Library
Search the public knowledge base.
Curated paths
Transformer Foundations
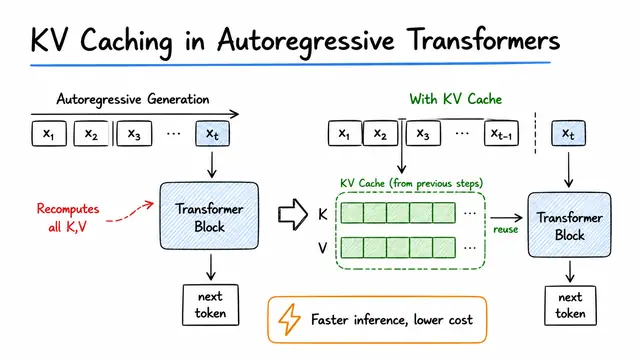
KV Caching in Autoregressive Transformers
1 article>Generative Models
Diffusion, flow matching, VAEs, and beyond.
0 articles>Reinforcement Learning Path
Foundations to advanced RL algorithms.
0 articles>Math for Deep Learning
Linear algebra, low-rank methods, and optimization.
0 articles>3 results