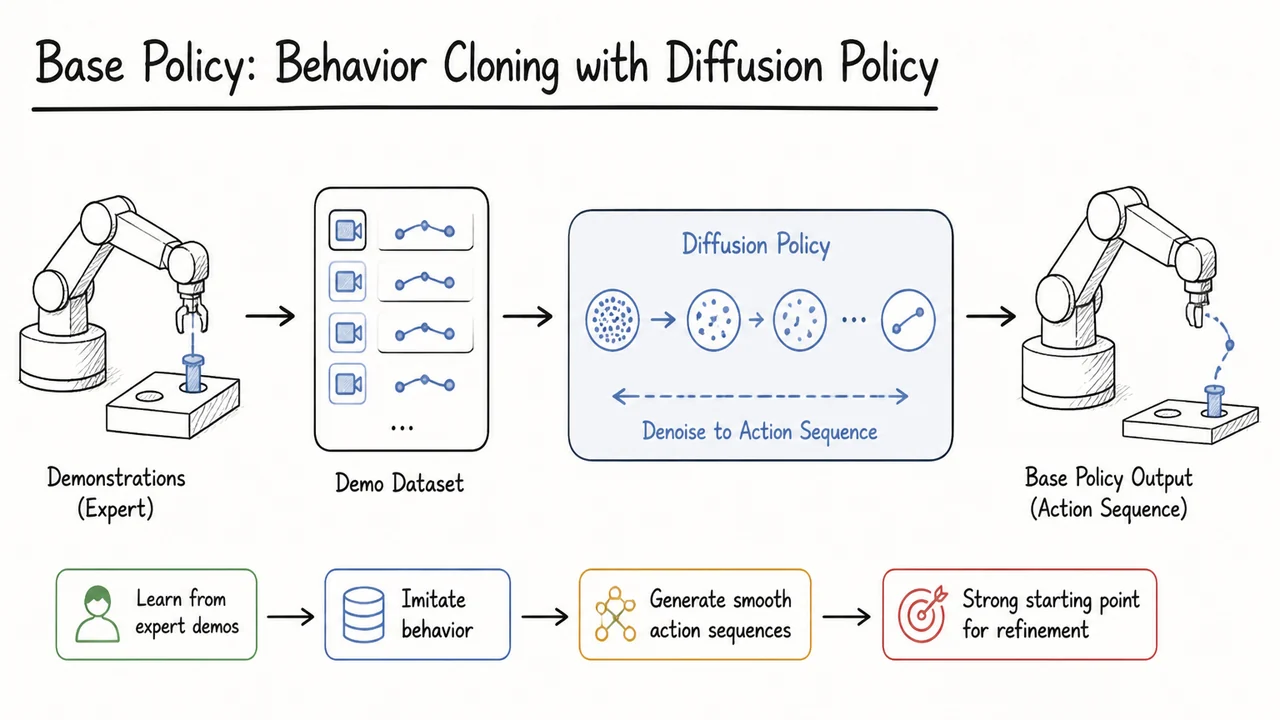
Imagine teaching a robot to plug a delicate connector into a port with sub‑millimeter clearance. The task demands precision, yet the robot learns from human demonstrations: someone teleoperating the arm, guiding it slowly to the target. Humans naturally correct micro‑misalignments using visual feedback, but the robot sees only a stream of joint positions and gripper commands. The naive approach—record the demo trajectories and train a policy to reproduce them—is behavior cloning (BC). For standard pick‑and‑place tasks, recent advances like action‑chunking transformers have made BC remarkably effective. However, high‑precision assembly exposes a set of stubborn failure modes. This section unpacks why such tasks remain a hard problem for imitation learning, setting the stage for a refinement strategy that goes beyond cloning.
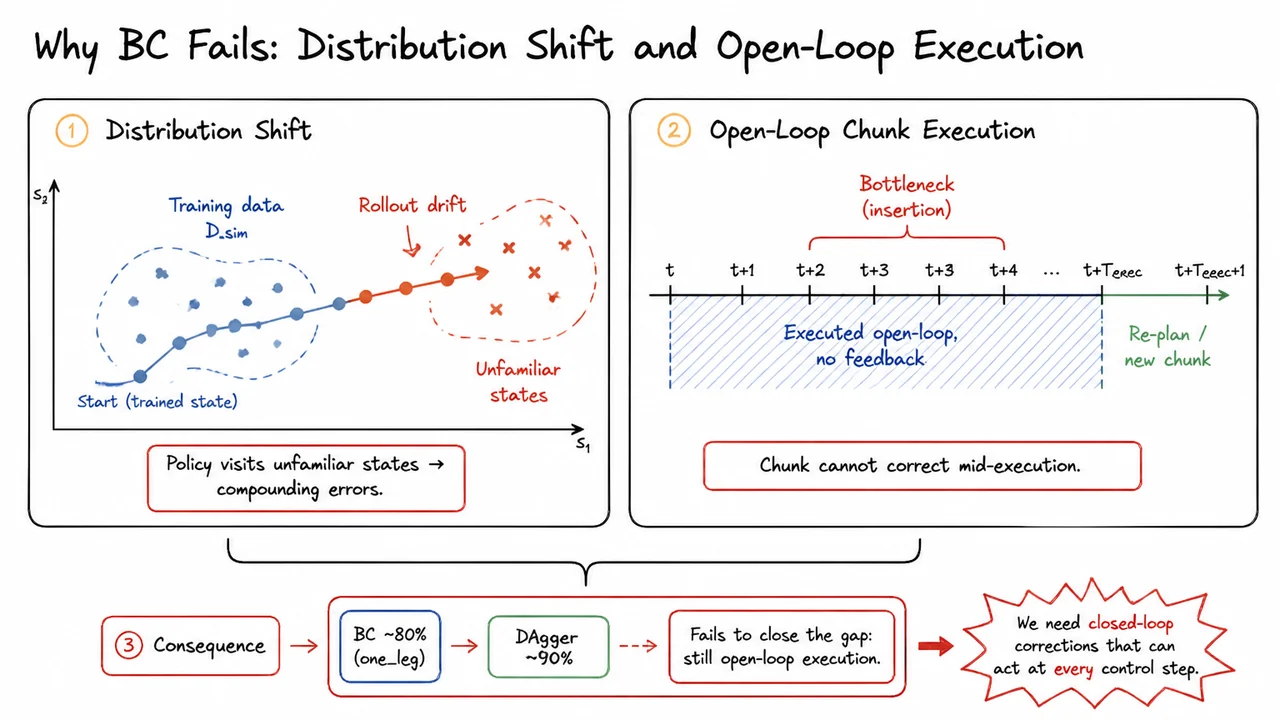
The central tension lies in the nature of the imitation data. Demonstrations provide expert trajectories, but they are on‑policy samples from the human’s own policy, not the robot’s. When a BC policy deviates even slightly from a demonstrated state—perhaps because the gripper is a millimeter off, or the peg encounters unexpected friction—it enters states that the training distribution never covered. The learned mapping from observation to action becomes unreliable, and the error compounds. In high‑precision assembly, tolerance is essentially zero: a miniscule orientation error turns a successful insertion into a failed jam. The policy, trained to minimize error on the training set, has no incentive to recover from such deviations because it never saw them during training. This is the distribution shift problem, and in tight‑clearance tasks it is catastrophic.
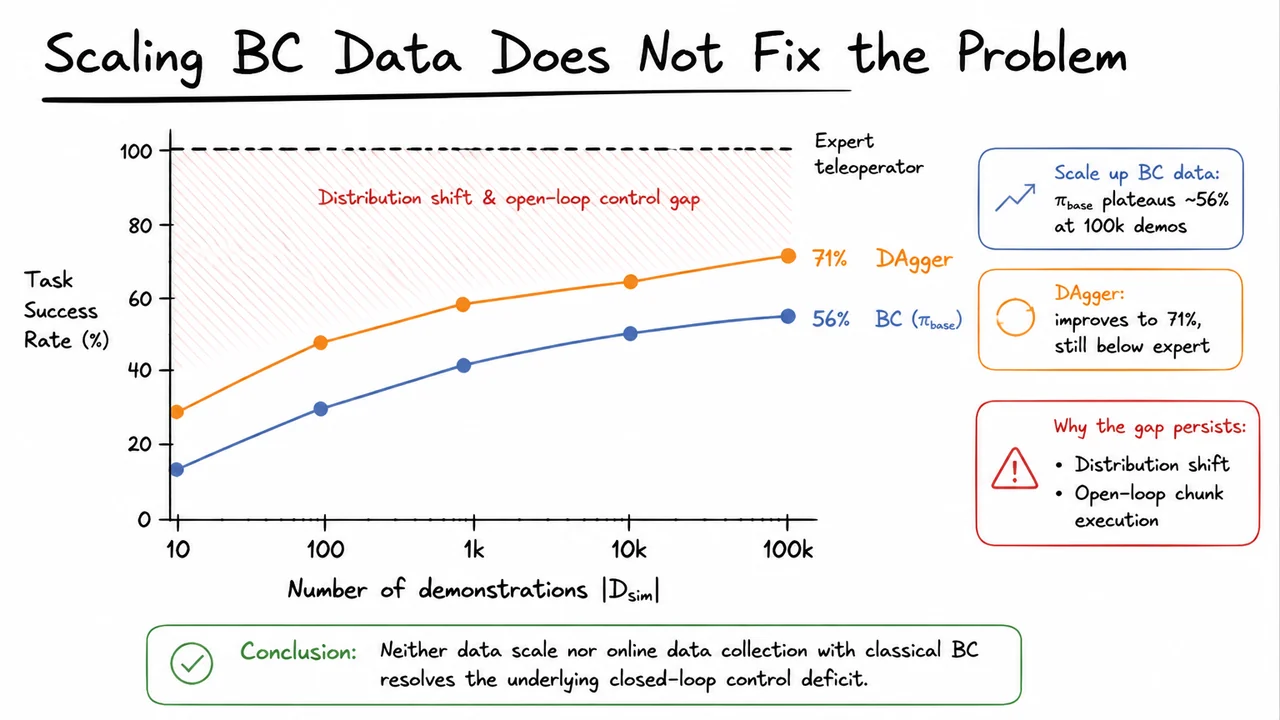
Action chunking, which predicts a sequence of future actions at once, amplifies the difficulty. Chunking improves smoothness and reduces the effective horizon during training, but at deployment it introduces open‑loop execution within each chunk. The robot commits to, say, actions before reassessing the state. If the initial state already contains a small error, executing the whole chunk blind can drive the end‑effector far off course. In assembly, a single chunk that prescribes a straight‑line approach might collide with the chamfered edge of the hole; a closed‑loop controller would detect the contact force and adjust, but the chunked BC policy naively continues pushing. This open‑loop drift is a primary cause of performance saturation: beyond a certain dataset size or model capacity, BC’s success rate plateaus well below 100% because no amount of data can cover every possible off‑track scenario.
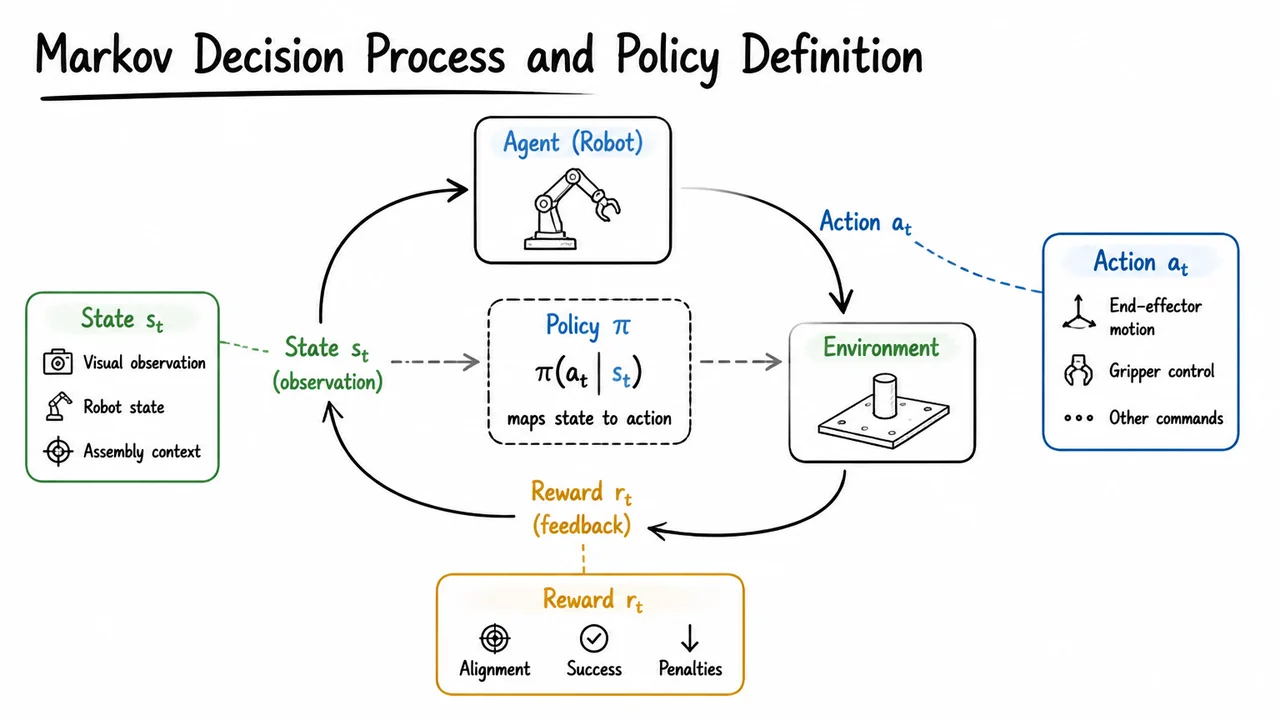
Mathematically, we can view the chunked policy as producing a trajectory conditioned on the current observation . The ground‑truth expert action sequence would bring the robot to the intended next state, but the learned is an imperfect approximation. The rollout error after steps depends on the dynamics : . Even if the average per‑step action error is small, the accumulated state deviation can grow super‑linearly, especially when the dynamics involve contact that abruptly changes the system’s response. The standard BC objective treats each step equally, ignoring the cascading nature of errors. In precision tasks, this ignores the fact that a 1‑degree orientation error at the start of insertion causes a completely different contact interaction than a perfect alignment—yet the squared loss penalizes them identically during training.
Why not simply collect more data? Extra demonstrations cover more variations, but they are still near‑optimal. They rarely include recovery behaviors—dropping the peg, retrying, wiggling—because the human demonstrator rarely makes mistakes. The distribution of states in the dataset remains concentrated around successful trajectories. The policy never learns to handle the fringe states it will inevitably visit due to its own imperfections. This is the infamous “covariate shift” cycle: imprecision → distribution shift → larger error → further shift. Scaling up data collection eventually hits diminishing returns, and for many real‑world assembly tasks, the cost of thousands of demonstrations becomes prohibitive anyway.
A final, subtle layer of difficulty comes from the sensing gap. Human demonstrators rely on vision and haptics that are richer than the robot’s available sensors. A policy trained solely on wrist‑mounted camera images or joint states must infer alignment from impoverished signals. Even a perfectly cloned trajectory can fail if the downstream vision system introduces latency or noise that the demonstrator never encountered. The combination of distribution shift, open‑loop chunk commitment, and sensor mismatch creates a barrier that pure imitation learning, even with modern architectures, struggles to cross.
The visual below captures this predicament succinctly. A robotic gripper is shown attempting to insert a narrow peg into a hole, with a clear millimeter‑scale gap indicating misalignment. Arrows and handwritten‑style labels highlight how distribution shift drives the policy into unseen states, how open‑loop action chunks ignore that error for the chunk duration, and how the accumulated deviation leads to a hard contact or jam. The diagram serves as a touchstone for the central claim: high‑precision assembly is not just a harder version of pick‑and‑place—it is a qualitatively different challenge where small errors cascade into unrecoverable failures. Recognizing this motivates the need for a refinement process that can actively correct such errors, a process we will develop in the coming sections.