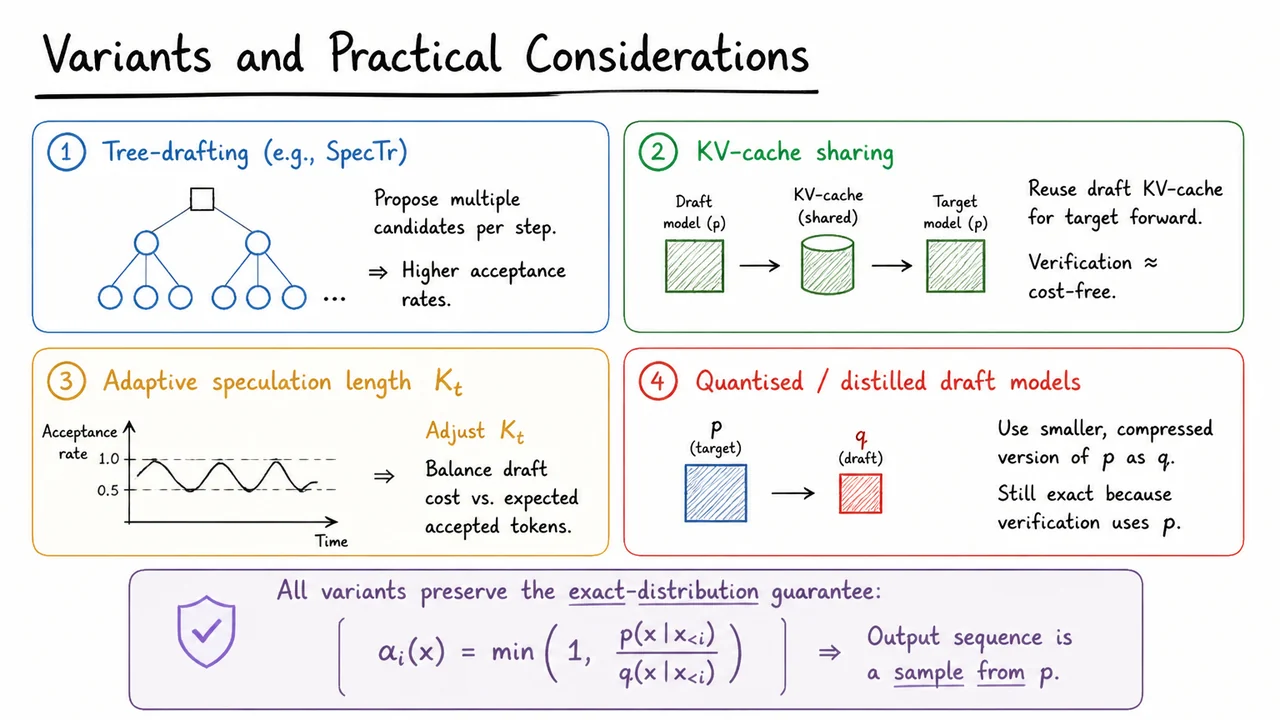
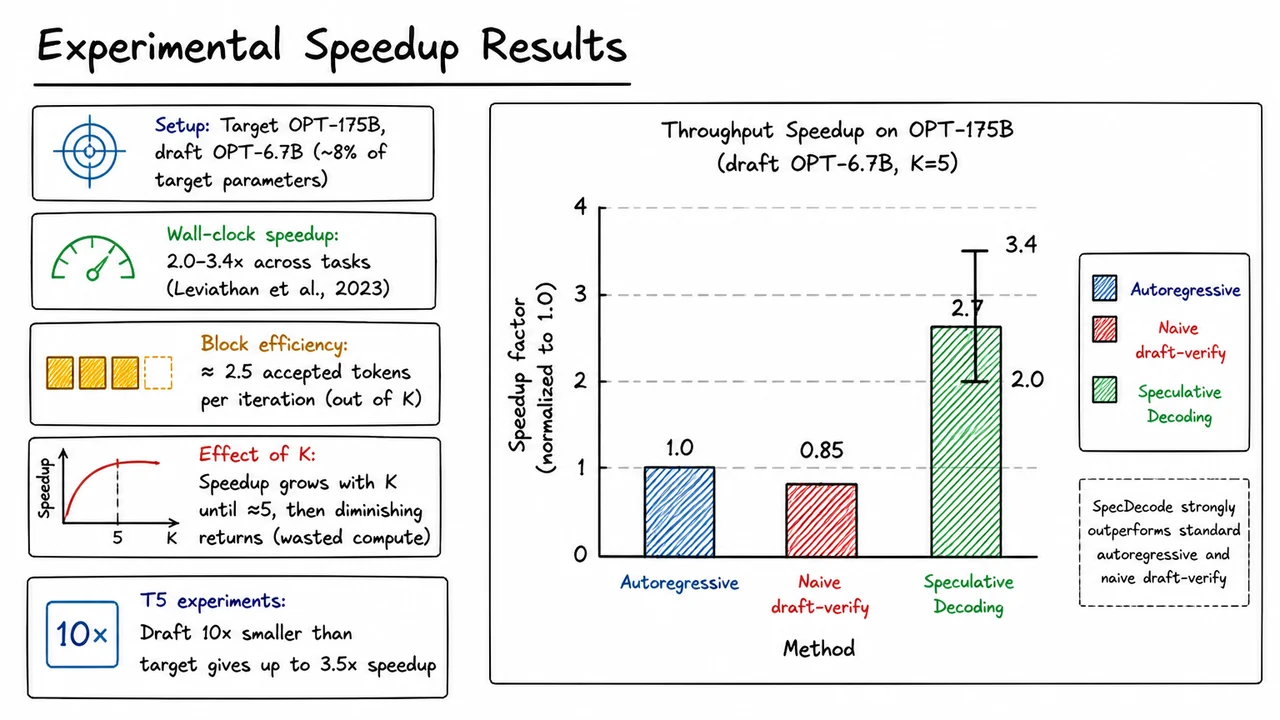
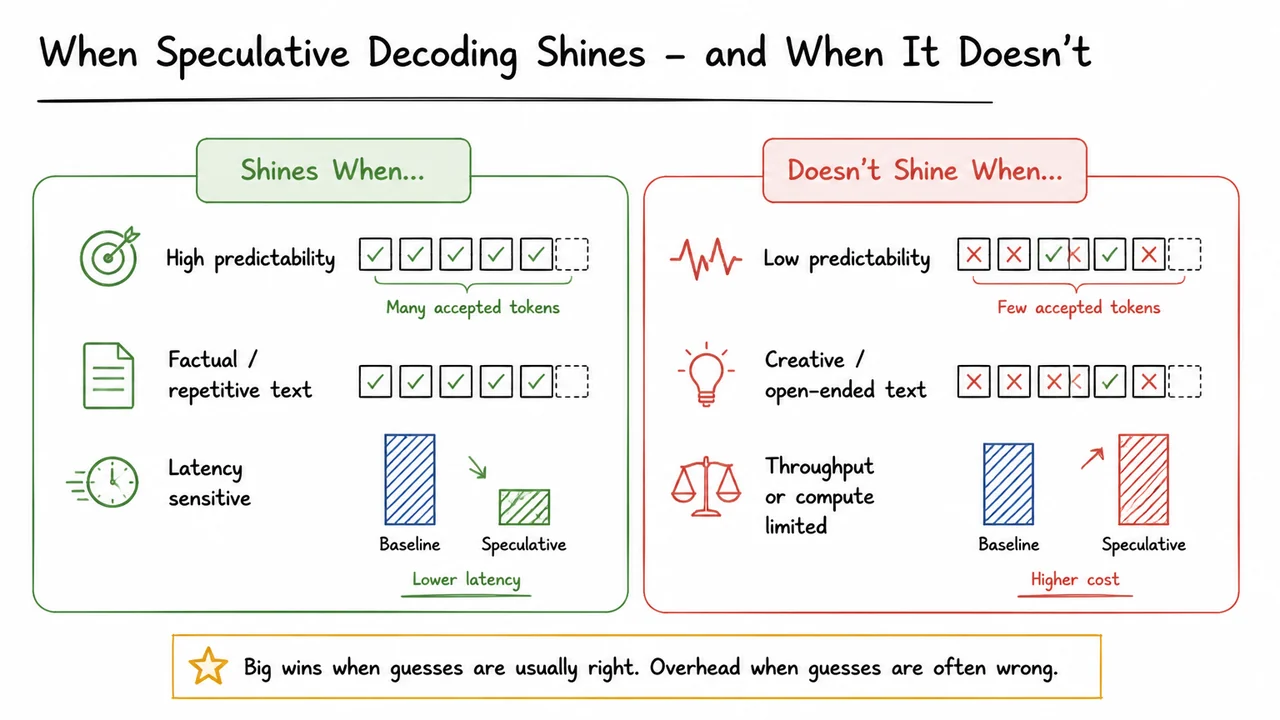
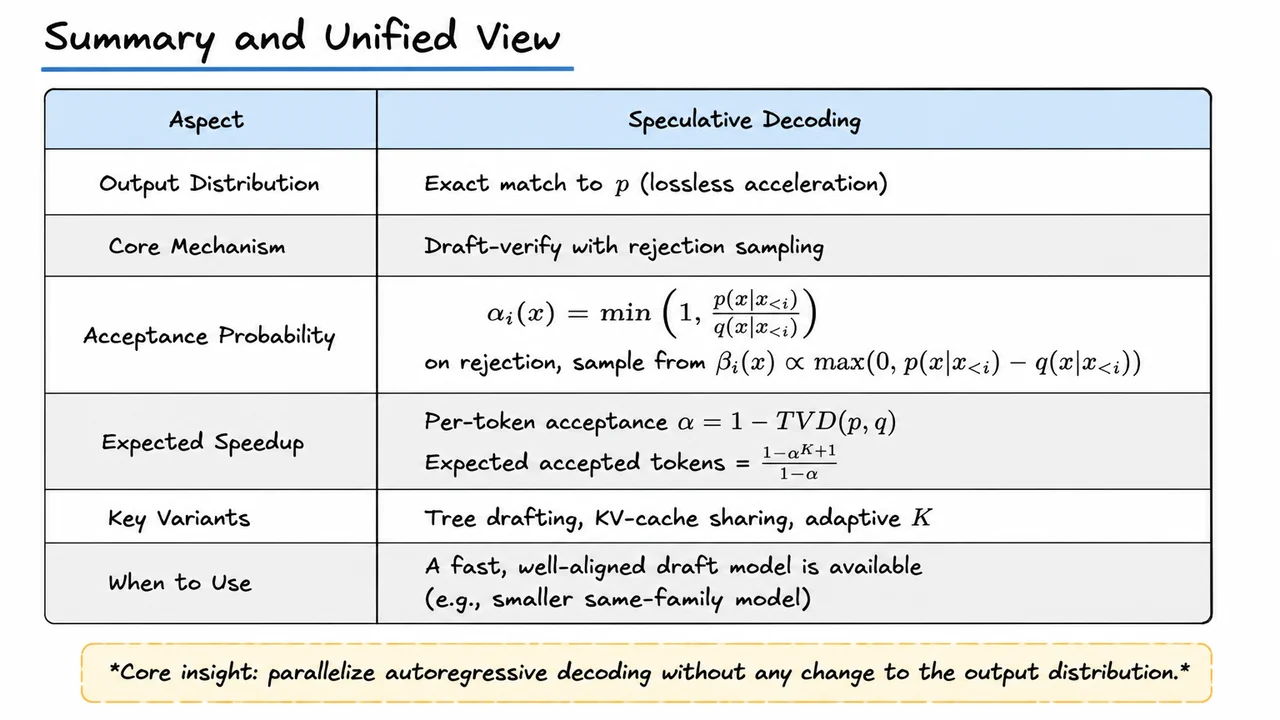
Speculative Decoding: Lossless Acceleration for Large Language Models
1. The Speed Wall: Autoregressive Decoding is Too Slow
If you have ever waited for a large language model to generate a long response, you know the pain: the text appears token by token, each step draining precious milliseconds, yet the overall pace feels glacial. This sluggishness is not an accident of poor engineering; it is a direct consequence of the autoregressive decoding paradigm that almost every high-quality generative model uses today. To understand why, we need to unpack the underlying computational mechanics.
At each generation step, the model must evaluate the entire sequence of previously generated tokens to produce the next one. That means for token , the model computes a forward pass over the full prefix , regaining the contextual representation that conditions the distribution . Because each new token depends on the complete state computed from the previous tokens, the decoding process is inherently sequential: you cannot start computing before you know . The result is a cascade of forward passes that cannot be overlapped or batched across time steps.
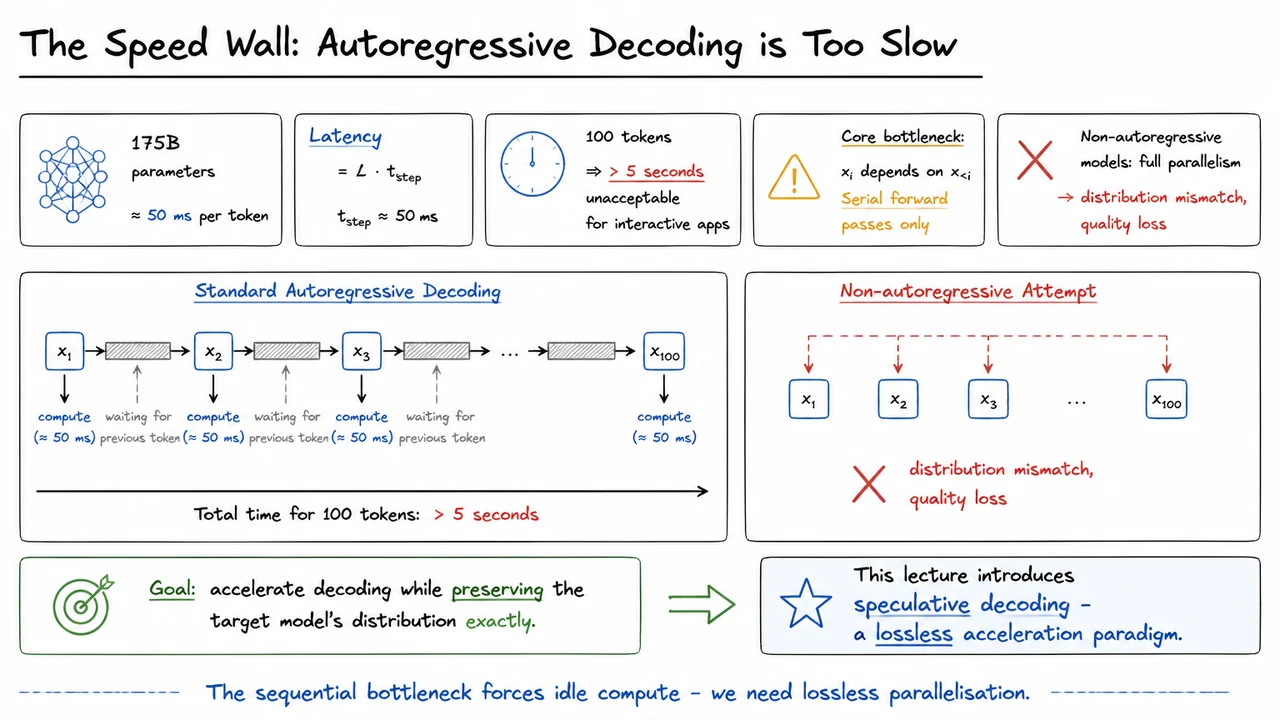
For a concrete illustration, consider a large transformer with 175 billion parameters—the scale of models like GPT-3. Running a single forward pass through such a network is expensive; on modern hardware optimised for large language models, the per‑token latency often hovers around 50 milliseconds. The total wall‑clock time to generate a response of length is therefore given by a simple linear relation: Plugging in realistic numbers yields a sobering figure: generating merely 100 tokens consumes more than 5 seconds. For interactive applications—chatbots, voice assistants, live coding assistants—this delay destroys the feeling of responsiveness and makes real‑time use impractical.
The intuitive urge is to parallelise the generation. If we could predict all tokens simultaneously, we would slash latency from to forward passes. Non‑autoregressive models attempt exactly that: they forgo the causal dependency and generate the whole sequence in one shot. But this shortcut comes at a steep price. Removing the sequential conditioning erases the precise causal structure that makes the target model’s output distribution so accurate. The result is a model whose joint distribution over sequences differs from the original—often visibly in the form of incoherent, repetitive, or semantically broken text. So while non‑autoregressive methods are fast, they sacrifice exact quality, making them unsuitable when every token matters.
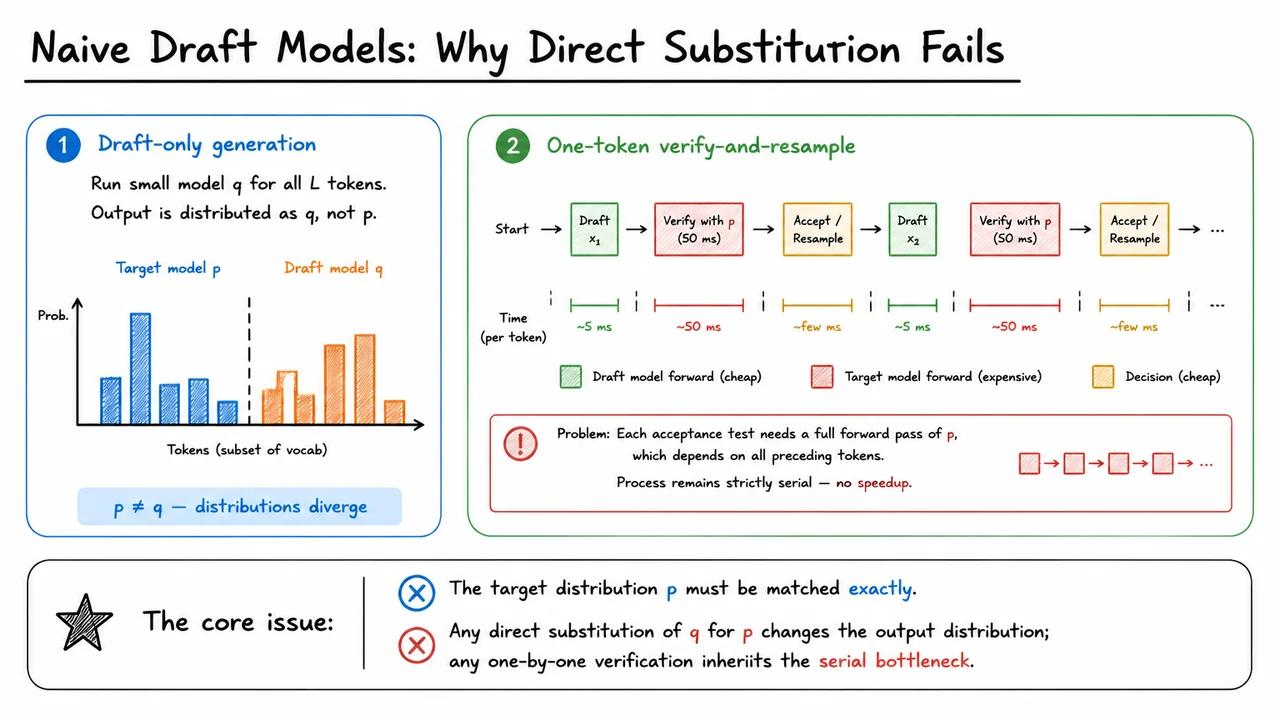
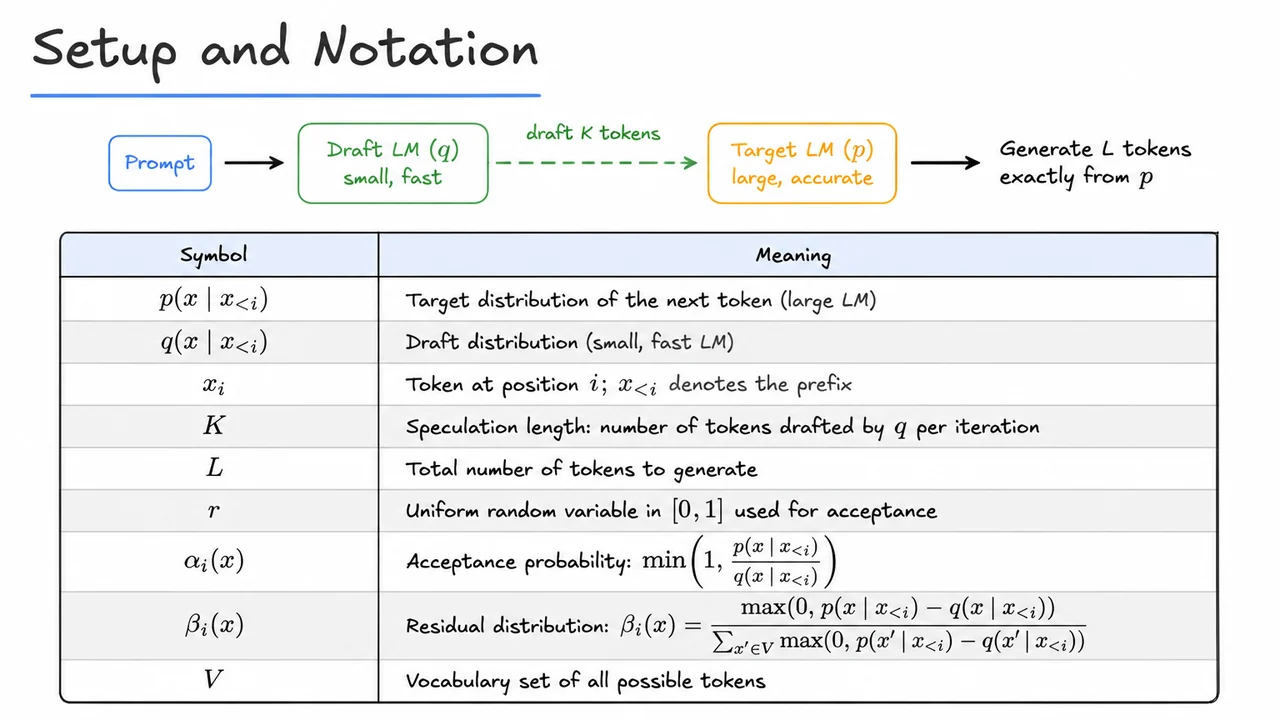
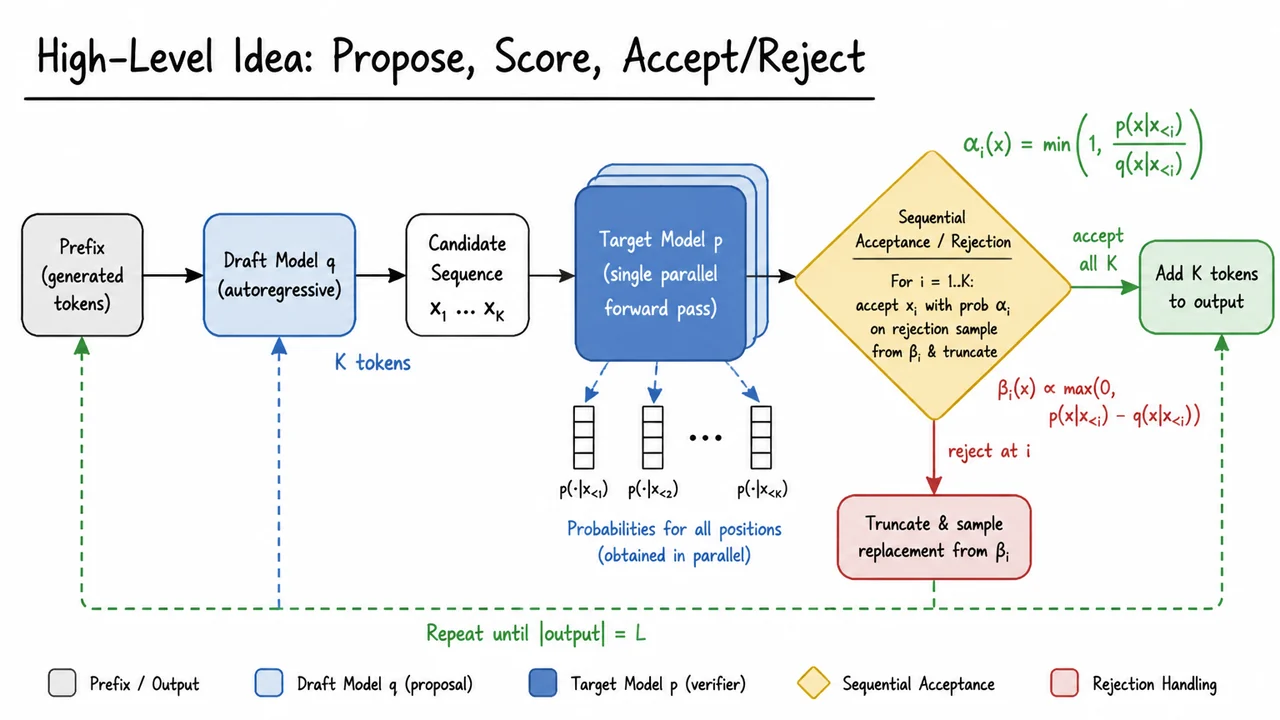
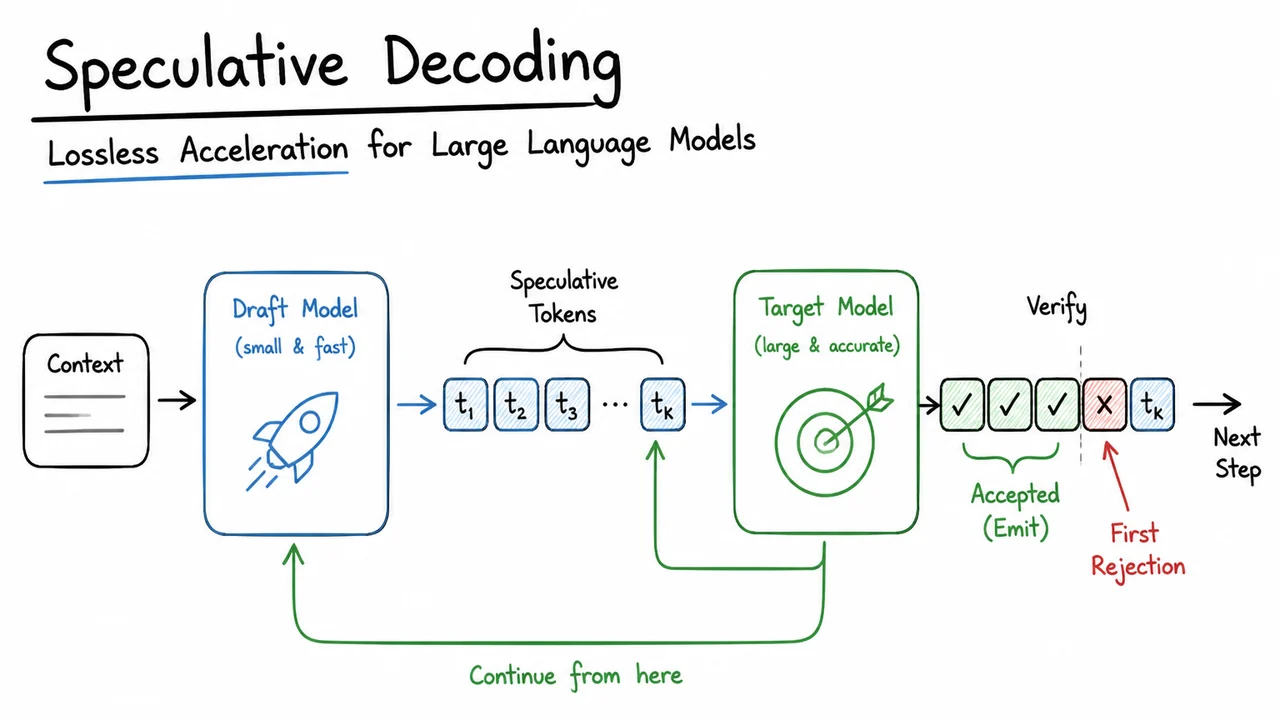
The challenge, therefore, crystallises into a strict requirement: we need an acceleration strategy that reduces the number of sequential costly forward passes without altering the output distribution one iota. That is, we must obtain samples such that each token is drawn exactly from of the target model, but with a total computational budget far below expensive target‑model evaluations. This is the “lossless parallelisation” problem. Its solution is what this lecture series will introduce: speculative decoding—a paradigm that preserves the exact probability distribution while unlocking nearly order‑of‑magnitude speedups on long sequences.
Before diving into the algorithmic machinery, it helps to visualise the nature of the speed wall and why naive attempts at parallelisation fail. The visual below is a conceptual diagram that dramatises the dilemma. On the left, we see a timeline of standard autoregressive generation: a horizontal chain of token boxes, each connected by arrows that force strict serial dependency, with conspicuous idle gaps between them representing the time spent waiting for a forward pass. The cumulative latency stretches past 5 seconds for just 100 tokens. On the right, a non‑autoregressive attempt appears: all tokens burst out almost simultaneously, but a bold red cross marks the result as “distribution mismatch, quality loss.” The contrast makes immediate the predicament: sequential execution yields exact quality but unbearable latency; naive parallelisation yields speed but destroys the very distribution we cherish.
This diagram is not just an illustration; it is a compact statement of the problem statement. The idle compute gaps in the autoregressive timeline are the hidden inefficiency that speculative decoding exploits. The red cross on the parallel attempt reminds us that we cannot simply discard the causal conditioning. Our journey will now lead us toward a principled strategy that pairs a fast, approximate draft model with the rigorous statistical backing of the target model to reclaim speed without surrendering a single bit of distributional fidelity.