World Action Models are Zero-shot Policies: The DreamZero Approach
1. The Generalization Gap in Robot Manipulation
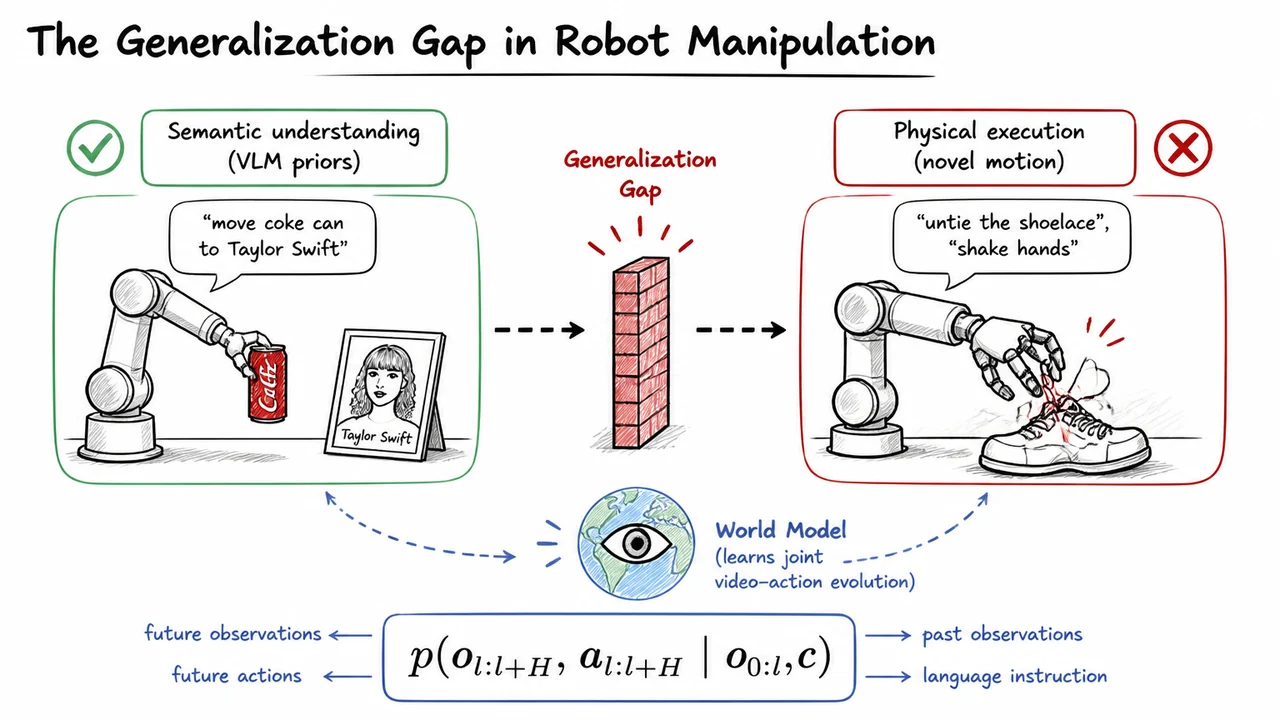
The past few years have seen a dramatic leap in robotic manipulation, driven largely by the integration of large pretrained vision–language models (VLMs) with robot action spaces. Models like RT‑2, GR00T N1, and π0.5 — collectively called Vision‑Language‑Action (VLA) models — encode images and language instructions into a shared semantic space and directly output discrete or continuous action tokens. This marriage of Internet‑scale visual and textual knowledge with embodiment seems to unlock a host of tasks that were previously out of reach. A robot can now be told “move the coke can to Taylor Swift” and, using its VLM priors, locate the can, recognize the iconic singer’s face on a poster, and execute a reaching‑and‑placing trajectory. The success here hinges on semantic understanding: language specifies what to manipulate and where to place it, and the robot’s pre‑trained visual backbone supplies the object recognition, spatial reasoning, and scene grounding necessary to translate that command into a standard sequence of grasps and moves.
Yet when the same robot is asked to untie a shoelace, shake hands, or peel a fruit, it flounders. The VLA model, despite having seen millions of images of shoelaces and hands in its pretraining data, fails catastrophically at the physical execution. Its fingers misalign, forces are misjudged, and the motion looks nothing like the intended skill. The root cause is subtle but fundamental: semantic priors do not equal physical execution competence. Language instructions that describe how to move — the fine‑grained geometry of deformation, the interplay of contact forces, the rhythm of a coordinated bimanual gesture — probe a part of the skill space that is almost entirely absent from typical robot datasets. Those datasets consist overwhelmingly of rigid‑body tabletop pick‑and‑place tasks, where the mapping from language to action can be learned with high‑level motion primitives. They rarely contain the low‑level motor patterns for dexterous, contact‑rich, or dynamic motions. Consequently, a VLA model’s internal representation of “untie” is a linguistic concept divorced from the physical sequence of forces and finger trajectories that would actually untie a knot.
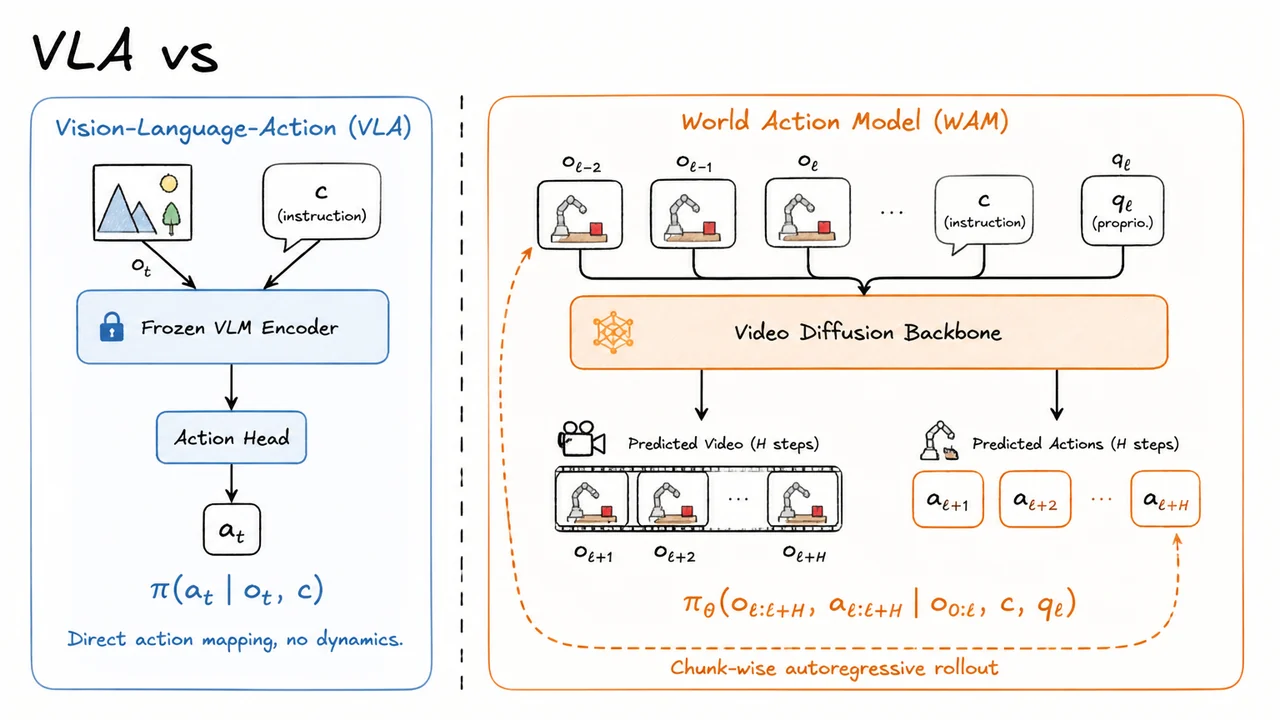
This gap is not merely a matter of data scale — it is an architectural misalignment. A VLA model, at its core, learns a function from (observation, instruction) to the next action (or action chunk). During training, it sees action sequences that belong to a narrow support in the space of all possible robot behaviors. At test time, when the instruction demands a skill outside that support, the model has no mechanism to imagine how the world would evolve under its own actions. It can hallucinate a plausible semantic plan (“grasp the lace, pull it…”) but its action generator, conditioned only on the current frame and a language embedding, cannot extrapolate to the unfamiliar sensorimotor consequences. The failure is one of dynamics generalization: the model has no internal representation of , so it cannot assess whether its predicted actions will actually bring about the desired visual outcome.
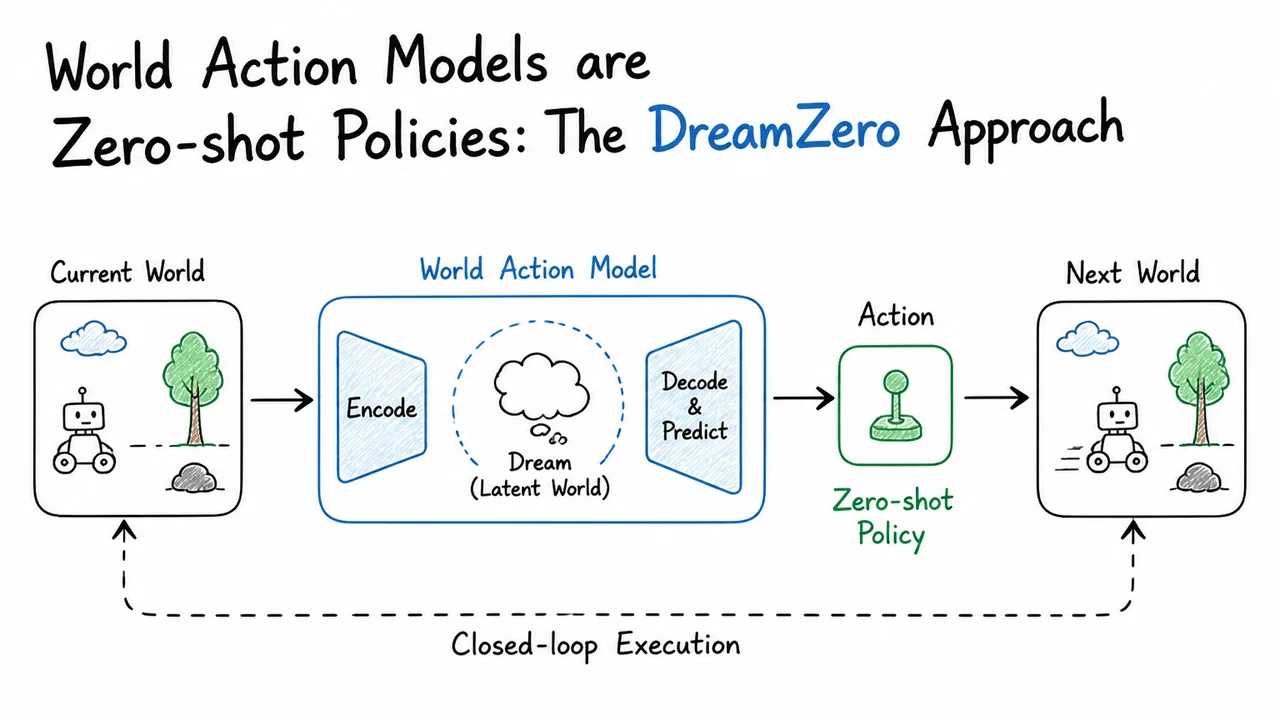
The key insight that motivates the DreamZero approach is therefore as crisp as it is urgent: a model that only directly maps language to actions cannot extrapolate to novel physical dynamics. To close this generalization gap, we need a world model — a generative system that learns the joint evolution of video observations and robot actions. The formal target is the full conditional distribution
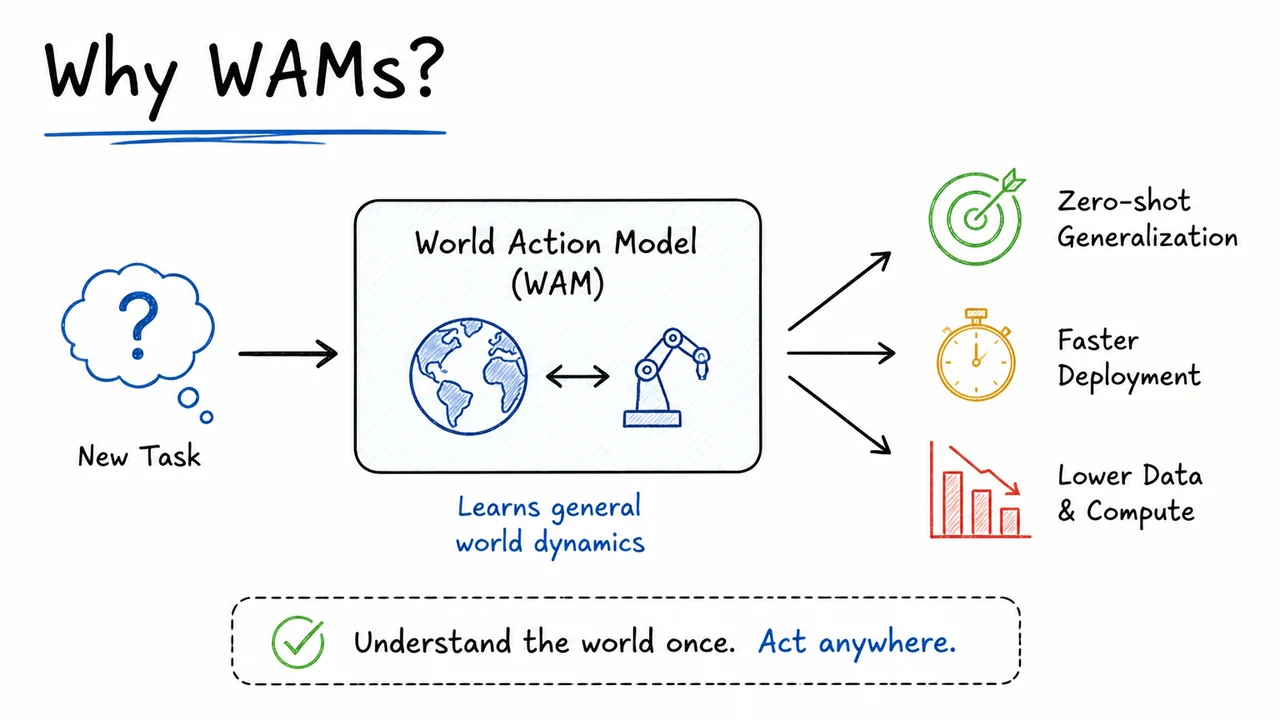
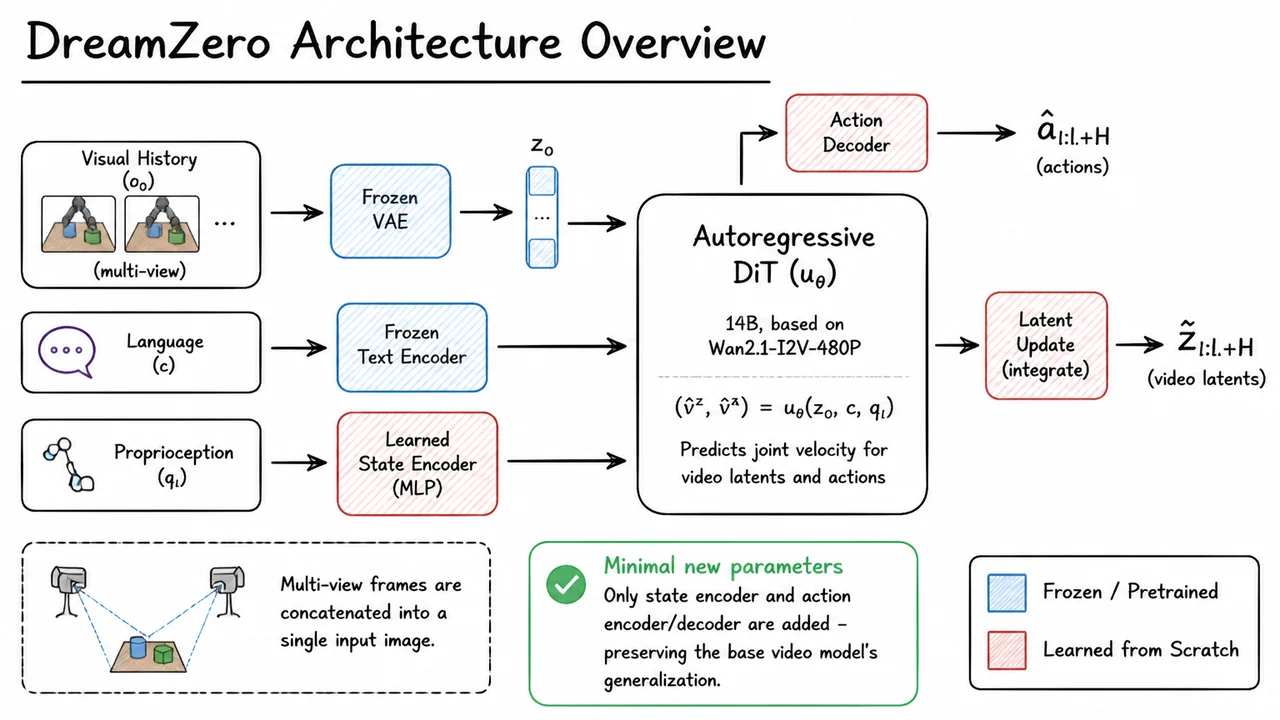
where is a short history of observed frames, is a language command (or more generally a task specification), and the model is asked to produce a future video clip of length together with the corresponding action trajectory that would realize it. By training a model to generate videos conditioned on actions — and, symmetrically, to infer the actions that connect two frames — the system internalizes the physical cause‑effect relationships of the world. Once the model can “see” in imagination the result of an action sequence, it can be used as a zero‑shot policy: given a command and the current observation, we sample an action trajectory from the conditional distribution (for instance, by fixing the first frame and allowing the model to autoregressively hallucinate the future video and actions). The resulting actions can then be executed on the real robot, even if that exact motion was never seen during robot training, because the world model has acquired a transferable understanding of how objects and hands interact from large‑scale video data — just as language models acquire reasoning from text.
The visual below brings this entire narrative into a single, compact diagram. The left panel depicts a clear VLA success: a robot arm holding a Coke can and placing it beside a photo of Taylor Swift, with a green check mark labeled Semantic understanding (VLM priors). The right panel shows the bitter failure: a tangled, misaligned attempt to untie a shoelace, marked with a red cross and Physical execution (novel motion). A dashed arrow intended to connect these two regimes is broken by a prominent red barrier labeled “Generalization Gap.” Behind that barrier, a stylized world‑model icon — a globe with an eye — suggests the missing piece. At the bottom of the slide, the central equation sits as the mathematical encapsulation of what must be learned. The diagram thus functions as a visual mnemonic: language‑to‑action mappings succeed when the instruction stays within the data‑supported “semantic” region, but they shatter when novel motion physics is required; a world action model that jointly generates video and action sequences promises to bridge that chasm by grounding language in a generative dynamics of perception and action.