Library
Search the public knowledge base.
Curated paths
Transformer Foundations
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
1 article>Generative Models
Diffusion, flow matching, VAEs, and beyond.
0 articles>Reinforcement Learning Path
Reinforcement Learning for Large Language Models: Group Relative Policy Optimization (GRPO)
1 article>Math for Deep Learning
Linear algebra, low-rank methods, and optimization.
0 articles>4 results
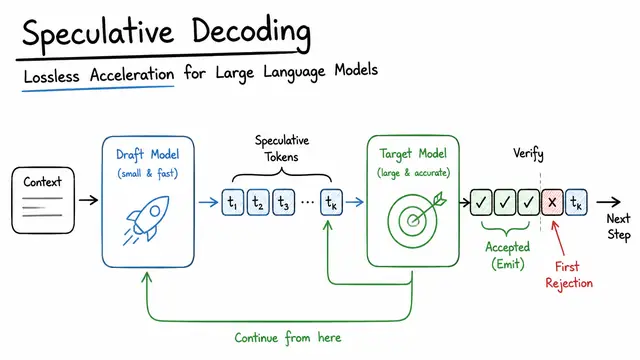
Speculative Decoding: Lossless Acceleration for Large Language Models
Speculative Decoding in LLM's
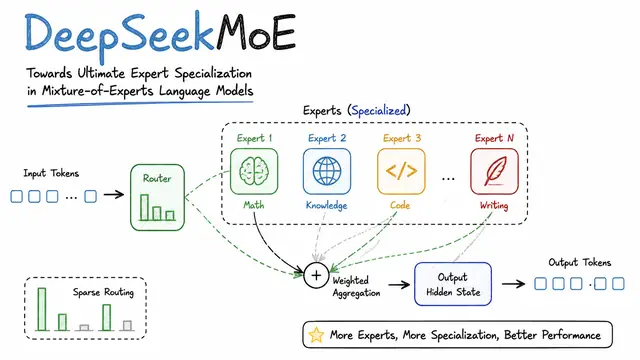
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
MoE architecture for efficient LLM scaling via specialized experts
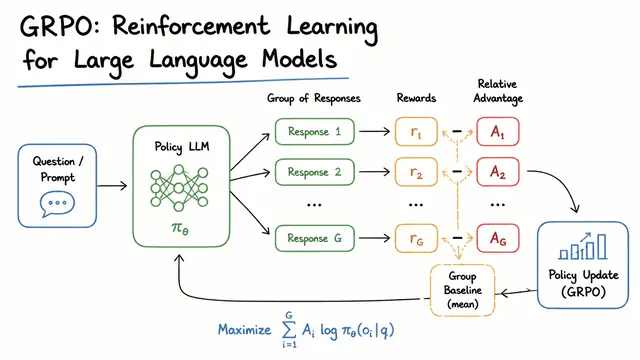
Reinforcement Learning for Large Language Models: Group Relative Policy Optimization (GRPO)
GRPO and RL for LLM's
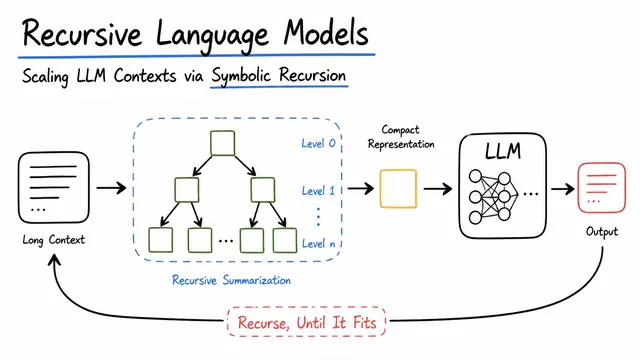
Recursive Language Models: Scaling LLM Contexts via Symbolic Recursion
Language models that recursively refine or compose intermediate reasoning/representations.