Library
Search the public knowledge base.
Curated paths
Transformer Foundations
KV Caching in Autoregressive Transformers
1 article>Generative Models
Diffusion Models and Flow Matching: From Score-Based Diffusion to Continuous Normalizing Flows
1 article>Reinforcement Learning Path
HIL-SERL: Human-in-the-Loop Sample-Efficient Robotic Reinforcement Learning for Dexterous Manipulation
1 article>Math for Deep Learning
LoRA Fine-Tuning: Low-Rank Adaptation of Large Neural Networks
1 article>17 results
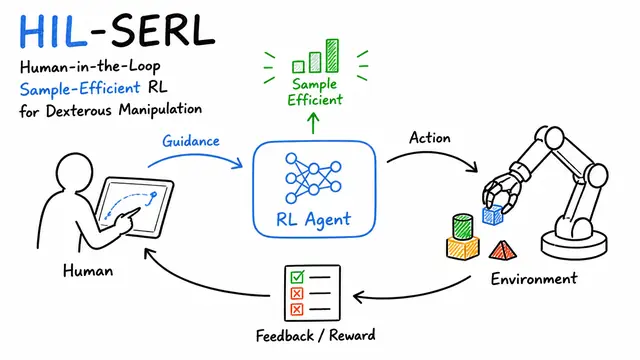
HIL-SERL: Human-in-the-Loop Sample-Efficient Robotic Reinforcement Learning for Dexterous Manipulation
A diagram-rich generated explanation from the public library.
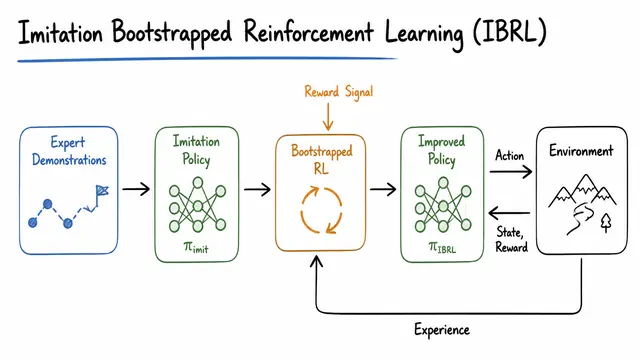
Imitation Bootstrapped Reinforcement Learning (IBRL)
A diagram-rich generated explanation from the public library.
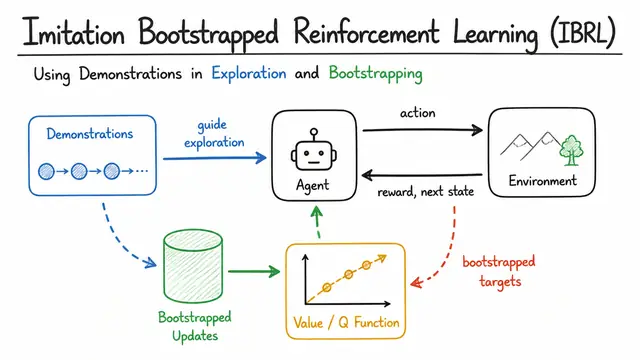
Imitation Bootstrapped Reinforcement Learning (IBRL): Using Demonstrations in Exploration and Bootstrapping
A diagram-rich generated explanation from the public library.
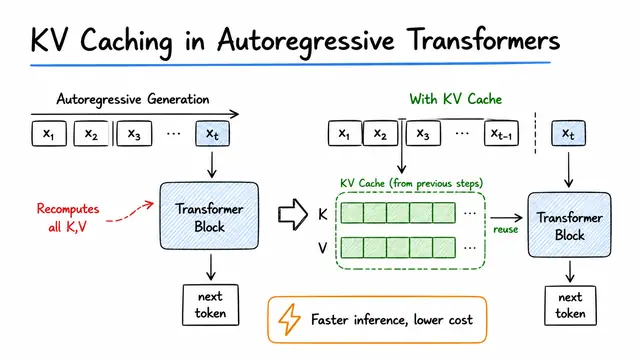
KV Caching in Autoregressive Transformers
KV Caching
Odysseus: Stable RL Training of VLMs for Long-Horizon Game Decision-Making
A diagram-rich generated explanation from the public library.
ECHO: Turning Terminal Feedback into Dense Supervision for Agent RL
A diagram-rich generated explanation from the public library.
Vision-Language-Action Models: From Pixels and Instructions to Robot Actions
VLA (Vision Language Action Models)
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
MoE architecture for efficient LLM scaling via specialized experts
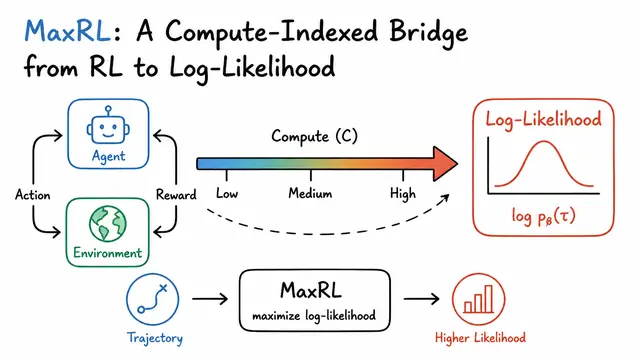
Maximum Likelihood Reinforcement Learning (MaxRL): A Compute-Indexed Bridge from RL to Log-Likelihood
RL framework that approximates maximum likelihood for binary-outcome tasks.
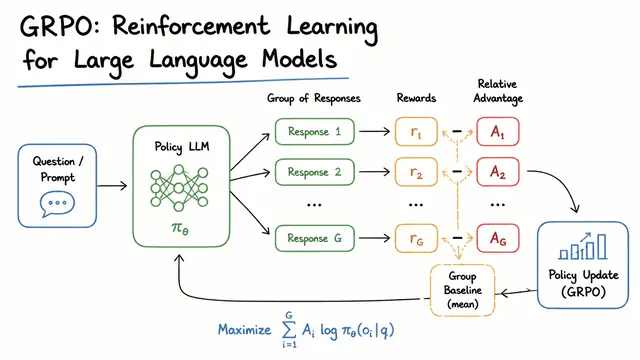
Reinforcement Learning for Large Language Models: Group Relative Policy Optimization (GRPO)
GRPO and RL for LLM's
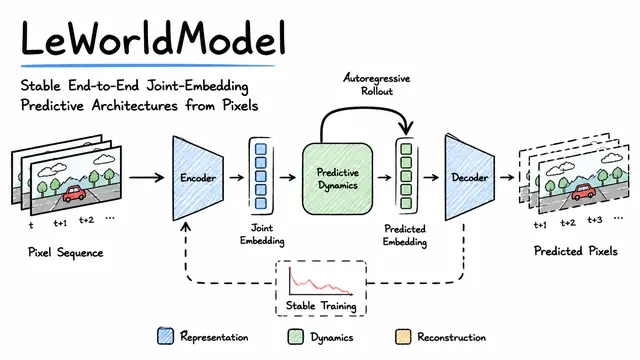
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architectures from Pixels
Stable JEPA-based world model that learns and plans from raw pixels.
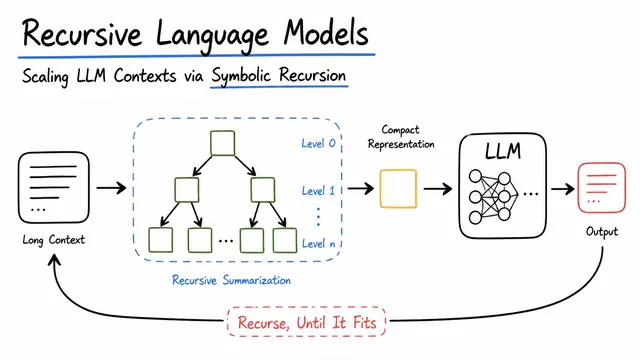
Recursive Language Models: Scaling LLM Contexts via Symbolic Recursion
Language models that recursively refine or compose intermediate reasoning/representations.
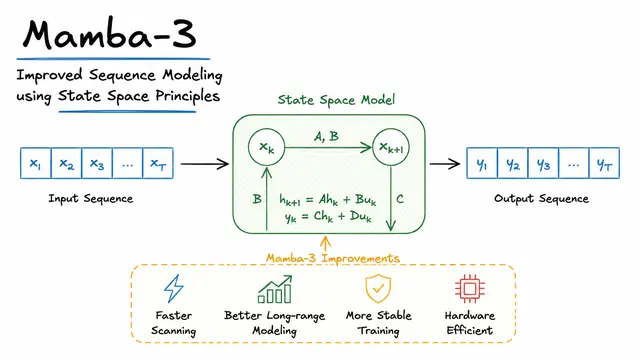
Mamba-3: Improved Sequence Modeling using State Space Principles
Mamba-3: Improved Sequence Modeling using State Space Principles
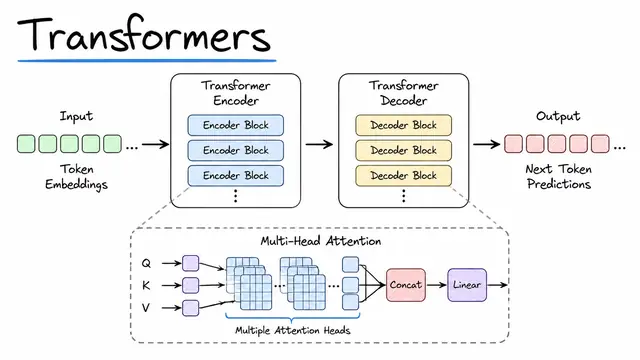
Transformers: Attention, Architecture, Training, and Scaling
Transformers
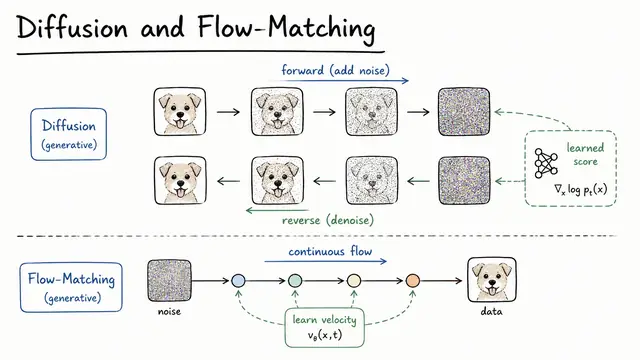
Diffusion Models and Flow Matching: From Score-Based Diffusion to Continuous Normalizing Flows
Diffusion and flow-matching
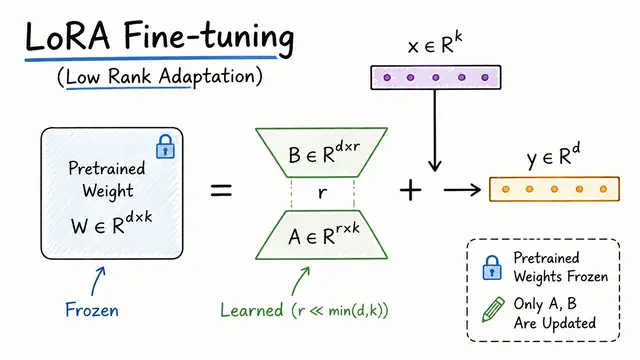
LoRA Fine-Tuning: Low-Rank Adaptation of Large Neural Networks
LORA Fine-tuning (Low rank adaption)
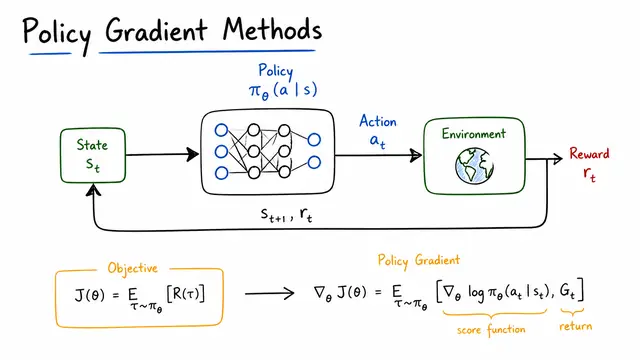
Policy Gradient Methods
policy gradient methods