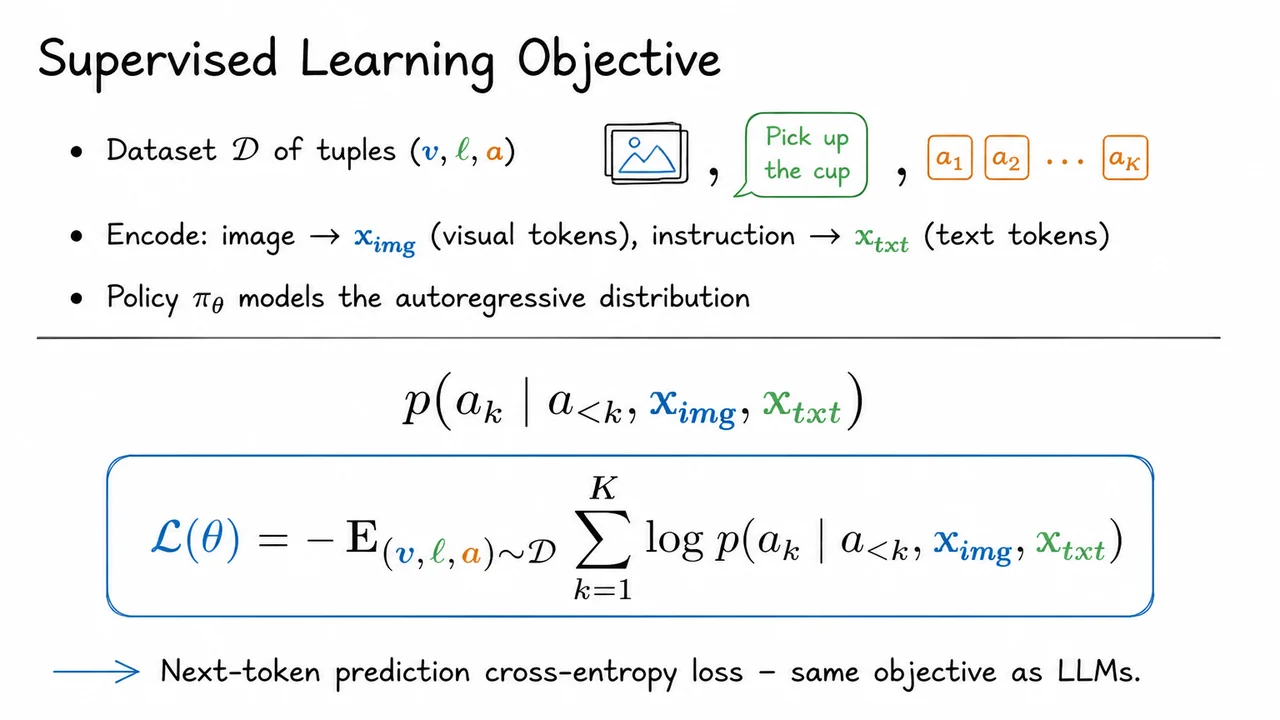
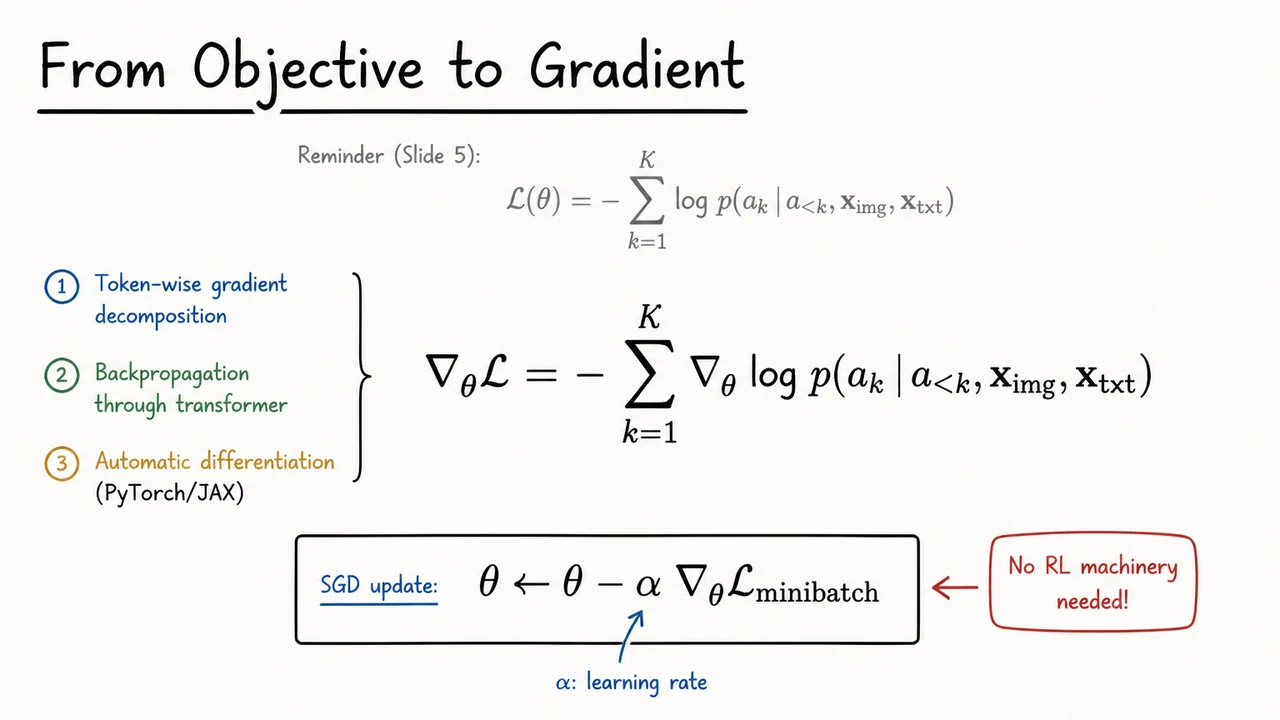
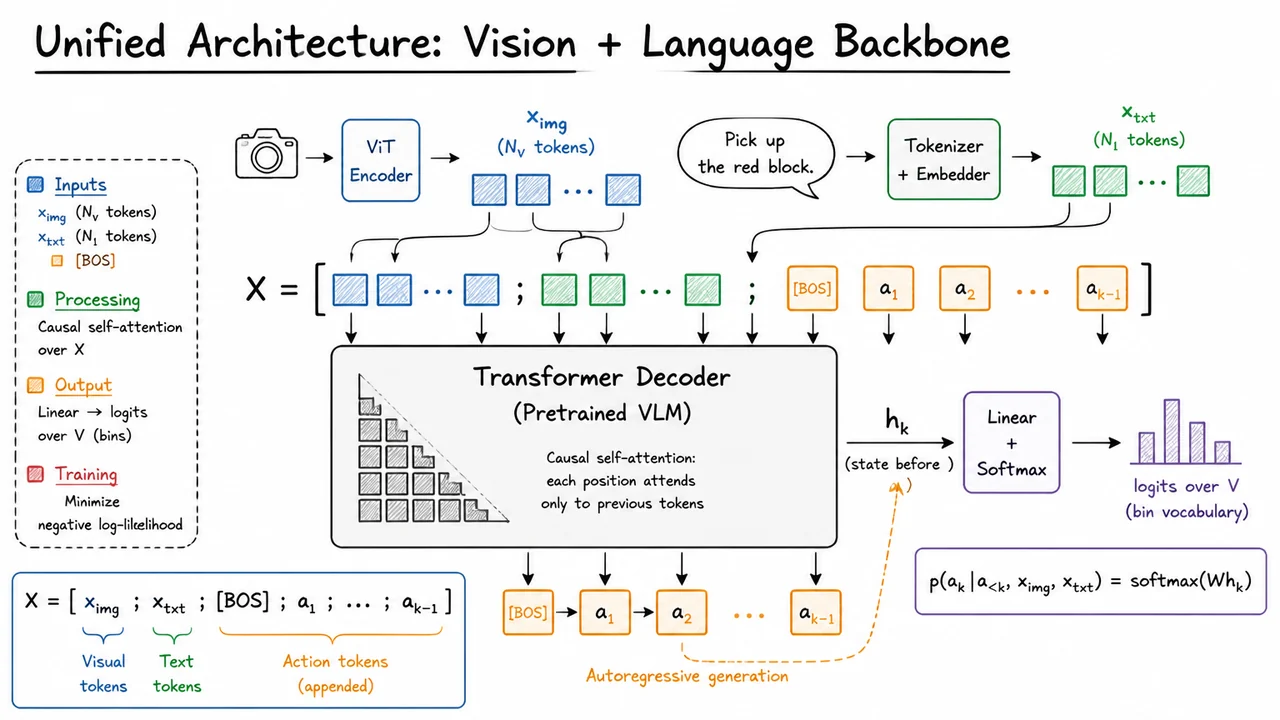
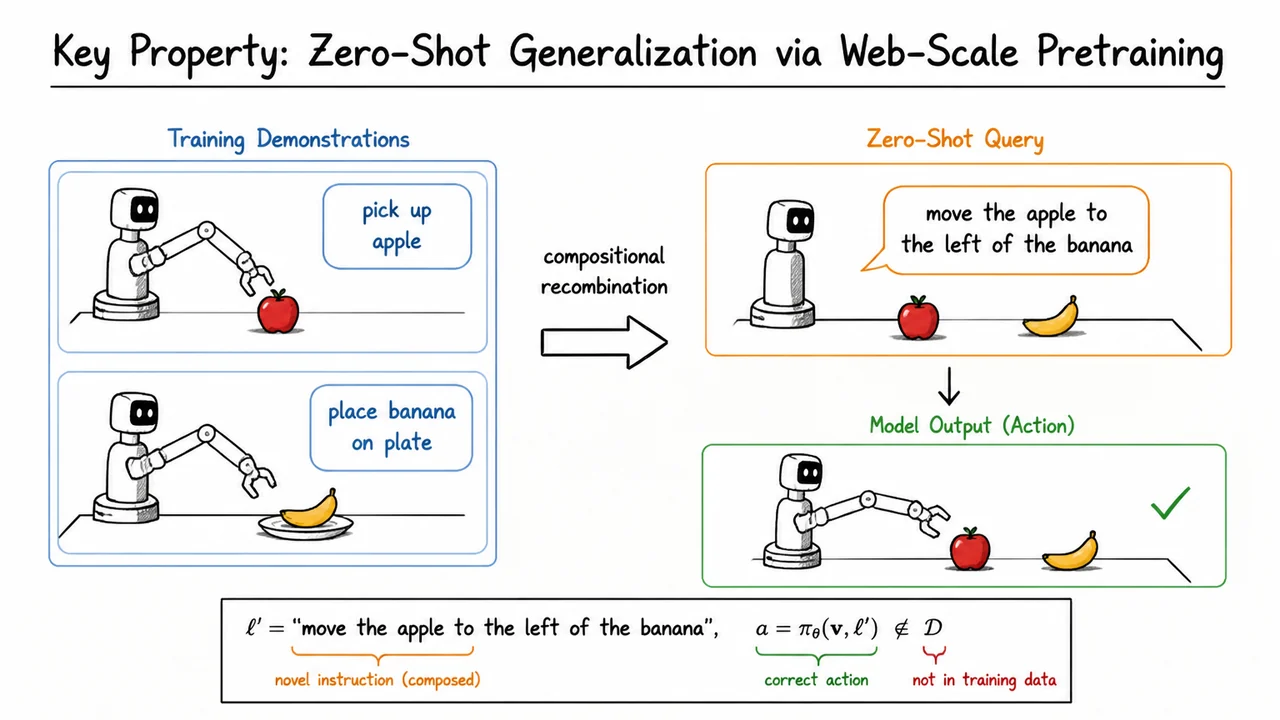
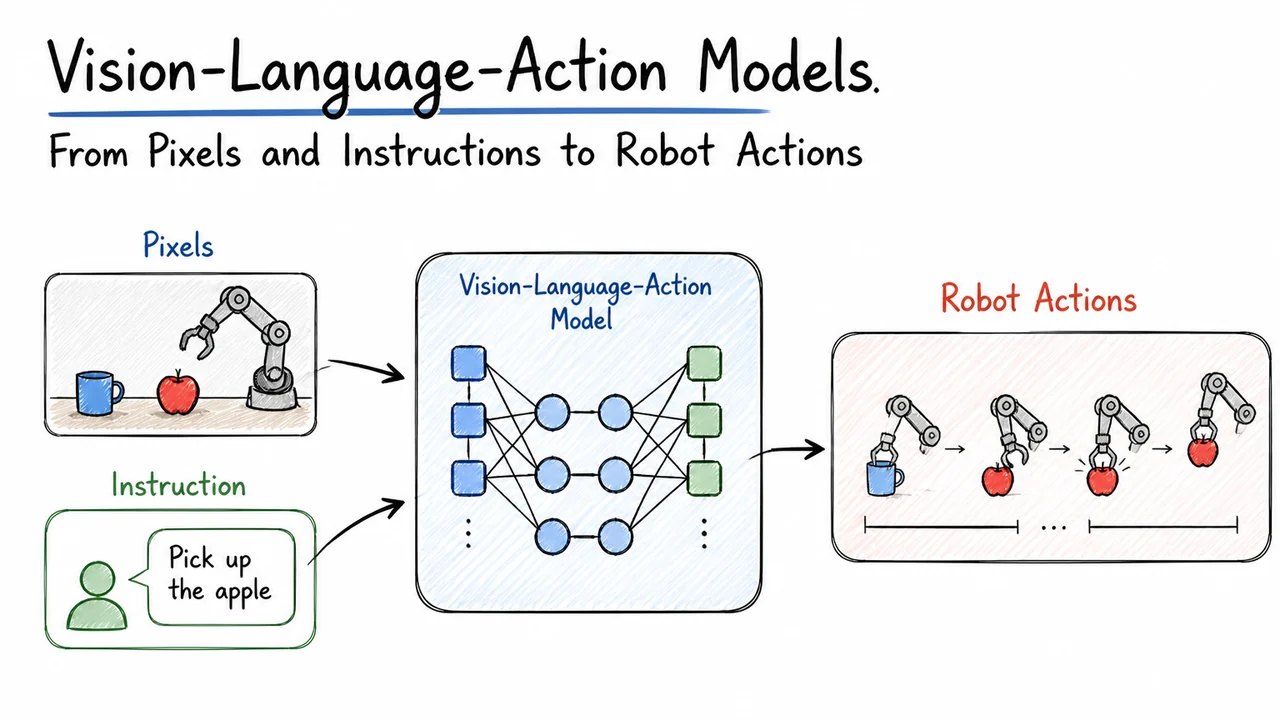
Vision-Language-Action Models: From Pixels and Instructions to Robot Actions
1. Why Vision-Language-Action Models?
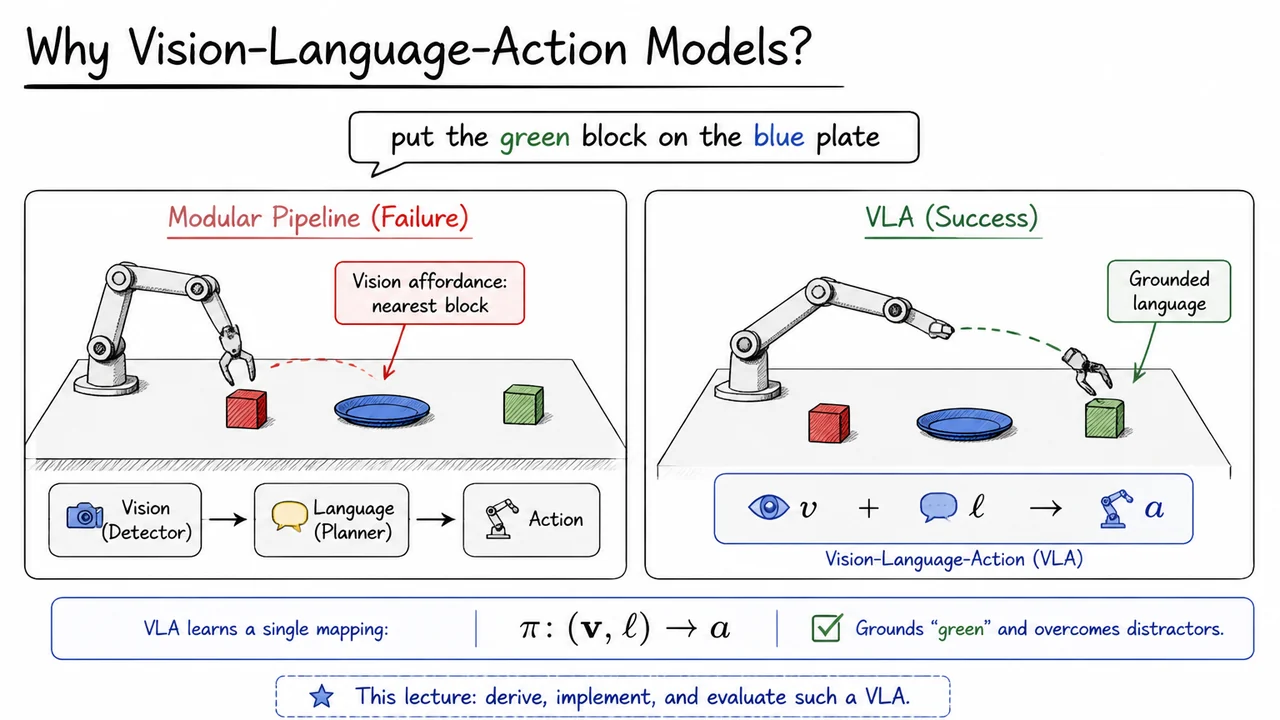
Consider a robot arm hovering over a table cluttered with colorful blocks. The instruction arrives in plain English: “put the green block on the blue plate.” A human would immediately scan the scene, ground the word green in the visual array, and ignore the other blocks. For a robot, this deceptively simple task unmasks a fundamental limitation of naïvely composing separate vision and language modules. If the system first runs an object detector that proposes candidates purely from visual appearance—say, by highlighting all reachable grasp points—the detector has no way to let the phrase “green block” steer its attention. It might rank a nearby red block as the best affordance simply because it is closer or more salient. A downstream language planner, receiving only the detector’s candidate set, then faces an impossible choice: it must map the instruction onto a set of decontextualized visual proposals, none of which correspond to the intended green block. The result is an action that satisfies a visual prior (“grasp the nearest block”) but violates the linguistic constraint—a brittle disconnect between seeing and understanding.
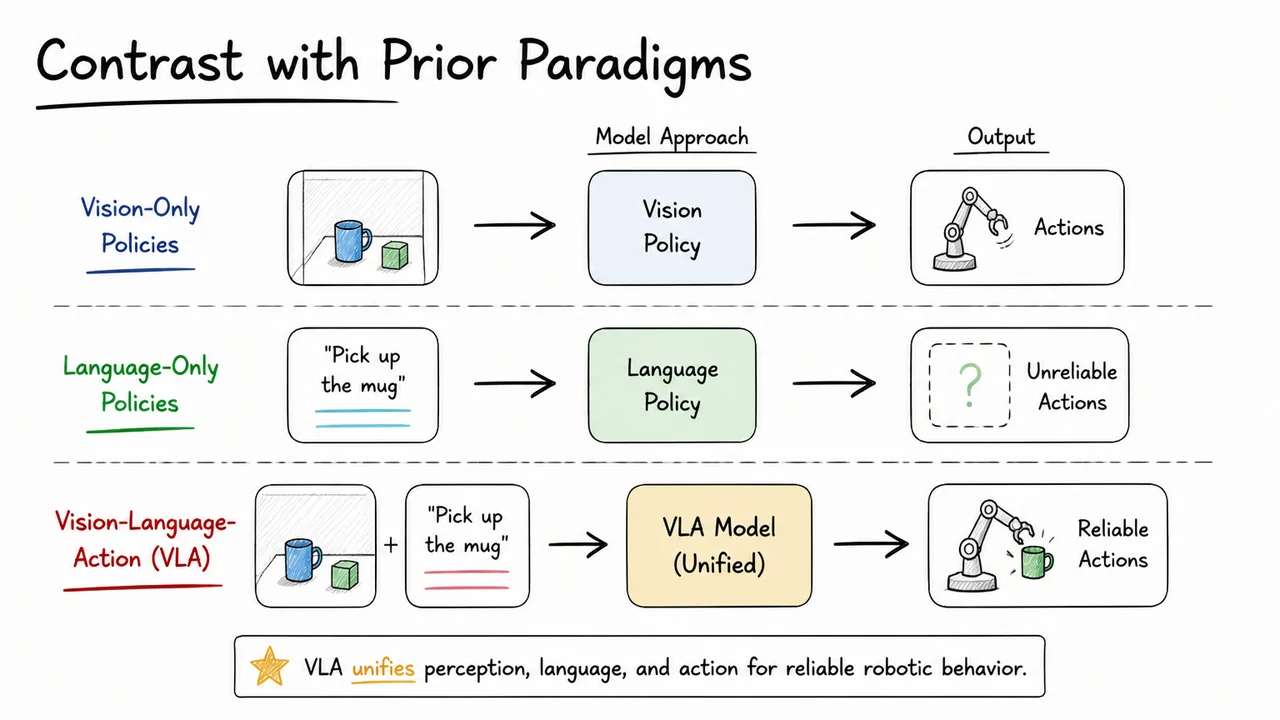
This failure mode is not an artifact of poor engineering; it is structural. A vision-only policy, trained with standard behavioral cloning, learns to map raw pixels directly to actions. When the training data contains varying language instructions, the model must implicitly discover which visual features correlate with which words. In practice, without explicit language conditioning, a visual policy often collapses onto visual shortcuts—object positions, sizes, or motion cues—that are only loosely coupled to the semantic content of an instruction. Conversely, a language-only planner that operates on pre-extracted symbolic descriptions of the scene is hostage to the fidelity of that symbolization. If the scene parser fails to detect or disambiguate the green block because its segmentation model has never been fine-tuned on tabletop clutter, the planner simply cannot issue a correct command. The core insight is that grounded language—the mapping from linguistic tokens to perceptual referents—cannot be reliably achieved when vision and language are processed in isolation and combined late.
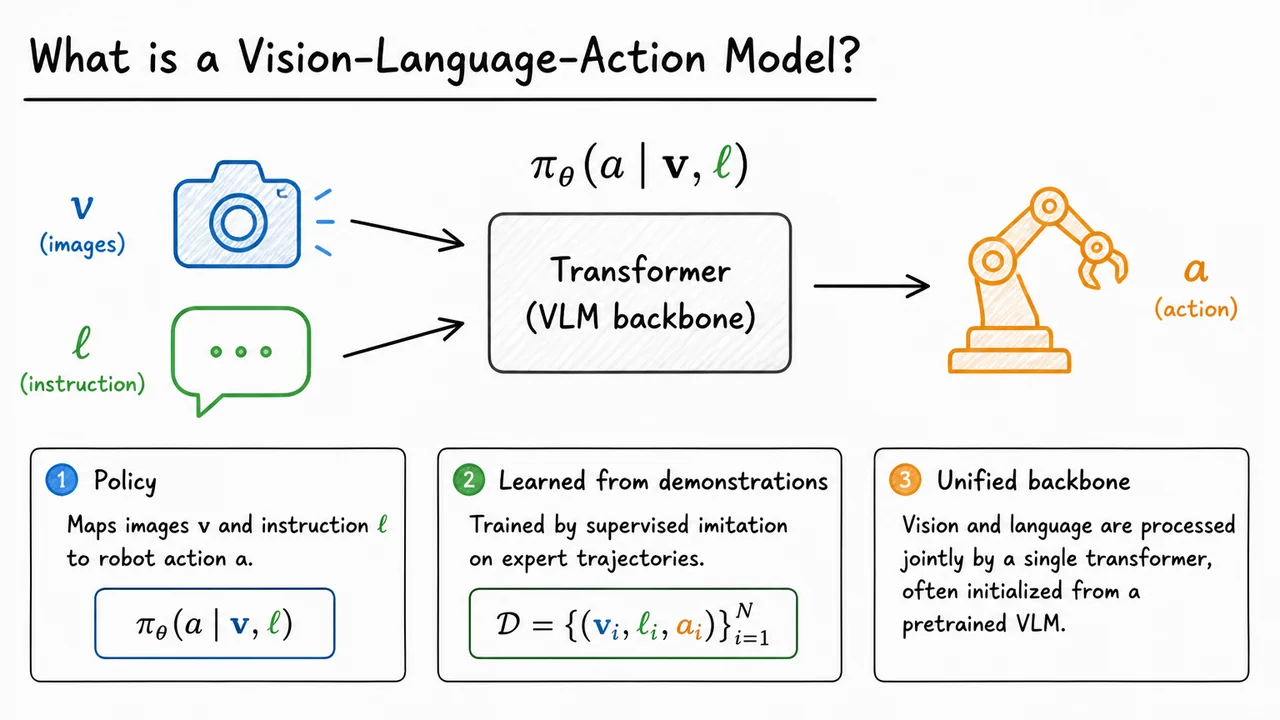
Vision-Language-Action (VLA) models address this by collapsing the modular boundary into a single end-to-end function. Instead of a pipeline that commits to a perceptual abstraction before the language is fully consulted, a VLA model defines a direct mapping:
Here represents the visual observation (e.g., a history of camera images), is the natural language instruction tokenized into a sequence, and denotes the action—such as a 6-DoF end-effector displacement, a gripper command, or a tokenized motion primitive. The model jointly processes both modalities, typically through a transformer backbone that interleaves visual tokens and text tokens, so that every stage of representation learning can condition on both the image content and the instruction. When this single model is trained to maximize the likelihood of expert actions under a supervised imitation objective, it must learn to ground nouns and adjectives directly in pixel space: the latent activation pattern evoked by “green” becomes dynamically bound to the region of the image that contains the green block, even when other blocks are visually more prominent.
The advantage is not simply about accuracy on a single instruction. Because the model fuses vision and language at a low level, it can exhibit emergent reasoning that is difficult to orchestrate with modular pipelines. For instance, if the instruction says “put the block that is the same color as the sky in the painting on the plate,” a VLA can learn to chain visual attributes (the painting) with color references and object selection without explicit symbolic reasoning modules. The system implicitly learns that the phrase “the same color as the sky” modifies a search over objects, and it can back-propagate that linguistic constraint through its visual processing hierarchy. The failure case of the modular pipeline—the red block being grasped because it was nearest—is avoided because the model never commits to a set of “candidate blocks” without already understanding the linguistic goal. Instead, the joint embedding space makes the green block more salient under the phrase “green block,” effectively using language as a top-down attentional modulator for perception.
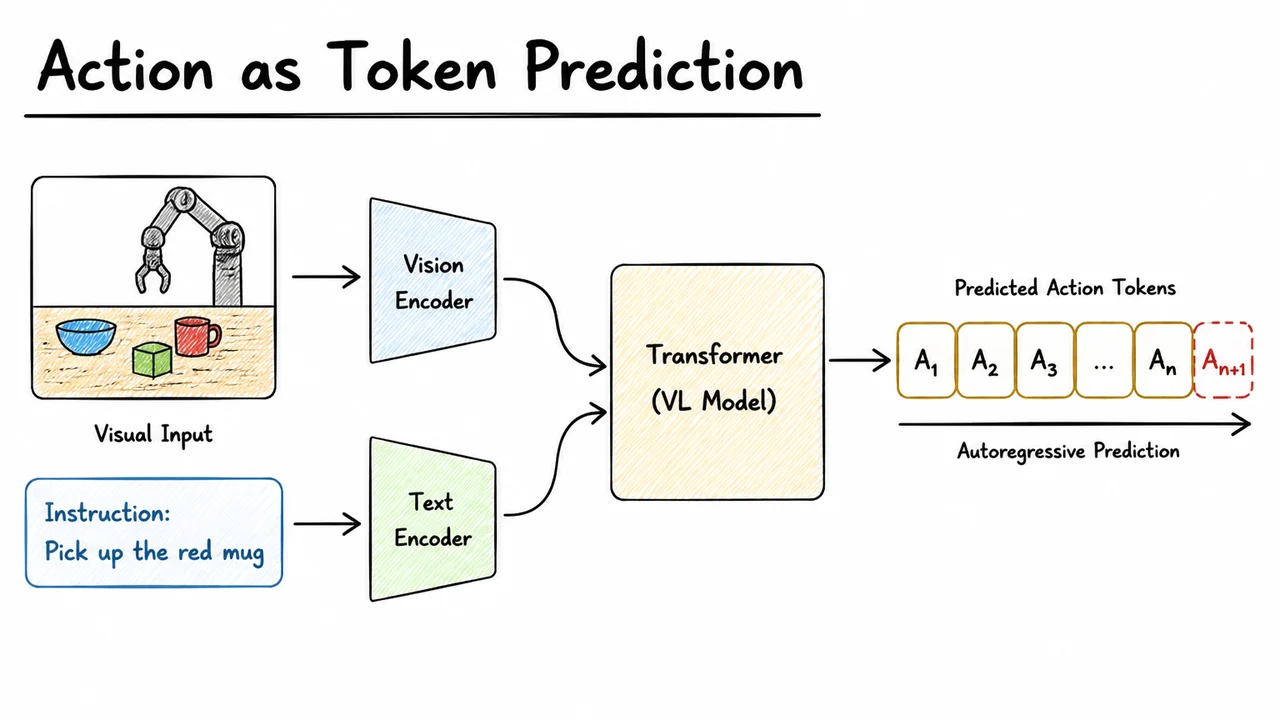
This theoretical elegance translates into concrete design requirements that we will unpack throughout this lecture: a tokenizer that discretizes robot actions so they can be treated with the same autoregressive machinery as language tokens, a multimodal transformer that preserves spatial structure from vision while attending across text tokens, and a training recipe that scales from dozens of demonstrations to internet-scale pre-training. But before diving into these components, it is vital to internalize why the simple, modular alternative breaks so predictably—and why the single-mapping view, , is not a minor tweak but a fundamental shift in how we think about robotic control.
The visual below distills this into a side-by-side comparison that will feel immediately familiar after the discussion above. On the left, a modular pipeline—with a vision-only affordance model—causes the robot arm to reach for the nearest block, which happens to be red, despite the instruction “put the green block on the blue plate.” The annotation “Vision affordance: nearest block” captures the failure: perception ignores the language constraint. On the right, a VLA model processes the same scene and instruction jointly, successfully selecting the green block and moving it toward the blue plate. The labels “Modular Pipeline (Failure)” and “VLA (Success)” set the stage for every subsequent section, reminding us that grounding language in perception is not an optional enhancement—it is the central challenge that a Vision-Language-Action model must solve.